What are YAML-Defined ML Pipelines?
YAML-defined ML pipelines are declarative blueprints that configure the structural layout, dependencies, and execution parameters of machine learning workflows using YAML serialization syntax. These files decouple the infrastructure orchestration layer from the underlying algorithmic code execution.
How YAML-Defined ML Pipelines work
YAML-defined pipelines operate on a declarative framework where engineers specify the final state and execution order of a machine learning workflow rather than writing procedural infrastructure logic. Standardizing AI delivery through these blueprints provides core operational advantages: it tracks pipeline changes in Git alongside source code, ensures workflows run identically across diverse cloud environments, allows components to be reused across teams, and enables automated execution triggers via CI/CD platforms.
An orchestration engine parses the static YAML blueprint at runtime, instantiates the required compute resources, maps data schemas between sequential steps, and executes isolated workloads. Depending on your infrastructure strategy, these blueprints are executed across various specialized ecosystems:
- Kubeflow Pipelines (KFP): Orchestrates containerized tasks via Argo or Tekton engines, optimal for large-scale, cloud-native Kubernetes setups.
- GitHub Actions / GitLab CI: Directly runs foundational scripts and cloud provider CLI commands, ideal for lightweight automation triggers.
- Azure ML / AWS SageMaker Pipelines: Utilizes cloud-managed schemas to define native compute allocations, optimal for platform-locked ecosystems.
Minimalist ML Pipeline Definition Example
YAML
version: “1.0”
pipeline:
name: demand-forecasting-pipeline
environment: production-ml-env
stages:
– name: data_prep
image: python:3.10-slim@sha256:hash_value
command: python src/preprocess.py
inputs:
– dataset: “s3://raw-data/sales.csv”
outputs:
– clean_data: “s3://processed-data/sales_clean.parquet”
– name: model_training
image: tensorflow/tensorflow:latest-gpu
command: python src/train.py
resources:
gpu_count: 1
inputs:
– train_data: “s3://processed-data/sales_clean.parquet”
outputs:
– model_artifact: “s3://model-registry/forecaster/v1/”
– name: model_evaluation
image: python:3.10-slim@sha256:hash_value
command: python src/evaluate.py
inputs:
– model: “s3://model-registry/forecaster/v1/”
– threshold: 0.85
outputs:
– metrics: “s3://metrics/evaluation_report.json”
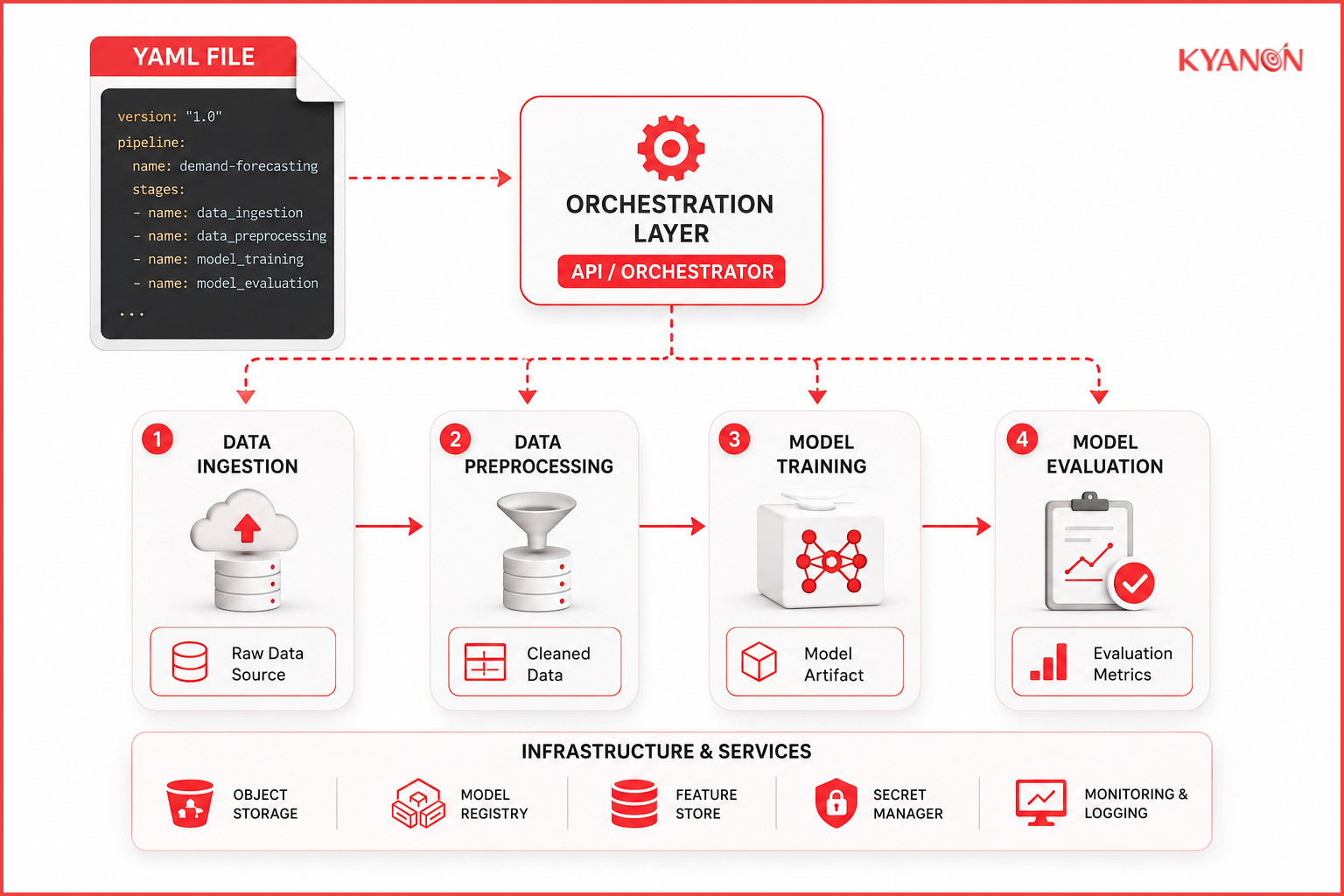
Pipeline topology blueprint
The structural configuration file maps the Directed Acyclic Graph (DAG) of the machine learning workflow. It outlines exactly which tasks run sequentially or in parallel, explicitly defining data ingestion, preprocessing, training, and evaluation steps.
Execution environment context
The section specifies the container images, resource allocations (such as GPU or memory thresholds), and infrastructure dependencies required for each pipeline step. This isolates execution runtimes to prevent dependency conflicts between different steps.
Data lineage and artifact bindings
The parameter mapping that defines inputs, outputs, and intermediate data routing between steps. It links the pipeline execution to data stores, feature stores, and model registries, verifying that the output of an upstream task matches the expected schema of a downstream step.
YAML-Defined Pipelines vs Imperative Scripting
