What is Word2Vec?
Word2Vec is a shallow two-layer neural network model introduced by Tomas Mikolov and colleagues at Google in 2013 that learns dense vector representations of words by predicting contextual co-occurrence patterns in large text corpora. These vectors position semantically related words near each other in a continuous latent space.
For enterprise NLP systems, Word2Vec marks the architectural shift from rigid keyword matching to semantic retrieval based on meaning similarity rather than exact text overlap.

How Word2Vec works
Word2Vec operationalizes the distributional hypothesis by optimizing vectors so that words appearing in similar contexts share nearby coordinates in vector space, trained via stochastic gradient descent over sliding context windows.
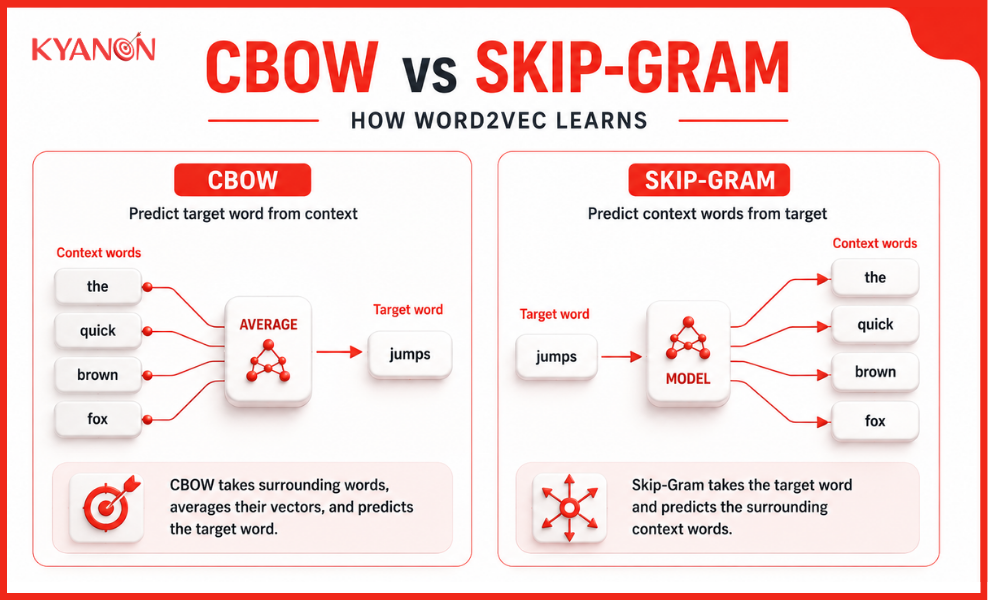
Continuous bag of words (CBOW)
CBOW predicts a target word from surrounding words, enabling efficient learning of general semantic relationships at scale.
Skip-gram
Skip-Gram predicts the surrounding context from a target word and performs better for rare terms in large vocabularies.
Negative sampling
Negative sampling reduces computational load by updating only a small subset of weights per step rather than the full vocabulary.
Word2Vec vs BERT
Both generate vector representations of text, but they play very different roles in modern enterprise NLP architecture.
|
Dimension |
Word2Vec | BERT |
| Architecture | Shallow 2-layer network | Deep multi-layer transformer |
| Context awareness | Static embedding | Contextual embedding |
| Compute needs | CPU-friendly | GPU-intensive |
| Best for | Similarity, clustering, indexing | Understanding, QA, and generation |
| Role in pipeline | Vector indexing layer | Reasoning layer |
| Cost profile | Low OpEx |
High infrastructure cost |
When to consider Word2Vec
Consider Word2Vec if:
- You are replacing keyword-based enterprise search with semantic retrieval across internal documents.
- You need recommendation logic based on behavioral similarity (often called Prod2Vec in e-commerce).
- You must process millions of records with minimal infrastructure cost.
It may not be the right priority if:
- Your primary problem is sentence interpretation, sentiment analysis, or intent detection.
Why Word2Vec matters for e-commerce & enterprise search
Word2Vec solves the synonym problem in enterprise systems where traditional search fails when users phrase queries differently from how documents were written.
Supporting evidence
Research from Stanford University (2014) shows Word2Vec embeddings improved word similarity accuracy by 30%+ over traditional count-based models.
In e-commerce platforms, this same logic is adapted as Prod2Vec, where products are treated like words in user session sequences to learn behavioral similarity without manual tagging.
Core enterprise use cases
Word2Vec is widely applied in:
- Enterprise search & discovery: Retrieving documents based on meaning, not wording.
- E-commerce recommendations (Prod2Vec): Learning product similarity from user sessions.
- Customer support ticket routing: Classifying tickets by semantic intent rather than keywords.
- Data anonymization & compliance scanning: Identifying sensitive concepts in unstructured legal or medical text.
Business advantages for enterprise systems
Raw enterprise text → Word2Vec training → dense vectors → fast cosine similarity math.
- Extremely low compute cost due to shallow architecture.
- Real-time speed suitable for high-throughput pipelines.
- Can be trained entirely on-premise with zero data leakage to third-party APIs.
- Highly effective when trained on domain-specific corporate language (legal, aviation, finance, healthcare).
Structural limitations in modern architectures
Word2Vec generates exactly one fixed vector per word and cannot adapt based on sentence context, known as the static embedding limitation.
|
Capability |
Word2Vec | Modern Transformers |
| Context handling | One vector per word | Dynamic vectors |
| Example | Cannot separate “bank” meanings | Distinguishes instantly |
| Resource needs | CPU |
GPU |
The modern enterprise hybrid approach
Modern NLP architectures combine both technologies for cost and performance optimization:
- Vector database layer: Word2Vec performs fast semantic indexing and filtering across millions of records at low cost.
- LLM layer: Transformers read the shortlisted documents for summarization, Q&A, or reasoning.
This hybrid design is common in enterprise AI pipelines where indexing and reasoning are separated.
Common misconceptions
“Word2Vec is deep learning.”
Reality: Word2Vec is a linear, shallow two-layer network without non-linear activations.
“Word2Vec understands word meaning in a sentence.”
Reality: Word2Vec produces static embeddings and cannot adapt to context.
How Kyanon Digital applies Word2Vec
Kyanon Digital integrates Word2Vec within Kyanon Digital’s NLP solutions as the vector indexing layer for enterprise semantic search and document clustering before transformer-based reasoning, particularly for domain-specific corpora across Southeast Asia enterprise clients.
→ Explore our Machine Learning Development







")




 Create project brief with AI
Create project brief with AI