What is YAML Config (MLOps)?
A YAML Config (MLOps) is a human-readable data serialization file used to define data paths, model hyperparameters, and environment infrastructure settings across a machine learning lifecycle, separate from the execution code. This structural separation ensures experiment reproducibility and allows data engineering teams to modify operational variables without altering the underlying source code application logic.
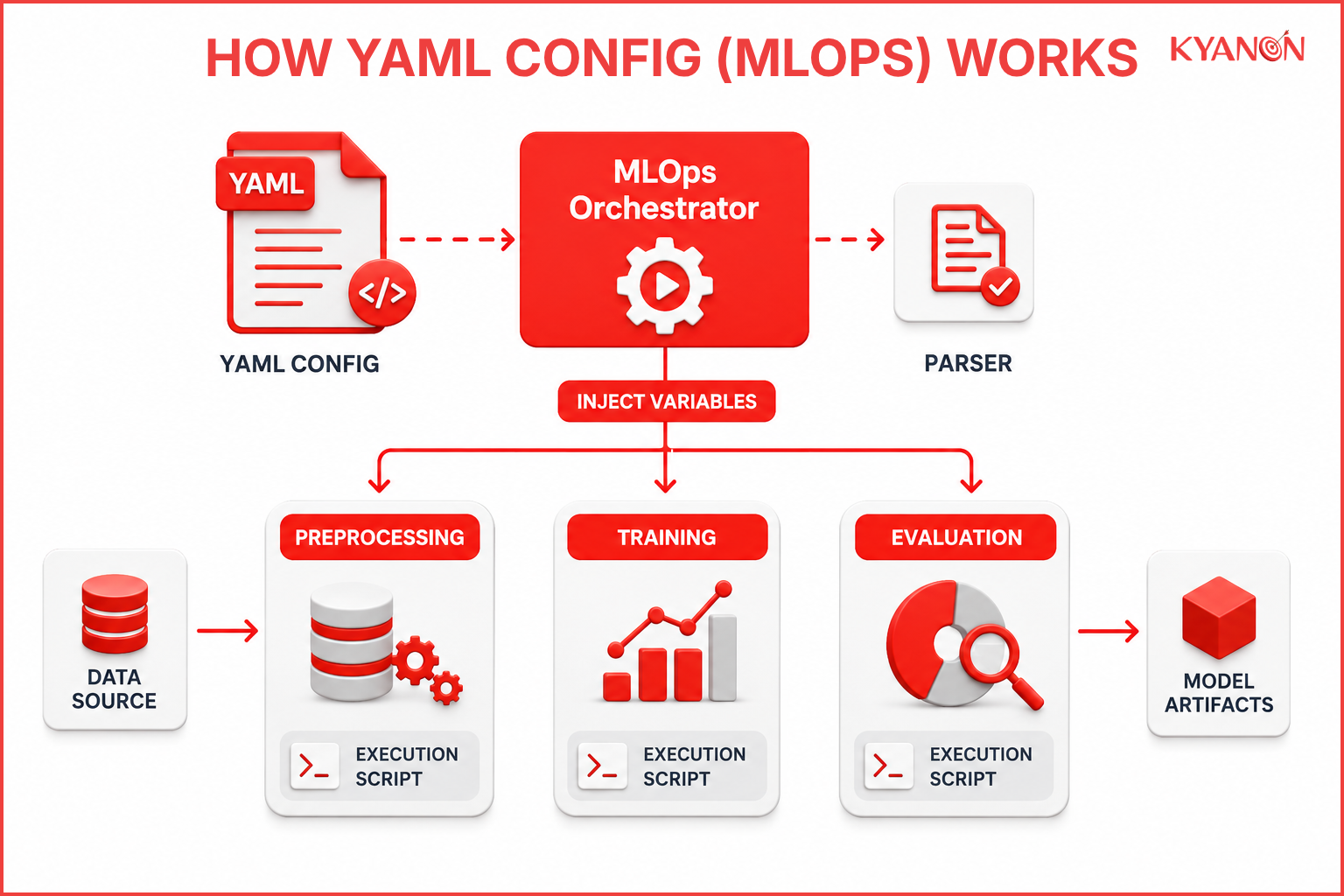
How YAML Config (MLOps) works
YAML configuration files act as a centralized declarative layer that an MLOps orchestrator parses at runtime to execute machine learning workflows. When an orchestration engine initiates a pipeline job, it reads the text-based instructions inside the YAML file and maps them into structured program variables, which are then injected into execution scripts to control training limits, dataset locations, and resource sizing.
Core architectural separation
The core architecture splits production machine learning frameworks into two distinct parts:
- The Code (Immutable): Python scripts that specify exactly how data is processed, transformed, and trained.
- The Config (Mutable): Modular YAML documents defining what specific data repositories, targets, and execution settings apply to a given run.
Plaintext
├── config/
│ ├── base.yaml # Default global settings
│ ├── dev.yaml # Local development overrides
│ └── prod.yaml # Production-grade hyperparameters
├── src/
│ ├── data_prep.py # Data ingestion and cleaning
│ ├── train.py # Model training logic
│ └── utils.py # YAML parser and helpers
└── main.py # Pipeline orchestrator
Hyperparameter definitions & layouts
This block specifies the structural variables and training constraints of the machine learning model, including learning rates, layer shapes, and optimization metrics. Isolating these parameters inside a clear config layout enables Git-driven experimentation tracking without modifying model code bases.
YAML
# config/base.yaml (Production Blueprint Extract)
project:
name: “customer-churn-prediction”
version: “1.2.0”
data:
raw_path: “s3://my-bucket/data/raw/churn.csv”
processed_dir: “s3://my-bucket/data/processed/”
test_size: 0.2
random_state: 42
features:
categorical: [“gender”, “contract_type”, “payment_method”]
numerical: [“tenure”, “monthly_charges”, “total_charges”]
target: “churn”
model:
algorithm: “LightGBM”
hyperparameters:
learning_rate: 0.05
num_leaves: 31
max_depth: 6
n_estimators: 100
objective: “binary”
artifacts:
model_output_dir: “s3://my-bucket/models/”
metrics_file: “metrics.json”
Programmatic execution parsers
This pipeline component reads textual configurations through runtime libraries and maps them directly into environment arrays. Utilizing safe decoding parameters ensures structural formatting errors fail before compute runtimes are billed.
Python
# src/utils.py
import yaml
def load_config(config_path: str) -> dict:
“””Safely loads a YAML configuration file to ensure parsing isolation.”””
with open(config_path, “r”) as stream:
try:
return yaml.safe_load(stream)
except yaml.YAMLError as exc:
raise ValueError(f”Error parsing YAML file: {exc}”)
Python
# main.py
import argparse
from src.utils import load_config
def main():
parser = argparse.ArgumentParser()
parser.add_argument(“–config”, type=str, default=”config/base.yaml”)
args = parser.parse_args()
config = load_config(args.config)
print(f”Starting {config[‘project’][‘name’]} pipeline…”)
print(f”Training {config[‘model’][‘algorithm’]} model.”)
if __name__ == “__main__”:
main()
Compute Infrastructure Targets & CI/CD Integration
This section outlines the exact infrastructure parameters, hardware definitions, and environment profiles. Automation engines like GitHub Actions read these files directly to dynamically allocate cloud instances (GPUs/CPUs) matching your exact parameter metrics.
YAML Config (MLOps) vs Code-Driven Configuration
Both approaches organize configuration data for automated systems, but they differ in how they decouple environment variables and manage pipeline logic.
|
Dimension |
YAML Config (MLOps) | Code-Driven Configuration (e.g., Python Dicts) |
| Deployment speed | Fast; parameters update instantly without code deployment | Slower; modifications require code testing and merge cycles |
| Vendor lock-in | Low; standard format native to most modern orchestrators | Medium; locked to specific programming runtimes or frameworks |
| Upfront complexity | Low; clear text layouts with declarative syntax | High; requires custom programmatic object setups |
| Best for | Decoupled pipeline automation and enterprise environments | Isolated code prototyping and local experimentation |
| Cost model | OpEx: optimizes cloud spend via external compute controls |
CapEx: increases engineering hours spent writing custom logic |
When to consider YAML Config (MLOps)
Consider YAML Config (MLOps) if:
- Your engineering teams deploy models across multiple environments (development, staging, production), where manual variable alignment causes configuration drift and system runtime errors.
- Your organization requires independent execution paths where non-developer data scientists adjust training hyperparameters without modifying the structural repository code.
- Your infrastructure engineers utilize Git-based version control to audit historical pipeline iterations and maintain an unalterable log of past model parameters.
It may not be the right priority if:
- Your data science operation is in an early-stage MVP phase, utilizing local Jupyter notebooks on standalone workstations with fewer than three developers.
Why YAML Config (MLOps) matters for enterprise operations
For enterprise operations running machine learning applications, configuration management directly controls the stability and cost-efficiency of production systems. Separating compute definitions and storage pathways into standardized text configurations prevents pipeline failure during data migrations and shifts compute overhead away from manual maintenance tasks.

