What is the Feature Store?
A feature store is a centralized data management layer that orchestrates the ingestion, storage, and serving of machine learning features for both offline training and real-time inference workloads. It functions as the single source of truth for model inputs, ensuring mathematical consistency across experimental and production environments.
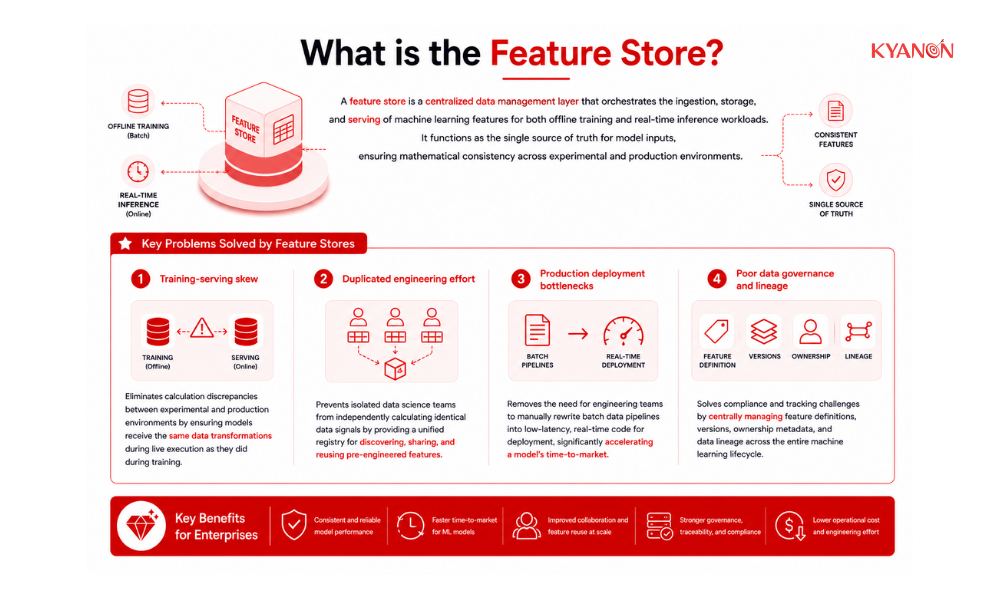
Key Problems Solved by Feature Stores
- Training-serving skew: Eliminates calculation discrepancies between experimental and production environments by ensuring models receive the same data transformations during live execution as they did during training.
- Duplicated engineering effort: Prevents isolated data science teams from independently calculating identical data signals by providing a unified registry for discovering, sharing, and reusing pre-engineered features.
- Production deployment bottlenecks: Removes the need for engineering teams to manually rewrite batch data pipelines into low-latency, real-time code for deployment, significantly accelerating a model’s time-to-market.
- Poor data governance and lineage: Solves compliance and tracking challenges by centrally managing feature definitions, versions, ownership metadata, and data lineage across the entire machine learning lifecycle.
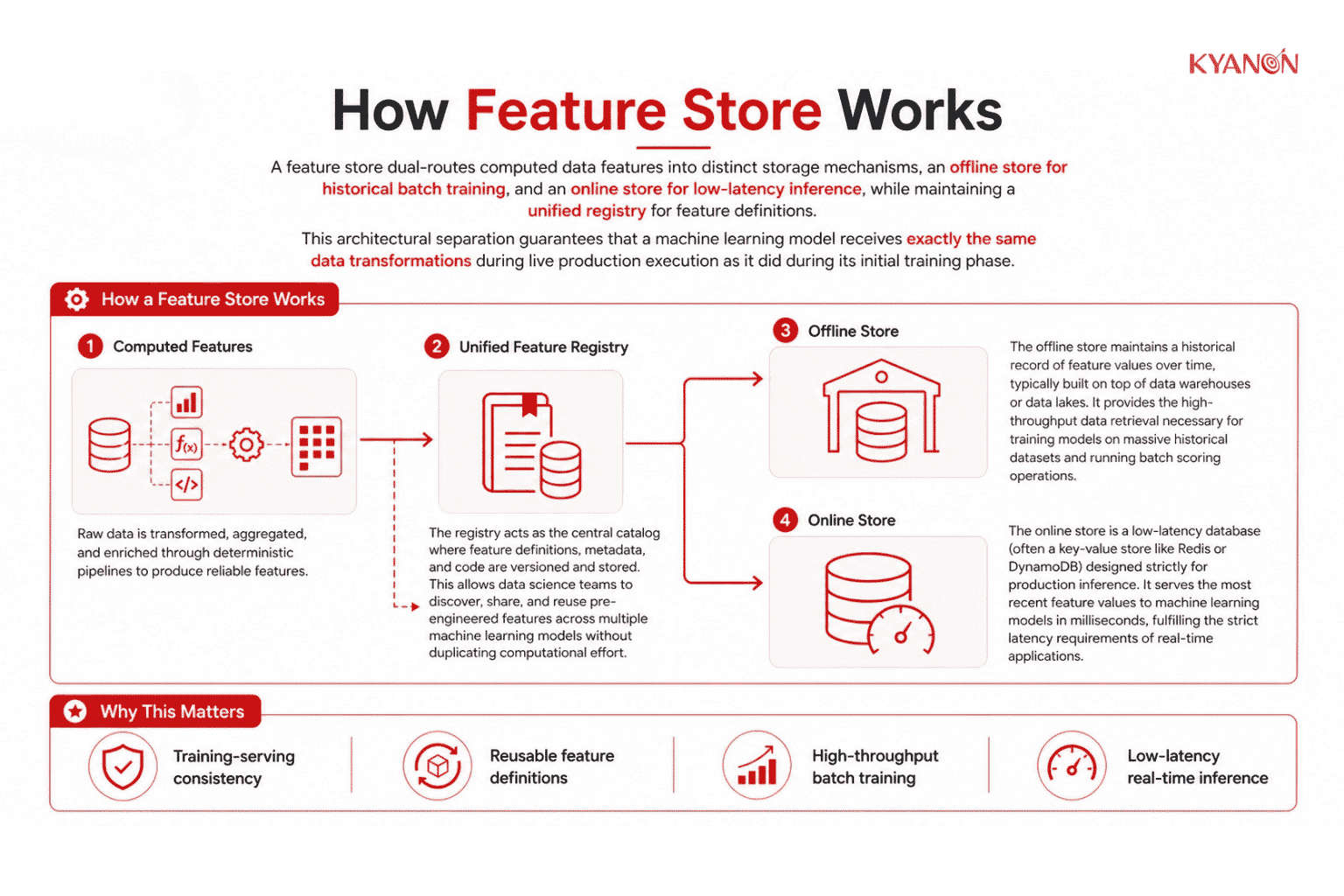
How Feature Store Works
A feature store dual-routes computed data features into distinct storage mechanisms, an offline store for historical batch training, and an online store for low-latency inference, while maintaining a unified registry for feature definitions. This architectural separation guarantees that a machine learning model receives exactly the same data transformations during live production execution as it did during its initial training phase.
Unified Feature Registry
The registry acts as the central catalog where feature definitions, metadata, and code are versioned and stored. This allows data science teams to discover, share, and reuse pre-engineered features across multiple machine learning models without duplicating computational effort.
Offline Store
The offline store maintains a historical record of feature values over time, typically built on top of data warehouses or data lakes. It provides the high-throughput data retrieval necessary for training models on massive historical datasets and running batch scoring operations.
Online Store
The online store is a low-latency database (often a key-value store like Redis or DynamoDB) designed strictly for production inference. It serves the most recent feature values to machine learning models in milliseconds, fulfilling the strict latency requirements of real-time applications.
Feature Store vs Data Warehouse
Both systems manage enterprise data, but they differ fundamentally in operational latency and their integration with the machine learning lifecycle.
