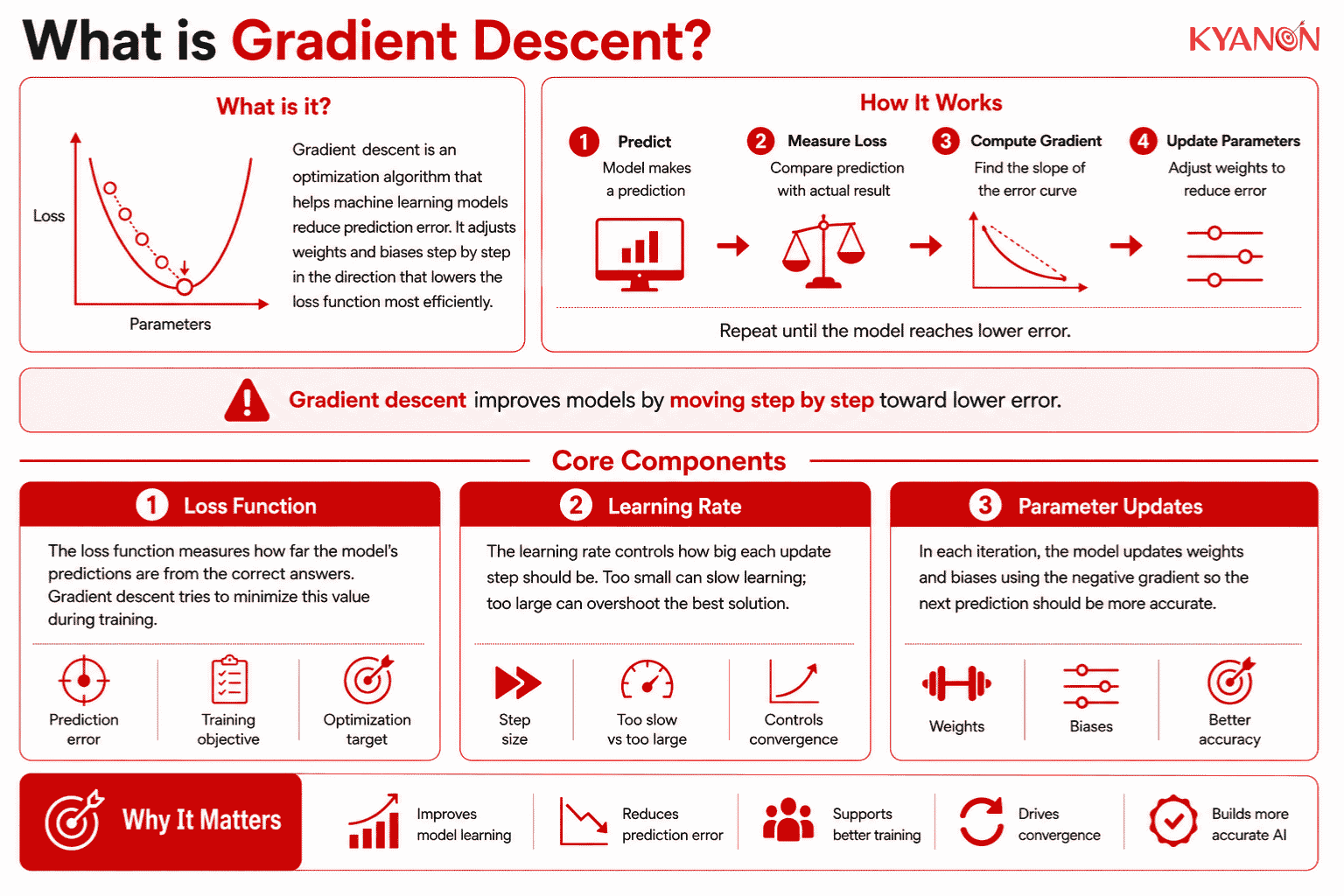
What is Gradient Descent?
Gradient descent is a mathematical optimization algorithm used in machine learning to iteratively adjust model parameters, such as weights and biases, in the direction that most steeply reduces the overall prediction error. By calculating the negative gradient of the loss function, it determines the most mathematically efficient path for a neural network to learn from training data.
