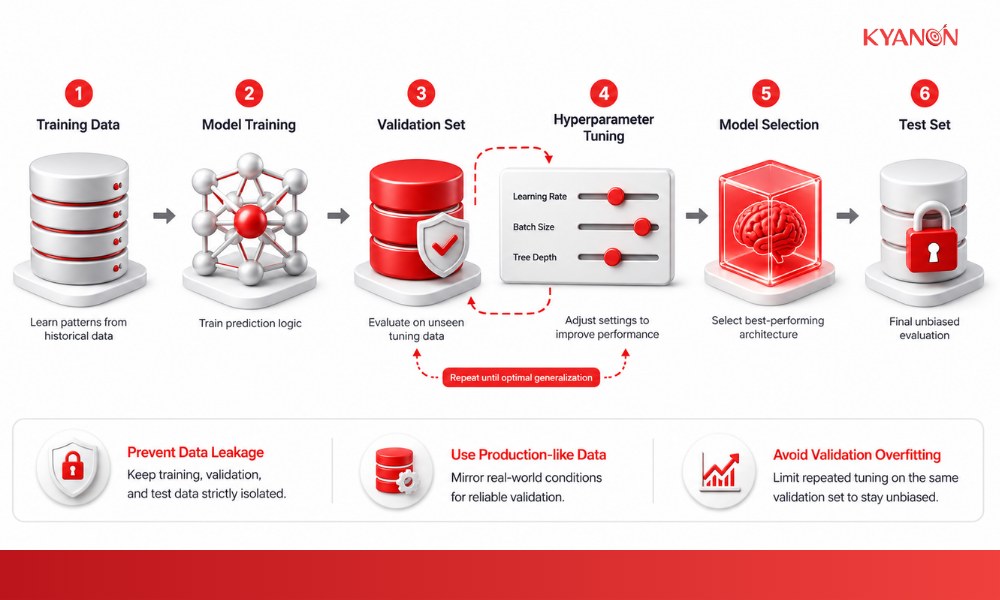
What is a Validation Set?
A validation set is a distinct subset of data used during the training phase of a machine learning model to evaluate its performance, tune hyperparameters, and prevent overfitting. It acts as an unbiased checkpoint that guides the selection of the most accurate model architecture before final testing.

How a Validation Set works
A validation set functions as an intermediary evaluation metric that provides feedback to the algorithm during the learning phase. Rather than adjusting the model’s core weights, the validation set dictates the adjustment of hyperparameters, ensuring the model generalizes patterns rather than memorizing the training data.
Hyperparameter tuning
The validation set provides the metrics necessary to adjust structural settings like learning rate, batch size, or tree depth. This iterative feedback loop ensures the model architecture is optimized for unseen data rather than just the training subset.
Overfitting prevention
By comparing training error against validation error, data scientists identify when a model begins to memorize noise. Training is halted when validation error increases, effectively stopping overfitting in its tracks.
Repeated hyperparameter experimentation against the same validation subset can gradually bias the model toward that dataset, reducing its reliability as a true proxy for production behavior.
Model selection
When multiple algorithms are tested, the validation set serves as the standardized benchmark to compare their performance. This prevents bias from influencing which algorithm is advanced to the final testing phase.
Production Data Representation
Effective enterprise validation sets must mirror real production conditions, including noisy records, incomplete inputs, class imbalance, and rare edge-case scenarios. Otherwise, validation accuracy may appear artificially high while production performance deteriorates after deployment.
Data Leakage Prevention
Enterprise ML teams enforce strict isolation between training and validation datasets to prevent contamination. Modern validation pipelines often include duplicate detection, semantic similarity analysis, and automated partition controls to ensure validation metrics remain statistically trustworthy.
Validation Set vs Test Set
Both subsets evaluate machine learning models, but the validation set guides development while the test set measures final, real-world readiness.
|
Dimension |
Validation Set | Test Set |
| Primary function | Model tuning and selection | Final model evaluation |
| Usage frequency | Multiple times per training cycle | Exactly once at the end |
| Influence on the model | High (adjusts hyperparameters) | Zero (strictly observational) |
| Data leakage risk | Moderate (models can overfit to it) | Low (if kept completely isolated) |
| Timing in the lifecycle | During the development phase | Post-development, pre-deployment |
When to consider a Validation Set
Consider implementing strict validation sets if:
- Your engineering team is deploying deep learning models that require extensive hyperparameter tuning to achieve baseline accuracy.
