What is Vectorization?
Vectorization is the computational process of converting text, images, or other unstructured data formats into numerical arrays, known as vectors, so that machine learning models can process and analyze them mathematically. This transformation acts as the foundational translation layer between human-readable information and machine-readable data structures.
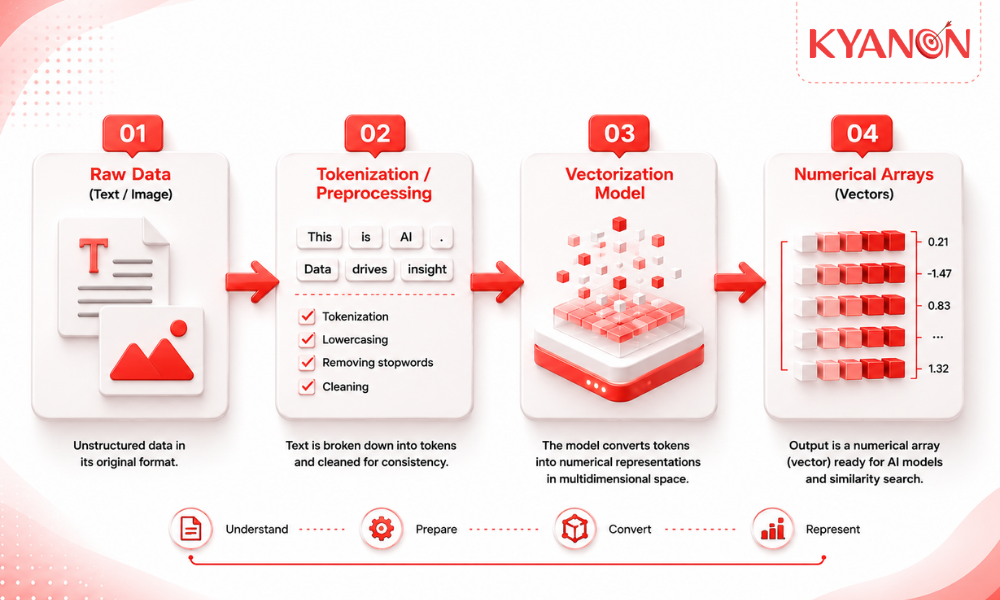
How Vectorization works
The vectorization process maps categorical or textual information into a multidimensional numerical space, allowing algorithms to execute algebraic operations to determine the exact relationships between distinct data points. By assigning coordinate values to raw data, systems can calculate similarities and patterns at a scale impossible for manual processing.
Raw Unstructured Data → Ingestion & Parsing (OCR, file extraction, data cleaning) → Chunking (breaking content into semantic segments) → Embedding Generation (models calculate numerical vectors) → Database Indexing (storage inside vector databases)
Data parsing and preprocessing
Before conversion, raw data must be cleaned and standardized. For text, this involves breaking sentences down into smaller units (tokenization) and removing irrelevant characters, ensuring the mathematical conversion operates on clean, consistent inputs.
Numerical mapping
Algorithms, ranging from foundational frequency-based methods like TF-IDF to complex neural networks, assign specific numeric values to the preprocessed data. This step dictates how accurately the resulting numbers reflect the original information’s attributes.
Dimensional output generation
The final output is a continuous array of numbers (a vector). The size and structure of this array depend on the chosen methodology, defining how the data will be stored and queried in downstream systems like vector search engines.
Vectorization vs. Embedding
Both terms deal with numerical representation, but they represent different levels of semantic complexity in data science.
|
Dimension |
Vectorization (General) | Embedding |
| Scope | Broad (Any conversion to numbers) | Specific (Subset of vectorization) |
| Semantic Understanding | Low to None (Often frequency-based) | High (Captures context and relationships) |
| Dimensionality | Often high and sparse | Usually lower and denser |
| Creation Method | Rule-based algorithms or simple models | Deep learning neural networks |
| Primary Use Case | Basic classification, statistical ML |
LLMs, semantic search, RAG |
When to consider vectorization
Consider vectorization if:
- Your organization holds large volumes of unstructured data (PDFs, call logs, product images) that need to be categorized or searched mathematically.