How Gradient Descent Works
The algorithm operates through a continuous feedback loop where it evaluates a model’s current predictions against actual data, measures the magnitude of the error, and updates internal parameters to lower that error in the next iteration. This iterative adjustment relies on partial derivatives to calculate the exact slope of the error curve at any given point, ensuring the model moves downhill toward maximum accuracy.
Loss Function
The loss function is a mathematical metric that quantifies the difference between a model’s predicted outputs and the actual target values. It provides the objective numerical baseline that the gradient descent algorithm actively seeks to minimize during the training phase.
Learning Rate
The learning rate is a tunable hyperparameter that dictates the proportional step size the algorithm takes when moving toward the minimum error. A critically calibrated learning rate prevents the model from either converging too slowly or overshooting the optimal solution entirely.
Parameter Updates
During each training cycle, internal model weights are adjusted by subtracting a fraction of the calculated gradient, mathematically forcing the algorithm into a state of higher predictive accuracy.
Types of Gradient Descent
| Type | How it works | Best for | Key trade-off |
|---|---|---|---|
| Batch Gradient Descent | Uses the full dataset for each update | Smaller datasets where stability matters | Accurate but slow and costly for large datasets |
| Stochastic Gradient Descent, or SGD | Uses one random training example per update | Faster experimentation | Fast but noisy and unstable |
| Mini-Batch Gradient Descent | Uses small batches of data per update | Modern neural network training | Balances speed, stability, and GPU efficiency |
Mini-batch gradient descent is the most widely used approach in modern AI training because it improves hardware utilization while keeping training more stable than pure SGD.
Gradient Descent vs Backpropagation
Gradient descent and backpropagation are closely related, but they are not the same.
Gradient descent updates model parameters to reduce loss. Backpropagation calculates the gradients needed for those updates.
| Dimension | Gradient Descent | Backpropagation |
| Core role | Updates model parameters | Calculates gradients across model layers |
| Main question answered | “How should the model change?” | “Which parameters caused the error?” |
| Position in training loop | Runs after gradients are calculated | Runs before parameter updates |