Both approaches coordinate machine learning workflows, but they separate execution configuration from operational logic differently.
| Dimension | YAML-Defined Pipelines | Imperative Scripting |
| Deployment speed | Fast (via automated CI/CD triggers) | Slow (requires manual pipeline setup) |
| Vendor lock-in | Low (portable across orchestrators) | High (bound to specific script environments) |
| Upfront complexity | High (requires strict schema definition) | Low (rapid initial prototyping) |
| Best for | Multi-environment enterprise AI scaling | Local experimentation and ad-hoc testing |
| Cost model | OpEx (optimized on cloud compute blocks) |
CapEx (tied to static compute instances) |
When to consider YAML-Defined ML Pipelines
Transitioning to declarative configurations allows engineering teams to eliminate configuration drift across isolated deployment environments.
Consider YAML-defined ML pipelines if:
- Your engineering team is deploying machine learning models across multiple cloud regions and facing pipeline variations that trigger bugs during production releases.
- You are facing the industry average barrier where scaling production model deployments takes excessively long, often cited as a top challenge by DevOps teams, and your current setup requires rebuilding data pipelines manually for every new iteration.
- You are onboarding machine learning engineers frequently and need a standardized framework to guarantee immediate execution environment parity.
It may not be the right priority if:
- Your product team operates in an early-stage research phase with a single data scientist building standalone models on local environments.
Why YAML-Defined ML Pipelines matter for enterprise AI
Standardizing model orchestration mitigates the operational risks associated with structural configuration failures and missing architectural tracking in production systems.
Supporting evidence
According to Gartner (2023), over 50% of machine learning models fail to transition from pilot to production due to operationalization scaling bottlenecks. To resolve this, a financial enterprise in Singapore applied YAML-defined ML pipelines to their fraud detection systems, resulting in an automated deployment framework that dropped deployment cycle times from weeks to minutes. This demonstrates how declarative configurations translate from architectural principles to enterprise delivery performance.
Common misconceptions
Differentiating between static configuration blueprints and active execution logic prevents operational fragmentation in machine learning lifecycles.
“YAML files function as executable code that manages complex internal pipeline logic.”
Reality: YAML is strictly a data-serialization format used to map out structural blueprints. Complex loops, data transformations, and business logic belong inside modular Python scripts, which the YAML configuration invokes at specific execution steps.
“Validating YAML syntax guarantees that the machine learning pipeline will execute successfully.”
Reality: YAML linters only check indentation, structure, and basic data types. They cannot identify data schema mismatches between steps, invalid software imports, or runtime out-of-memory errors, which require local simulation execution tools.
“Storing database credentials or API keys directly inside pipeline YAML files is safe if the repository is private.”
