What is weight initialization?
Weight initialization is the process of assigning the starting numerical values of a neural network’s parameters before optimization begins. These initial values determine whether gradient signals can propagate correctly through deep layers during backpropagation or collapse mathematically before the model completes its first training epoch.
Weight initialization establishes the baseline geometry of the optimization landscape. If the initialization scale is unbalanced, even advanced optimizers such as Adam or RMSProp cannot prevent unstable convergence, gradient collapse, or failed training.

How weight initialization works
Deep neural networks repeatedly multiply activations and gradients across many sequential layers. Weight initialization controls the variance of these signals so they neither shrink toward zero nor explode toward infinity during forward propagation and backpropagation.
Modern initialization strategies scale random weight variance according to each layer’s fan-in and fan-out dimensions. This mathematical balancing preserves stable information flow across the network depth.
Symmetry breaking
Neural networks require randomized initialization so neurons learn different feature representations. If all weights are initialized to identical values, such as zero, every neuron produces the same outputs and receives identical gradients during backpropagation.
This symmetry collapse causes an entire hidden layer to behave like a single neuron, eliminating the model’s ability to learn diverse patterns.
Variance preservation
Initialization methods are designed to preserve activation variance as signals move through deep architectures. Poorly scaled weights cause variance to either decay exponentially or amplify uncontrollably across layers.
Variance preservation is the mathematical foundation behind Xavier, He, and Orthogonal initialization methods.
Activation-aware scaling
Different activation functions require different initialization strategies. Xavier initialization assumes symmetric activations such as Sigmoid or Tanh, while He initialization compensates for the half-zeroing behavior of ReLU activations.
Using the wrong initializer progressively destabilizes gradient flow as network depth increases.
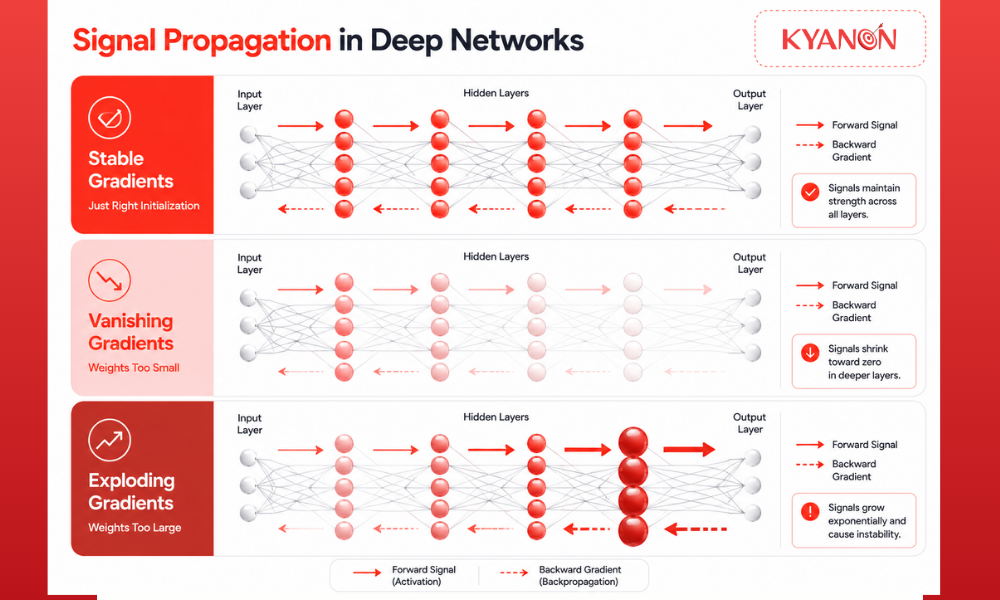
The three critical failures of bad initialization
Improper weight initialization consistently triggers one of three structural training failures in deep neural networks.
| Failure Mode | What Happens | Business Impact |
| Symmetry Collapse | Identical weights create identical neuron behavior | Model capacity collapses |
| Vanishing Gradients | Tiny weights shrink gradients exponentially | Early layers stop learning |
| Exploding Gradients | Large weights amplify updates uncontrollably | Training becomes numerically unstable |
| Activation Saturation | Large activations push Sigmoid/Tanh into flat regions | Optimization stalls |
| Numerical Overflow | Gradient values diverge toward infinity | Training loss becomes NaN |
Weight initialization vs random initialization
Both approaches assign starting parameter values, but they differ fundamentally in mathematical stability.
|
Dimension |
Weight Initialization |
Arbitrary Random Initialization |
| Variance control | Mathematically scaled | Uncontrolled |
| Activation compatibility | Activation-aware | Generic |
| Gradient stability | Preserved across depth | Frequently unstable |
| Deep network suitability | High | Low |
| Numerical reliability | Stable convergence | Risk of NaN collapse |
| Best for | Production of deep learning systems | Small experimental models |
| Optimization efficiency | Faster convergence |
Unpredictable training |