| Business relevance | Affects training efficiency, compute cost, and model performance | Makes complex neural network training feasible |
| Key risk | Poor learning rate can cause slow or unstable training | Weak gradient signals can reduce model quality |
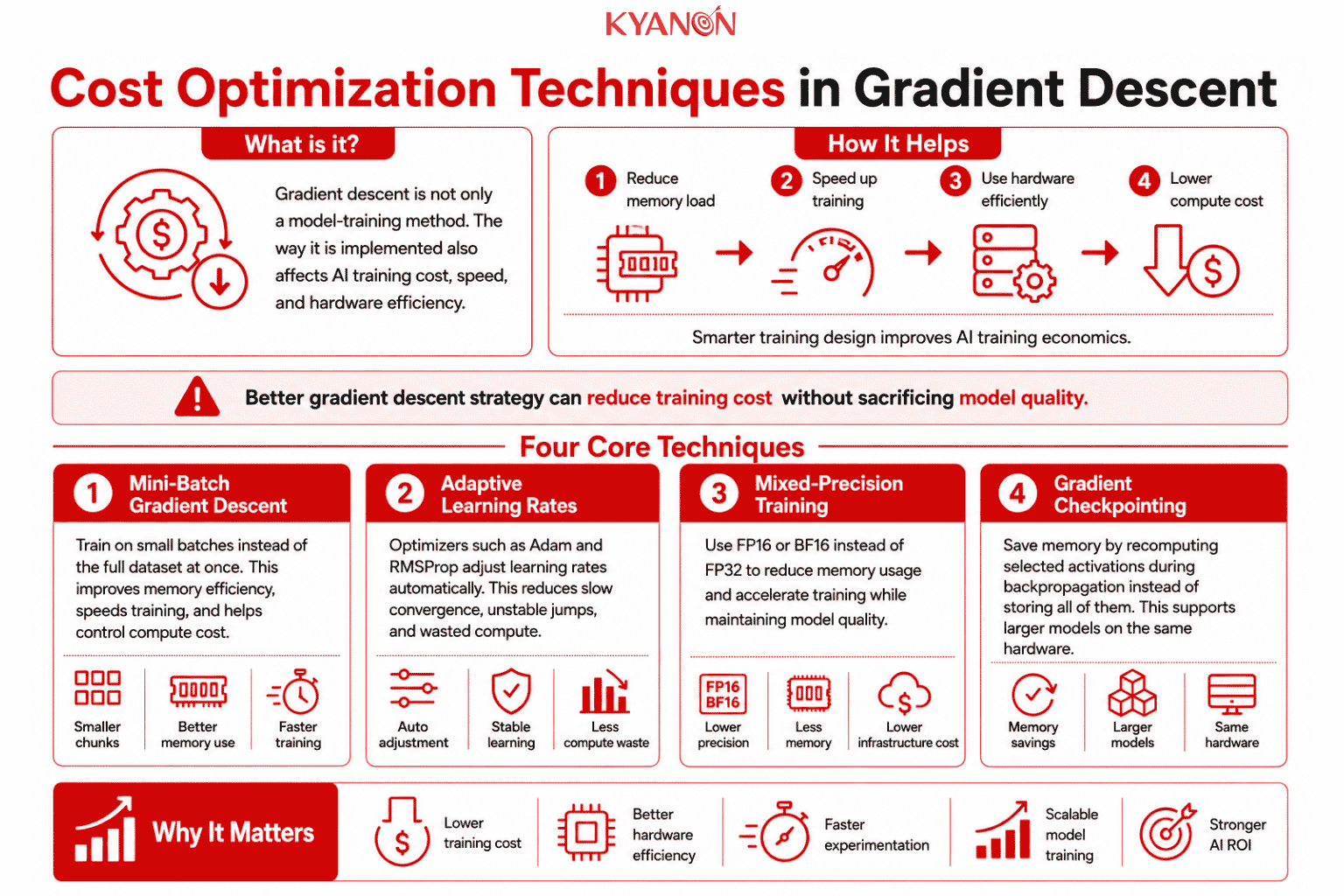
Cost Optimization Techniques in Gradient Descent
Gradient descent is not only a technical concept. It also affects AI training cost.
Mini-Batch Gradient Descent
Mini-batch training processes data in smaller chunks instead of using the full dataset at once. This improves GPU and TPU memory efficiency, reduces training time, and helps control compute cost.
Adaptive Learning Rates
Optimizers such as Adam and RMSProp adjust the learning rate automatically during training. This helps models avoid slow convergence, unstable jumps, and unnecessary compute waste.
Mixed-Precision Training
Mixed-precision training uses lower-precision formats such as FP16 or BF16 instead of FP32. This can reduce memory usage, accelerate training, and lower cloud infrastructure cost while maintaining model quality.
Gradient Checkpointing
Gradient checkpointing saves memory by recomputing selected intermediate activations during backpropagation instead of storing all of them. This allows teams to train larger models or use larger batch sizes on the same hardware.
Key Tuning Factors
Learning Rate Schedule
A learning rate schedule changes the learning rate during training.
Common strategies include:
- Warm-up: starts with a small learning rate and increases gradually.
- Decay: reduces the learning rate as the model gets closer to minimum error.
This helps stabilize training and prevent costly oscillations.
Momentum
Momentum uses previous gradient updates to help the model move faster through flat areas and reduce training noise. It can improve convergence speed and reduce unnecessary training cycles.
Batch Size
Batch size affects memory usage, training stability, and infrastructure cost. Larger batches can improve hardware efficiency, while smaller batches may improve generalization but create noisier updates.
Optimizer Choice
Different optimizers behave differently. SGD, Adam, RMSProp, and other adaptive optimizers should be selected based on model type, dataset size, training budget, and performance targets.
Common Challenges
Local Minima
In complex AI models, gradient descent may settle into a local minimum instead of finding the best possible solution. This is why architecture, initialization, optimizer choice, and data quality matter.
