What is XML-Based Model Exchange (PMML)?
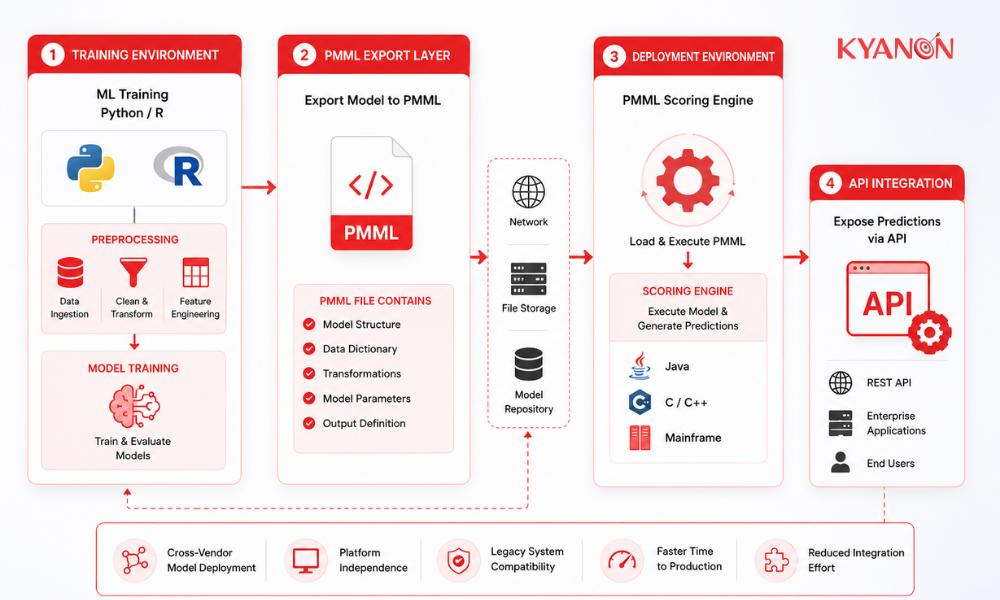
XML-Based Model Exchange (PMML) is an open, XML-based standard language used to define and share statistical and data mining models between compliant applications. It provides a platform-independent method for data science teams to export predictive models from training environments and execute them within separate production scoring engines without manual recoding.
How XML-Based Model Exchange (PMML) works
PMML operates by completely separating the model development environment from the operational production environment. A standard PMML document uses a strict XML structure to define both the data pipeline and the model parameters, enabling legacy platforms lacking modern Python or R runtimes to execute predictive scoring logic natively.
Header and data dictionary
The Header component contains general metadata, including the model name, application version, and creation timestamp. The Data Dictionary defines all possible input and output fields, explicitly specifying their data types and permissible value ranges.
Data transformations and mining schema
Data Transformations specify preprocessing steps such as normalization, missing value handling, and feature scaling. The Mining Schema lists the exact fields utilized by the model and dictates how the scoring engine handles outliers.
Model element and output
The Model Element contains the actual structural parameters of the algorithm, such as decision trees, regression coefficients, clustering rules, or support vector machines. The Output element defines the precise format of the predicted values, probabilities, or classification labels generated during execution.
The Step-by-Step integration workflow
- Train and Export: Data scientists train a machine learning model using modern frameworks and leverage open-source libraries to export the asset into a .pmml file. Python users rely on tools like nyoka or sklearn2pmml, while R users implement the pmml package.
- Verify and Validate: The generated file is validated against the official Data Mining Group (DMG) schemas to ensure compliance. Test datasets are passed through both environments to confirm prediction scores match exactly.
- Deploy to Legacy Infrastructure: The verified .pmml file is loaded into a PMML consumer engine embedded within production systems. Java environments execute the model via JPMML-Evaluator, while database systems like IBM Db2, Oracle, or SQL Server import the schema directly to run real-time predictions using standard SQL queries.
XML-Based Model Exchange (PMML) vs ONNX Inference Engine
Both standard formats remove the requirement to manually rewrite data science models for production environments, but they target different computational categories and infrastructure ecosystems.
|
Dimension |
XML-Based Model Exchange (PMML) | ONNX Inference Engine |
| Primary Architecture | Text-based (XML structural tags) | Binary format (Protocol Buffers serialization) |
| Target Model Types | Traditional statistical models (Regression, Trees, SVM) | Deep learning and complex neural networks |
| Human Readability | High (Directly auditable via standard text editors) | Low (Requires specialized visualization utilities) |
| File Size Efficiency | Low (Verbose text limits large parameter storage) | High (Optimized for billion-parameter model weights) |
| Ecosystem Native Support | Legacy enterprise suites (SAS, SPSS, Java systems) |
Modern Python frameworks (PyTorch, TensorFlow) |
When to Consider XML-Based Model Exchange (PMML)
Consider XML-Based Model Exchange (PMML) if:
- Your production infrastructure relies on legacy Java, C, C++, or mainframe architectures that lack native runtimes for executing Python or R data science scripts.
