What is XGBoost?
XGBoost (Extreme Gradient Boosting) is an open-source, scalable machine learning library that implements gradient-boosted decision trees optimized for speed and performance on structured data. The algorithm executes supervised learning tasks by combining the predictions of multiple weaker decision trees to deliver highly accurate classification and regression outputs.

How XGBoost works
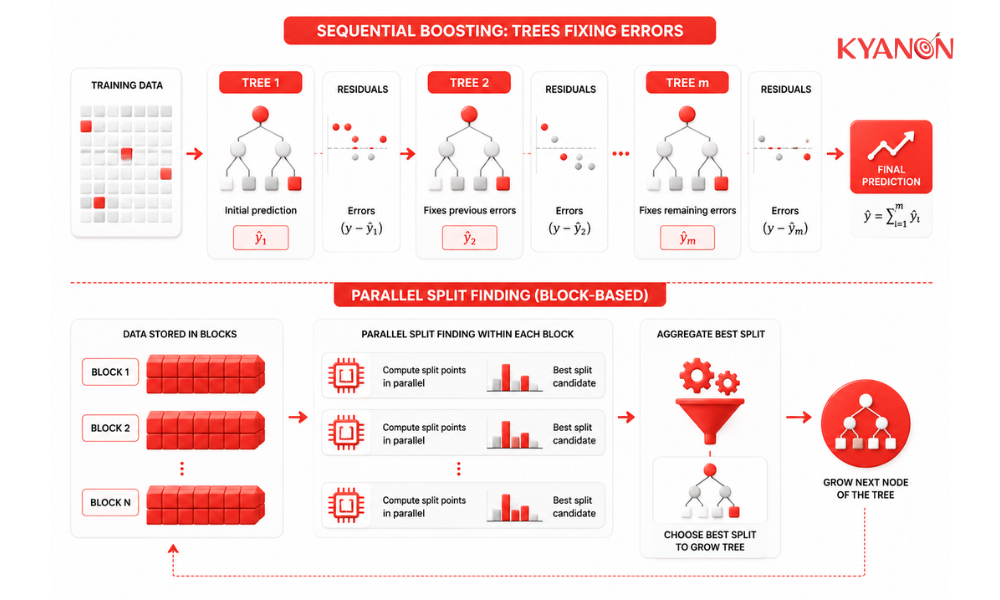
XGBoost minimizes a regularized objective function combining a specific loss function with a penalty term for model complexity. Unlike traditional algorithms that generate models independently, this library constructs decision trees sequentially, with each subsequent tree designed to minimize the residual errors of the preceding ensemble. It optimizes system resources by parallelizing the split-finding process within individual tree structures rather than across separate trees.
Regularized objective function
The objective function incorporates both L1 (Lasso) and L2 (Ridge) regularization parameters directly into the optimization target. This mathematical constraint penalizes complex models with excessive leaf nodes, preventing overfitting during sequential training phases.
Sparsity-aware split finding
The system features a built-in execution path for handling missing data, sparse matrices, and zero entries. During training, the algorithm assigns a default direction for missing values by evaluating which branch path minimizes the overall training loss, eliminating manual data imputation.
Cache-aware access & parallel block structure
To accelerate computational throughput, data is stored in pre-sorted, in-memory layouts called blocks, which allow parallel processing of feature columns. The algorithm allocates dedicated internal buffers to store gradient statistics, a layout that minimizes CPU cache misses during iterative tree building.
Out-of-core computing
For massive enterprise datasets that exceed system RAM capacity, the system employs an out-of-core computing design. This sub-system optimizes disk space utilization by dividing data into independent chunks and streaming them asynchronously via a dedicated background thread during training.
Native feature importance scoring
The library calculates native feature importance ranking scores directly from the trained tree structures based on metrics such as weight, gain, and cover. This metric provides a clear mathematical breakdown of which variables exert the most influence over corporate model outcomes.
XGBoost vs Random Forest
While both frameworks are ensemble tree methods, XGBoost minimizes bias sequentially, whereas Random Forest reduces variance through parallel independent tree generation.
|
Dimension |
XGBoost | Random Forest |
| Training Architecture | Sequential (Trees fix previous errors) | Parallel (Trees built independently) |
| Handling of Missing Data | Automatic via sparsity-aware routing | Requires manual imputation |
| Overfitting Vulnerability | High if the learning rate is untuned | Low due to variance averaging |
| Feature Scaling Requirement | None (Scale-invariant thresholds) | None (Scale-invariant thresholds) |
| Primary Optimization Focus | Bias reduction via Gradient Descent |
Variance reduction via Bagging |
When to consider XGBoost
XGBoost is mathematically optimal for tabular data configurations but structurally incapable of extrapolating values outside the training set boundaries.
Consider XGBoost if:
- Your data architecture relies on large-scale structured or tabular datasets containing significant volumes of missing features or sparse metrics.