Saddle Points
Saddle points are flat regions where training can slow down even though the model has not reached the best solution. Momentum and adaptive optimizers can help reduce this issue.
Vanishing and Exploding Gradients
In deep neural networks, gradients can become too small or too large.
Vanishing gradients can stop learning. Exploding gradients can make training unstable. Techniques such as normalization, careful initialization, gradient clipping, and adaptive optimizers can help reduce these risks.
Overfitting
Gradient descent minimizes training loss, but it does not automatically guarantee strong performance on unseen data. Overfitting control requires validation sets, regularization, early stopping, dropout, and data quality checks.
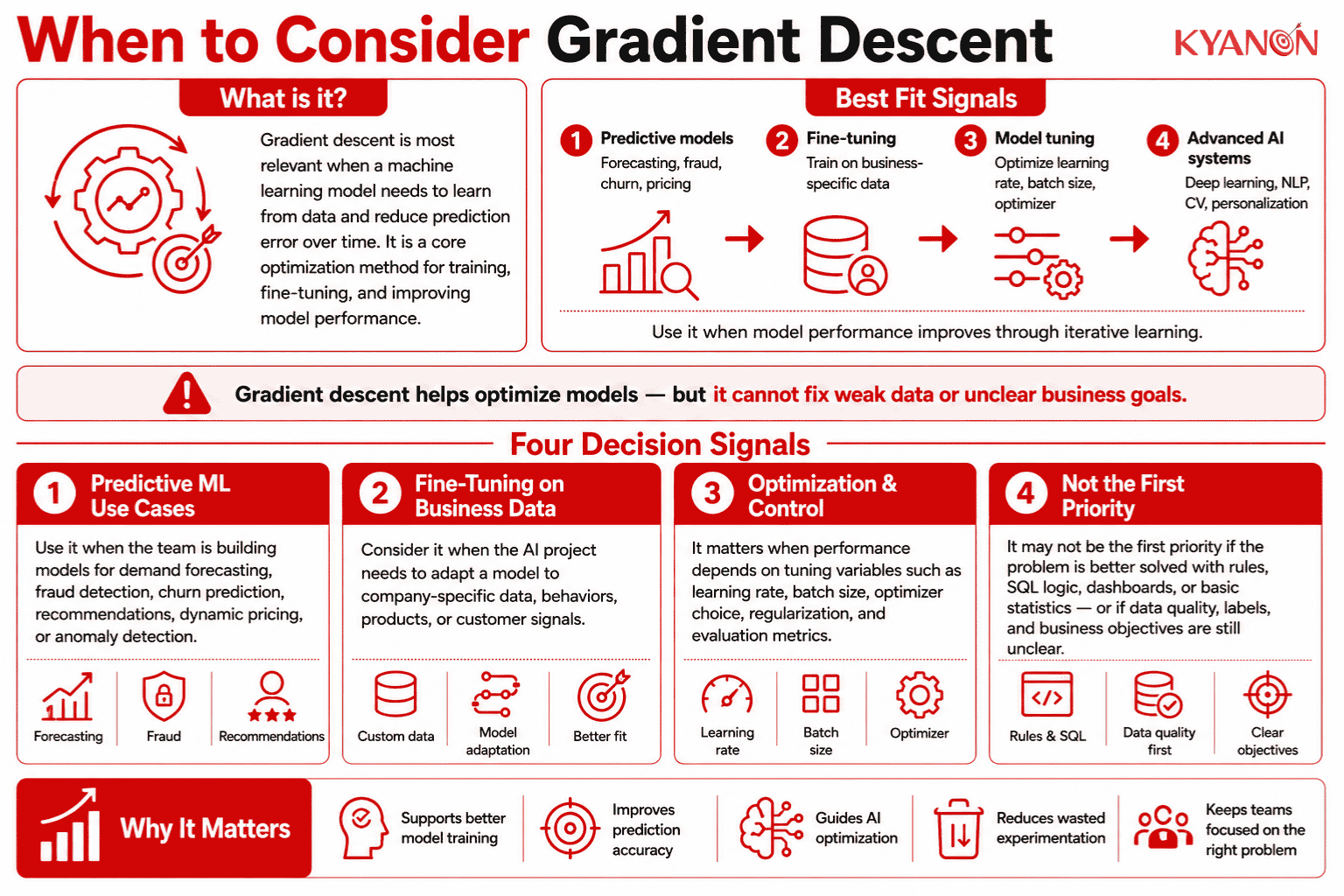
When to Consider Gradient Descent
Gradient descent is relevant when an organization is training, fine-tuning, or optimizing machine learning models that need to minimize prediction error over time.