Reality: Storing plaintext secrets in source control exposes core infrastructure to lateral security vulnerabilities. Enterprise workflows must mandate runtime secret manager injection or environment variable mapping rather than hardcoding credentials inside static files.
“Standard Git version tracking on YAML files provides total ML pipeline reproducibility.”
Reality: Git tracks textual changes to the configuration structure, not the underlying data mutations or model weights. Complete reproducibility requires utilizing immutability rules-such as tagging container images with specific cryptographic hashes rather than mutable tags-and leveraging metadata trackers to record unique input and output URI paths.
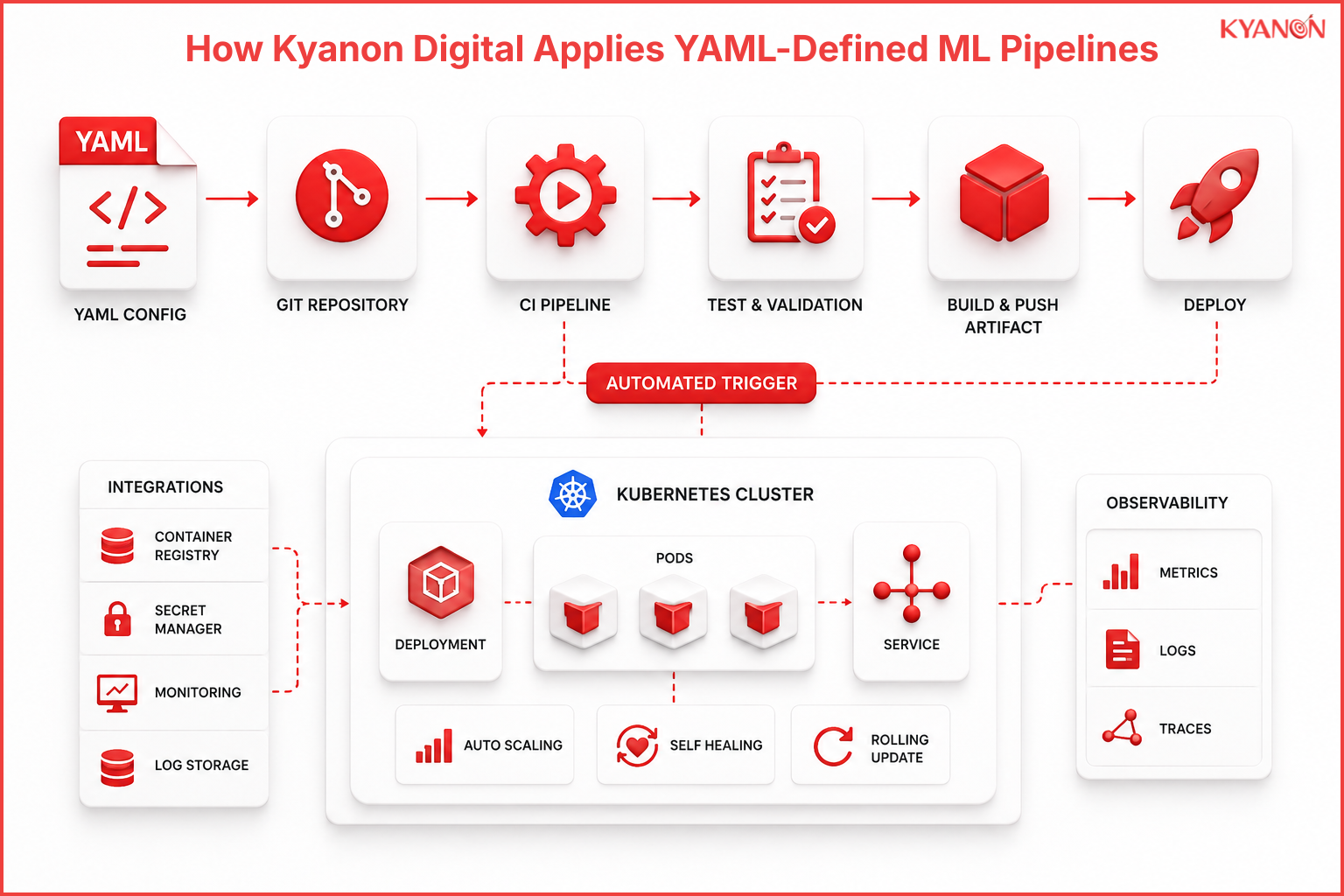
How Kyanon Digital applies YAML-Defined ML Pipelines
Kyanon Digital implements declarative workflows using orchestrators like Kubeflow, Argo Workflows, and Azure Pipelines for retail and banking enterprises across Singapore, Malaysia, and Vietnam. Our approach focuses on embedding declarative architectures directly into existing source control systems to achieve automated, audit-ready deployments.
→ Explore our AI & Machine Learning Development Services







")




 Create project brief with AI
Create project brief with AI