Standard initialization strategies
Modern deep learning frameworks pair initialization methods with activation behavior to stabilize optimization.
|
Initialization Method |
Ideal Activation | Mathematical Objective |
| Xavier / Glorot | Sigmoid, Tanh | Preserve activation and gradient variance |
| He / Kaiming | ReLU, Leaky ReLU | Compensate for ReLU zeroed activations |
| Orthogonal | RNNs, LSTMs | Preserve gradient norms across long sequences |
Modern initialization methods balance signal propagation across layers to prevent vanishing or exploding gradients during training.
When to consider weight initialization
Consider weight initialization if:
- Your AI teams are training deeper recommendation, forecasting, or computer vision models, and convergence reliability is deteriorating.
- Your organization is spending excessive GPU time on failed experiments caused by unstable optimization behavior.
- Your engineers are repeatedly adjusting learning rates or normalization layers to compensate for inconsistent gradient flow.
It may not be the right priority if:
- Your organization relies primarily on pretrained APIs or shallow models with minimal custom training requirements.
Why weight initialization matters for enterprise AI systems
Weight initialization directly affects model convergence efficiency, infrastructure utilization, and retraining costs in enterprise AI environments. Improper initialization increases failed training runs, delays deployment cycles, and wastes GPU resources without improving model quality.
Supporting evidence
Research from the University of Oxford and Google Brain introduced He initialization specifically to stabilize deep ReLU-based networks, enabling substantially deeper architectures to converge reliably (He et al., 2015).
An enterprise retail platform in Southeast Asia improved recommendation model retraining consistency after replacing generic Gaussian initialization with He initialization in ReLU-based ranking models. Failed training runs decreased because gradients no longer collapsed during early optimization stages.
Common misconceptions
“Setting all weights to zero is a clean neutral starting point”
Reality: Zero initialization destroys symmetry across hidden neurons. Every neuron learns the same representation, effectively collapsing model capacity.
“Any small random values are sufficient”
Reality: Randomness alone is insufficient. If the variance is too small, gradients vanish exponentially in deep architectures.
“Larger weights prevent vanishing gradients”
Reality: Oversized weights create exploding gradients, activation saturation, unstable loss oscillation, and eventual NaN numerical failures.
“One initialization strategy works for every activation function”
Reality: Initialization methods must be mathematically paired with activation behavior. Xavier is optimized for Sigmoid/Tanh, while He initialization is designed specifically for ReLU-family activations.
How Kyanon Digital applies weight initialization
Kyanon Digital applies activation-aware initialization strategies during custom AI model development for enterprise clients across Southeast Asia, ANZ, the US, and Nordic Europe. Engineering teams select Xavier, He, or Orthogonal initialization depending on activation behavior, model depth, and sequence architecture requirements to reduce unstable training cycles and improve convergence reliability in production AI systems.
This work is integrated into broader MLOps, AI optimization, and enterprise deployment workflows focused on reducing retraining overhead, shortening experimentation cycles, and improving total infrastructure efficiency.
→ Explore our Machine Learning Development







")




 Create project brief with AI
Create project brief with AI