Consider gradient descent if:
- Your team is building predictive models for demand forecasting, fraud detection, churn prediction, dynamic pricing, recommendations, or anomaly detection.
- Your AI project requires fine-tuning on business-specific data.
- Your model performance depends on learning rate, batch size, optimizer choice, regularization, and evaluation metrics.
- Your roadmap includes neural networks, deep learning, computer vision, NLP, or personalization systems.
Gradient descent may not be the first priority if:
- The business problem can be solved with rules, SQL logic, dashboards, or basic statistics.
- The main issue is poor data quality, unclear labels, or weak feature design.
- The team has not defined acceptable error thresholds, monitoring metrics, retraining triggers, or ownership for model behavior in production.
Gradient descent can optimize a model, but it cannot fix unreliable data or unclear business objectives.
Why Gradient Descent Matters for Enterprise AI
Gradient descent matters because it directly affects how efficiently AI models learn, how much compute budget is consumed, and how reliable the final model becomes.
For example, an e-commerce platform training a recommendation model uses gradient-based optimization to reduce the gap between predicted customer preferences and real customer behavior.
In this context, gradient descent affects:
- Recommendation quality
- Personalization performance
- Training cost
- Experimentation speed
- Infrastructure efficiency
- Time-to-market for AI features
Monitoring Training Cost
To control AI training cost, teams should monitor both model performance and compute usage.
Useful practices include:
- Track loss, validation error, and training time.
- Compare optimizer performance across experiments.
- Monitor GPU or TPU utilization.
- Use experiment tracking tools such as MLflow or Weights & Biases.
- Stop redundant training runs early when performance does not improve.
- Document learning rate, batch size, optimizer, and model configuration for reproducibility.
Common Misconceptions
“Gradient descent always finds the best model.”
Reality: Gradient descent does not always guarantee the global minimum in complex training landscapes. Model architecture, data quality, initialization, optimizer choice, and learning rate all affect the final result.
“A higher learning rate always means faster training.”
Reality: A high learning rate can speed up early training but may also cause instability, overshooting, or wasted compute cycles.
“Gradient descent prevents overfitting.”
Reality: Gradient descent reduces training loss, but generalization requires validation, regularization, early stopping, and monitoring.
“Batch gradient descent is always better.”
Reality: Batch gradient descent can be too slow and expensive for large datasets. Mini-batch methods are usually more practical for modern AI systems.
“Gradient descent is the only optimization method.”
Reality: Gradient descent is foundational, but production ML teams often use variants and adaptive optimizers such as SGD, Adam, and RMSProp.

How Kyanon Digital Applies Gradient Descent
Kyanon Digital applies gradient descent as part of machine learning model training, fine-tuning, optimization, deployment, and monitoring for enterprise AI systems across Vietnam, Singapore, Malaysia, Thailand, ANZ, the US, and Nordic Europe.
In practical delivery, this includes:
- Selecting suitable model architectures
- Defining loss functions aligned with business goals
- Tuning learning rates, optimizers, and batch sizes
- Validating model performance against business metrics
- Reducing unnecessary training costs
- Deploying optimized models into enterprise workflows
- Monitoring model behavior after deployment
Kyanon Digital’s machine learning services cover custom ML solutions, predictive analytics, AI-powered automation, model training and fine-tuning, model deployment, optimization, and continuous monitoring.
Explore our Machine Learning development services.







")




 Create project brief with AI
Create project brief with AI