- You are building the data preparation pipeline for an enterprise Retrieval-Augmented Generation (RAG) system.
- Your engineering team needs to implement rapid duplicate tracking or anomaly detection across millions of transactional records without deploying heavy language models.
It may not be the right priority if:
- Your analytics requirements depend entirely on structured, tabular data housed within a standard SQL relational database, where arithmetic logic alone is sufficient.
Why Vectorization matters for AI infrastructure
For technology leaders, vectorization is the critical bottleneck governing the accuracy and speed of any AI deployment; poorly converted data fundamentally limits the return on investment for subsequent model training and infrastructure spend.
Supporting evidence
According to a 2024 report by McKinsey, unstructured data accounts for approximately 90% of all enterprise data. Organizations must utilize systematic conversion methods to extract operational value from this vast resource. A financial services firm in Singapore optimized its vectorization pipeline for internal compliance documents, reducing its semantic search retrieval latency by 40% and cutting total compute costs associated with its RAG architecture. This demonstrates how rigorous data preparation translates directly to lower Total Cost of Ownership (TCO).
Common misconceptions
“Vectorizing data automatically fixes output quality for RAG systems.”
Reality: Vectorization simply converts the data you provide into numbers; it does not correct poor data logic. If the initial data structure or chunking strategy is poor, the vector search will still fail to retrieve relevant information.
“Vector databases and vector similarity are only for Large Language Models.”
Reality: Vector similarity is widely used for anomaly detection, duplicate tracking, and recommendation engines without involving an LLM at all. It is a foundational mathematical approach, not exclusively an AI generative tool.
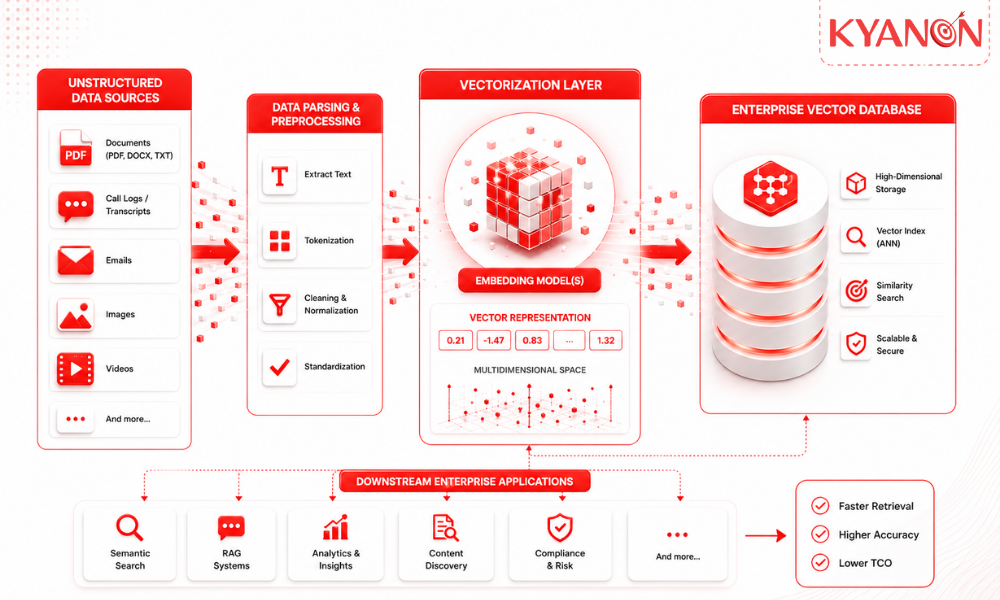
How Kyanon Digital applies cectorization
Kyanon Digital applies vectorization as a foundational data preparation step in enterprise AI builds across Southeast Asia and ANZ. Our data engineering teams select specific embedding models and conversion techniques appropriate to your exact data type and downstream task, ensuring your infrastructure returns highly relevant results while maintaining strict control over processing overhead.
→ Explore our Machine Learning Development services







")




 Create project brief with AI
Create project brief with AI