What is Yield Prediction (ML)?
Yield prediction (ml) is the application of supervised machine learning algorithms, such as regression analysis and time-series forecasting, to estimate the future output or quantity of a manufacturing, chemical, or industrial process based on historical and real-time data inputs. This statistical forecasting method replaces manual spreadsheet estimates with automated calculations to anticipate operational output variations before production lines finish execution.
How Yield Prediction (ML) works
Yield prediction (ML) functions by identifying complex, non-linear correlations between operational inputs, such as raw material attributes, equipment telemetry, ambient conditions, and historical throughput records, and final production outputs. Rather than relying on rigid, deterministic formulas or simple historical averaging, the computational system leverages sensor-driven visibility, replacing static spreadsheets with continuous IoT data streams to eliminate human guesswork from volume calculations. This granular data analysis allows algorithms to evaluate hundreds of variables simultaneously, including environmental humidity and operator shifts, to establish an adaptive baseline.
Feature engineering and data extraction
This phase collects and processes raw telemetry, IoT sensor signals, and enterprise resource planning (ERP) records into structured data matrices. It filters system noise and isolates the specific operational variables that directly correlate with final batch success metrics.
Predictive algorithm execution
The structured dataset passes through mathematical algorithms, typically gradient boosting machines, random forests, or recurrent neural networks, to calculate future volume outputs. The algorithm processes real-time asset variables to determine the single most probable yield volume for the active production cycle.
Model evaluation and retraining loops
The system continuously compares predicted yield volumes against actual physical output values collected at the end of each production cycle. The error variance data feeds back into the central infrastructure, triggering automated recalibration routines to prevent predictive accuracy degradation over time.