|
Dimension |
Feature Store |
Data Warehouse |
|
Primary Workload |
ML model training and real-time inference |
Business intelligence and analytical reporting |
|
Latency Requirement |
Milliseconds (<10ms) for online serving |
Seconds to minutes (batch processing) |
|
Data Representation |
Curated ML signals and temporal vectors |
Relational tables and historical logs |
|
Consumption Layer |
ML models via API endpoints |
Analysts and BI tools via SQL |
|
Training-Serving Consistency |
Guaranteed through unified pipelines |
Manual implementation required |
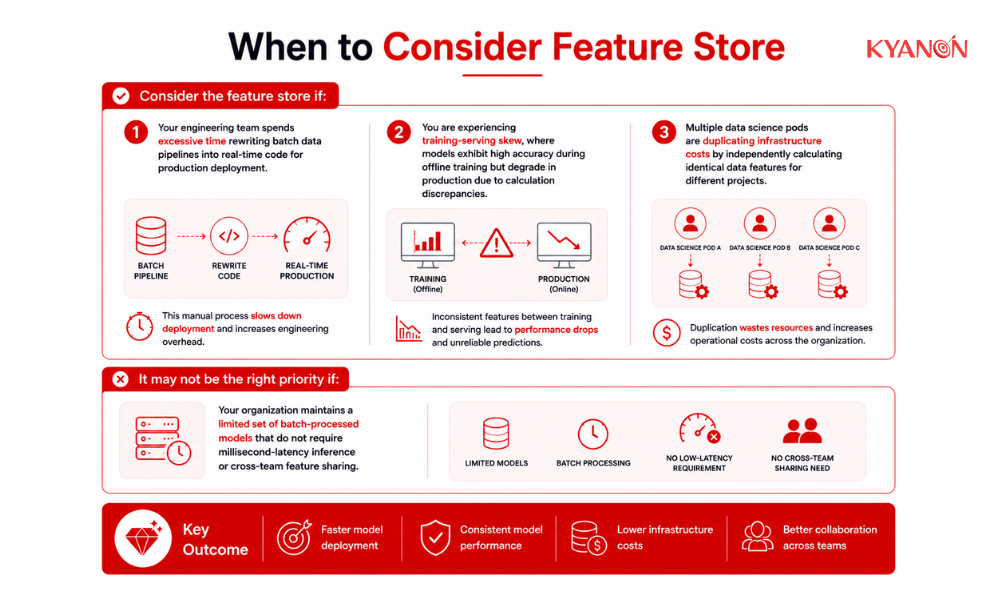
When to Consider Feature Store
Consider the feature store if:
- Your engineering team spends excessive time rewriting batch data pipelines into real-time code for production deployment.
- You are experiencing training-serving skew, where models exhibit high accuracy during offline training but degrade in production due to calculation discrepancies.
- Multiple data science pods are duplicating infrastructure costs by independently calculating identical data features for different projects.
It may not be the right priority if:
- Your organization maintains a limited set of batch-processed models that do not require millisecond-latency inference or cross-team feature sharing.
Why Feature Store Matters for Enterprise AI
Feature stores matter for enterprise AI because model performance depends on whether the same business signals can be trusted, reused, governed, and served across the full ML lifecycle. Without a shared feature layer, teams often rebuild the same features differently, which increases delivery time, model inconsistency, and production risk.
Gartner reported in 2025 that 63% of organizations either do not have or are unsure whether they have the right data management practices for AI, and Gartner predicts that organizations will abandon 60% of AI projects unsupported by AI-ready data through 2026. For CTOs and IT leaders, this makes feature governance, metadata, lineage, and production serving part of the AI operating model rather than a data engineering detail.
Uber’s Michelangelo platform shows why feature stores emerged in production ML environments: Uber allowed teams to add features into a shared feature store with metadata such as owner, description, and SLA, then consume those features online and offline by referencing a canonical feature name. This demonstrates how a feature store turns repeated feature work into shared infrastructure for model delivery.
Common Misconceptions
“It’s just a database or a data warehouse.”
Reality: A feature store actively manages the ingestion, transformation, and dual-serving of features (offline for training, online for inference). A standard data warehouse cannot handle the sub-10-millisecond lookup latency required by real-time production models.
“Feature stores are only necessary for massive enterprise teams.”
Reality: Smaller teams benefit heavily from feature stores through automated pipeline governance and feature reusability. Adopting this architecture early reduces technical debt and standardizes MLOps practices, even for organizations managing under 50 models.
“We should build our own feature store internally.”
Reality: Constructing a reliable feature store requires complex engineering to balance low-latency storage, point-in-time correctness, and scalable APIs. Relying on established platforms (such as Feast, Hopsworks, or managed cloud services) yields a lower total cost of ownership than maintaining custom infrastructure.
How Kyanon Digital Applies Feature Store
Kyanon Digital applies feature store principles when designing enterprise ML systems that require reusable features, model governance, and production integration across data platforms, applications, and business workflows.
For clients across Vietnam, Singapore-Malaysia, Thailand, ANZ, the US, and Nordic Europe, the approach typically connects data engineering, MLOps, model deployment, monitoring, and application integration so AI systems can move from prototype to production with clearer ownership and lower duplicated effort. Kyanon Digital’s machine learning service covers custom ML solutions, predictive analytics, ML model deployment, optimization, and continuous monitoring.
→ Explore our Machine Learning Development services.







")




 Create project brief with AI
Create project brief with AI