Supporting evidence
According to a study by McKinsey (2024), approximately 90% of failures in machine learning initiatives stem not from poor model algorithms, but from flawed productization practices and the technical challenges of integrating models with production data and enterprise applications. This finding highlights the importance of establishing strict, standardized configuration boundaries, such as decoupled YAML structures, in order to eliminate operational friction and ensure long-term system stability.
A logistics provider in Southeast Asia utilized modular YAML configurations to decouple dynamic supply chain constraints from their predictive sorting models, reducing pipeline deployment cycles from days to under five minutes. This operational change shows how decoupling parameters convert complex technical debt into measurable velocity gains.
Common misconceptions
“YAML configurations automatically validate data types and values.”
Reality: YAML parsers inspect structural text indentation and basic syntax but do not verify semantic meaning or data type accuracy. A typo in an infrastructure allocation pass will escape initial file parsing and trigger errors only midway through execution runtime, destroying active compute work.
“Plain-text YAML files are completely secure for environment credentials.”
Reality: Standard YAML configuration documents do not feature native data encryption and will expose private database tokens if committed to open code branches. Enterprise implementations must reference environment variable placeholders to dynamically retrieve secrets at runtime, rather than hardcoding sensitive data.
How Kyanon Digital applies YAML Config (MLOps)
Kyanon Digital deploys isolated parameter management structures using schema-validation layers like Hydra and OmegaConf for enterprise logistics and retail clients across Southeast Asia. Our delivery approach isolates algorithm structures from core data definitions, eliminating configuration drift and maintaining system margin protection during automated model retraining loops.
→ Explore our Machine Learning Development services







")




 Create project brief with AI
Create project brief with AI