- Your current machine learning models perform exceptionally well in development environments but degrade rapidly when exposed to live production data.
- You are evaluating multiple distinct algorithms (e.g., Random Forest vs. Neural Networks) and need an empirical method to select the best performer.
- Your organization operates in dynamic environments where customer behavior, inventory demand, or operational conditions shift frequently, increasing the risk of model drift over time.
It may not be the right priority if:
- Your dataset is extremely small (under a few thousand records), making standard splits unfeasible and requiring strict cross-validation techniques instead to avoid data starvation.
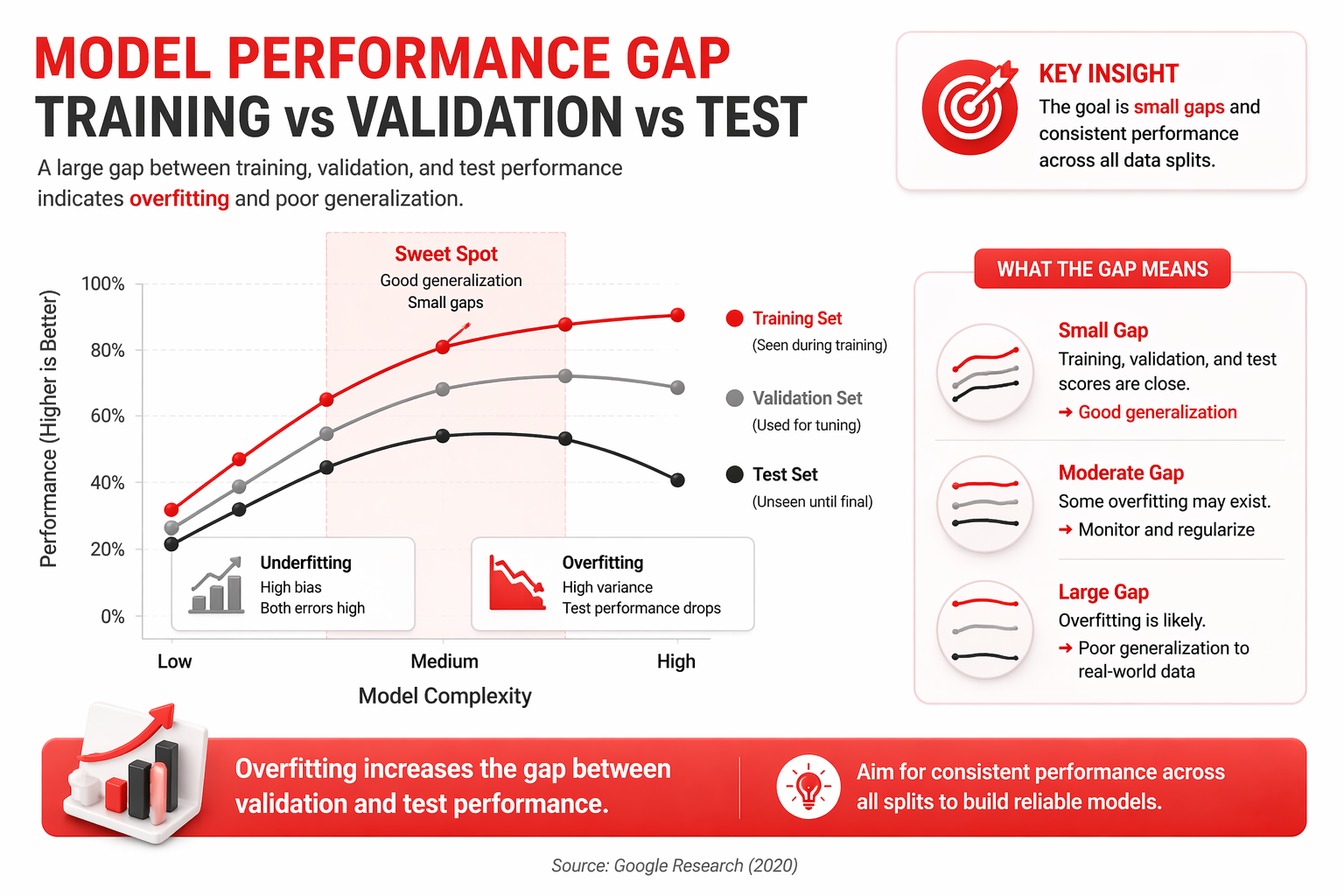
Why Validation Sets matter for enterprise AI
Proper data splitting practices directly dictate whether a machine learning initiative scales in production or fails due to data drift and memorization.