H2- Yield Prediction (ML) vs Traditional Statistical Forecasting
Both approaches solve inventory and production output uncertainty, but differ in their technical capacity to process multi-variable, non-linear system data.
| Dimension | Yield Prediction (ML) |
Traditional Statistical Forecasting |
|
Deployment speed |
Slow (Requires pipeline setup) | Fast (Uses out-of-the-box equations) |
|
Vendor lock-in |
Low (Built on open-source frameworks) | High (Tied to proprietary ERP software) |
|
Upfront complexity |
High (Requires rigorous data engineering) |
Low (Relies on basic historical spreadsheets) |
|
Best for |
Complex multi-variable supply chains |
Stable, linear historical output patterns |
| Cost model | OpEx (Continuous compute and monitoring) |
CapEx (One-time software licensing fee) |
When to consider Yield Prediction (ML)
Operational performance depends directly on matching output volumes to strict supply chain constraints.
Consider Yield Prediction (ML) if:
- Production planning accuracy drops below acceptable thresholds due to highly volatile raw material quality or fluctuating environmental parameters.
- Manufacturing facilities experience frequent material waste or stockouts because legacy planning tools fail to compute the correlation between multi-machine parameters.
- Enterprise operations span multiple regional processing facilities, generating massive volumes of operational data that human operations teams can no longer manually evaluate.
It may not be the right priority if:
- Your organization operates a low-volume, highly stable production facility with fewer than three core variables and minimal digital data infrastructure.
Why Yield Prediction (ML) matters for manufacturing and supply chain
Operational profitability in industrial manufacturing relies heavily on minimizing the variance between planned capacity and actual output. Yield prediction (ml) serves as a core optimization engine by transforming raw manufacturing data into actionable, real-time production adjustments across two critical areas:
1. Minimizing material waste
- Early defect detection: Algorithmic scanning identifies faulty patterns early in production, enabling teams to stop scrap generation immediately.
- Parameter optimization: Models analyze historical performance data to isolate ideal machine settings, preventing ruined batches before execution.
- Predictive maintenance: Analytics systems flag mechanical tool wear before it causes product damage, scheduling service before defects occur.
- Dynamic quality control: Infrastructure software adjusts processing variables automatically during active manufacturing, utilizing live tuning to keep products within tolerance limits.
2. Eliminating forecast errors
- Real-time supply integration: Machine learning models update production timelines instantly when raw material quality shifts, keeping downstream delivery estimates accurate.
- Capacity planning: Software accurately projects future factory output based on current machine health, preventing organizations from overpromising to enterprise customers.
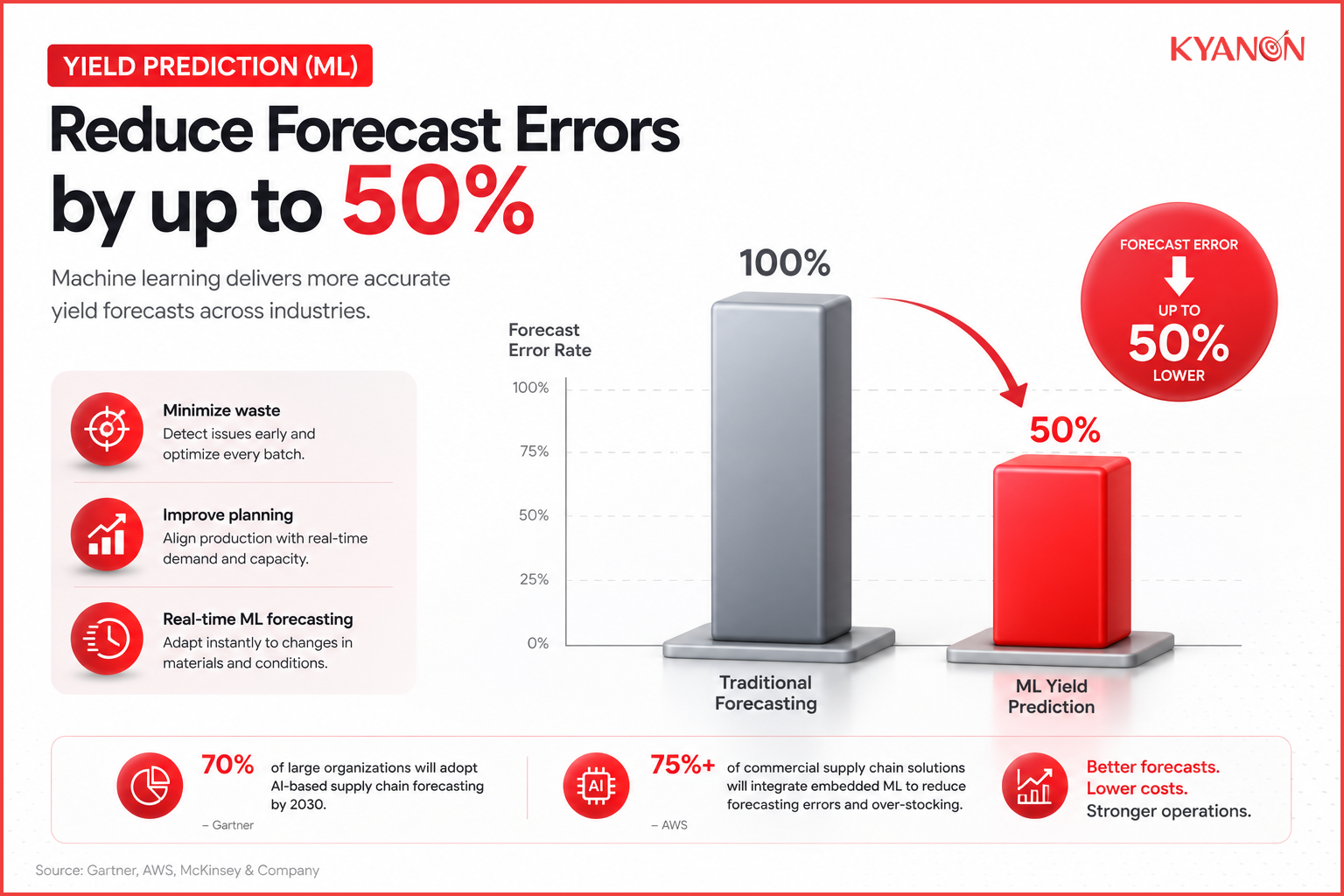
Supporting evidence
Market data confirms this structural shift toward algorithmic operations:
- Gartner predicts that 70% of large organizations will adopt AI-based supply chain forecasting by 2030, replacing static spreadsheets.
- AWS highlights that over 75% of commercial supply chain solutions will integrate embedded ML to eliminate legacy margins of error and over-stocking.
This predictive approach delivers direct bottom-line impact across diverse manufacturing verticals:
- Semiconductor Fabrication: Predicts wafer defects before final etching $\rightarrow$ prevents the waste of rare gases and high-cost silicon substrates.
- Chemical Processing: Forecasts reaction yields against shifting ambient temperatures, eliminates ruined, unrecyclable production batches.
- Food Manufacturing: Anticipates ingredient moisture absorption during automated baking, preventing burnt, wasted inventory without manual operator overrides.
- Consumer Packaged Goods (CPG): According to Google Cloud Blog, aligning raw material procurement with dynamic factory throughput cuts over-purchasing and immediately frees up frozen working capital.
Common misconceptions
“More data automatically guarantees high prediction accuracy.”
Reality: High-volume bad data generates inaccurate predictions due to systemic noise. Model accuracy relies primarily on the quality, relevance, and cleansing of the input features rather than sheer data volume.
“Machine learning models are set-and-forget solutions.”
Reality: Machine learning models experience data drift and performance degradation as real-world market dynamics or operational baselines shift. Continuous monitoring, retraining loops, and pipeline maintenance are mandatory to sustain predictive accuracy over time.
How Kyanon Digital applies Yield Prediction (ML)
Kyanon Digital implements yield prediction (ML) using Python-based machine learning frameworks, Apache Spark pipelines, and cloud-native MLOps infrastructure for manufacturing and supply chain clients across Vietnam and Singapore. Our engineering approach focuses on embedding predictive telemetry directly into existing enterprise resource planning (ERP) systems to provide operations teams with clear, probabilistic production metrics that reduce inventory overhead.
→ Explore our Machine Learning services







")




 Create project brief with AI
Create project brief with AI