- Your deployment strategy requires platform independence, allowing models to run on any hardware fitted with a PMML consumer engine.
- Your enterprise must avoid vendor lock-in to specific cloud platforms or proprietary analytical software stacks.
- Your target hardware has a lightweight footprint that cannot support heavy container environments like Docker.
It may not be the right priority if:
- Your workflows center on complex, modern deep learning architectures like Transformers, as PMML primarily supports traditional algorithms like Regression, Trees, SVM, and Clustering.
- Your applications use exceptionally large ensemble models, such as random forests with thousands of deep trees, which create massive XML files that consume excessive memory during parsing.
Why XML-Based Model Exchange (PMML) matters for enterprise technology
Utilizing a standardized model exchange format eliminates the operational delays and engineering costs associated with manually recoding data science outputs into target production software. This decoupling allows engineering teams to maximize infrastructure efficiency without limiting the tools used by data science departments.
Supporting evidence
According to a Gartner 2023 report, approximately 50% of data science models fail to reach production deployment due to structural friction between development platforms and operational environments. Standardizing on open-source exchange formats directly addresses this systemic operational block by establishing consistent system interoperability.
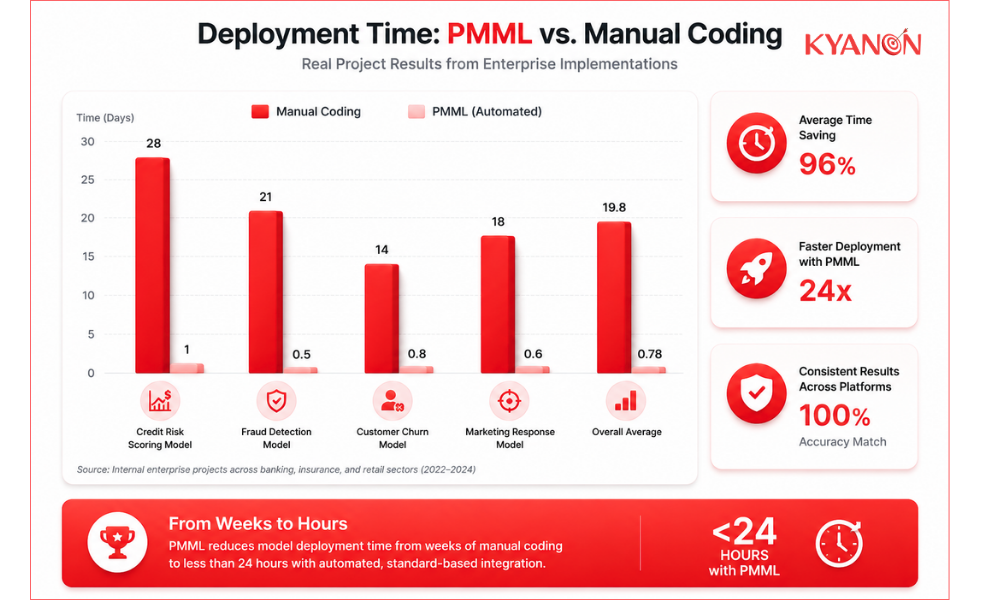
For instance, an enterprise banking institution in Southeast Asia utilized PMML within its legacy credit risk evaluation pipeline to host updated risk models. This operational approach reduced their model deployment cycle from four weeks of manual code conversion into Java and COBOL to less than 24 hours via automated XML parsing, demonstrating a measurable optimization of deployment timelines.
Common misconceptions
Enterprise decision-makers frequently misunderstand the specific technical position that PMML holds within modern artificial intelligence pipelines.
“PMML is an outdated format that cannot support modern machine learning pipelines.”
Reality: PMML version 4.4.1 includes standard specifications for deep neural networks, ensemble models, and intricate data transformations. It remains a stable option for operationalizing core statistical algorithms across non-Python enterprise infrastructure.
“Parsing XML text inside a PMML file introduces latency in real-time scoring environments.”
Reality: The XML schema parsing sequence occurs only once during the initial model loading phase into system memory. Subsequent transaction scoring speeds depend strictly on the memory-compiled execution engine rather than the underlying text format.
How Kyanon Digital applies XML-Based Model Exchange (PMML)
Kyanon Digital integrates XML-Based Model Exchange (PMML) within enterprise machine learning architectures for clients across Southeast Asia and the ANZ region operating hybrid or legacy environments. Our execution focus centers on establishing stable data pipelines between modern data science setups and traditional enterprise platforms, helping organizations minimize the total cost of ownership (TCO) while protecting existing core software investments.
→ Explore our AI and machine learning services







")




 Create project brief with AI
Create project brief with AI