In enterprise environments, validation datasets cannot remain static indefinitely. Customer behavior, seasonal demand, and operational workflows continuously evolve, causing production data drift over time. High-performing AI organizations, therefore, implement scheduled validation set refresh cycles to ensure evaluation metrics remain aligned with real-world conditions.
Enterprise AI validation also extends beyond prediction accuracy alone. Mature organizations evaluate latency, inference cost, robustness under drift, and SLA stability alongside traditional ML metrics to ensure models remain production-ready at scale.
Supporting Evidence
According to Gartner (2022), nearly 80% of AI projects fail to scale due to performance degradation and data drift issues that stem from poor validation practices. A Southeast Asian retail enterprise applied strict validation and test splits to their demand forecasting model, resulting in a 24% reduction in inventory stockouts. This demonstrates how a rigorous validation methodology translates from an architectural principle to measurable business impact.
Common misconceptions
“The validation set gives us the final accuracy metric we can report to stakeholders.”
Reality: The validation set only measures performance during tuning. Because you actively select the best model based on validation metrics, the model becomes slightly biased toward it, requiring an entirely separate test set for true final evaluation.
“A validation set is completely unseen data, so scoring high on it means the model is ready for production.”
Reality: While the model does not train directly on validation data, the validation set dictates hyperparameter choices. This indirect influence means the validation set is not truly unseen, which is why continuously tweaking parameters based on validation scores often leads to overfitting the validation set itself.
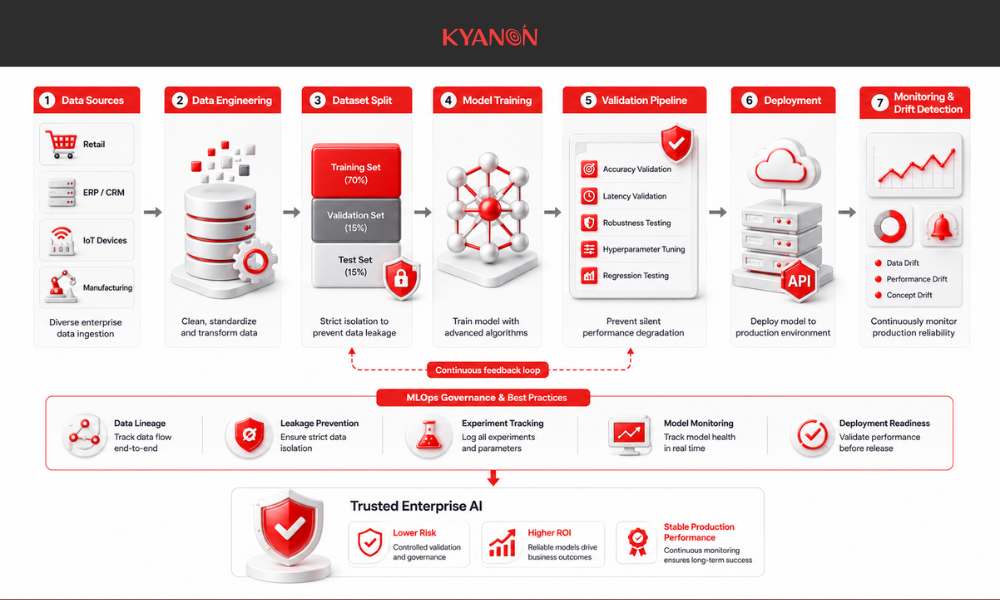
How Kyanon Digital Applies Validation Sets
Kyanon Digital implements proper train, validation, and test splits in all enterprise machine learning projects to ensure model evaluations are statistically sound. Our data engineering team utilizes automated hyperparameter tuning pipelines on structured validation sets for retail and manufacturing clients across Southeast Asia, ensuring models prioritize generalization over memorization to deliver measurable TCO reductions in production environments.
The company also integrates validation workflows directly into enterprise MLOps pipelines, enabling automated regression testing and continuous model evaluation before deployment. This ensures updated model versions do not silently degrade operational accuracy, latency, or operational cost in production environments.
→ Explore our Machine Learning Services







")




 Create project brief with AI
Create project brief with AI