- Your technical operations require accelerated model training routines and low-latency inference outputs to support automated decision-making.
- Your engineering teams need to deploy models natively across distributed engines like Spark, Flink, or Ray to handle petabyte-scale clusters.
- Your organization utilizes managed infrastructure like AWS SageMaker, Google Vertex AI, or Azure ML and requires models that leverage both CPU pipelines and GPU acceleration.
It may not be the right priority if:
- Your immediate development objective involves long-term trend forecasting for raw, undifferenced time-series datasets or relies entirely on unstructured assets like text corpora and image matrices.
Why XGBoost matters for enterprise analytics
The systems engineering design of XGBoost allows it to process sparse data structures efficiently without expanding the hardware footprint. For enterprises running production systems, the ability to export models into lightweight C++ formats or Treelite enables sub-millisecond prediction speeds for critical transactions. Furthermore, its structured serialization support ensures that models can be easily saved, versioned, and verified to satisfy compliance audits.
Supporting evidence
According to the Association for Computing Machinery, the XGBoost algorithm executes up to 10 times faster than existing popular solutions on a single machine, directly reducing cloud infrastructure expenditures. This acceleration ensures that corporate data science infrastructure operates at optimal resource utility.
In practical application, enterprise financial institutions leverage XGBoost within their credit scoring and fraud detection pipelines to process complex, high-dimensional transactional tables. By utilizing the algorithm’s built-in sparsity-aware split finding, technical groups bypass intensive manual data imputation workflows entirely, accelerating the deployment of risk assessment models while sustaining the exact target classification precision required by compliance and operations executives.
Common misconceptions
“XGBoost trains decision trees in parallel.”
Reality: The parallel execution of XGBoost operates at the feature block level during split-finding, rather than the tree construction level. Because boosting models build each tree to fix the mathematical residuals of the previous structure, tree production remains entirely sequential.
“You must always execute manual imputation on missing values before training.”
Reality: The framework automatically learns the optimal path for missing entries by evaluating loss functions during the split calculation phase. Forcing manual imputation through mean or median substitutions often introduces bias and eliminates valuable structural indicators present in empty fields.
How Kyanon Digital applies XGBoost
Kyanon Digital integrates XGBoost within distributed cloud infrastructures to optimize machine learning pipeline latency for Southeast Asian enterprise operations. Our technical teams deploy these optimized tree configurations within modern managed environments, including AWS SageMaker, Google Vertex AI, and Azure ML, to build predictive systems such as automated credit evaluation, demand forecasting, and consumer churn metrics for large-scale retail and financial organizations across Vietnam, Singapore, and Malaysia. By leveraging big data backends like Spark and Ray, we focus on engineering scalable, production-ready machine learning workflows under our enterprise consulting services that minimize computation costs while supporting high real-time transactional volumes.
→ Explore our Machine Learning services







")




 Create project brief with AI
Create project brief with AI