What is a model registry?
A model registry is a centralized cloud metadata repository used in MLOps (Machine Learning Operations) to catalog, track, version, and manage machine learning models as they transition from development to production.Think of it as an enterprise GitHub, but specifically built for machine learning. While GitHub tracks changes in software code, a model registry tracks the model’s architectural blueprints, its actual binary weights, its training lineage, and its current deployment status.
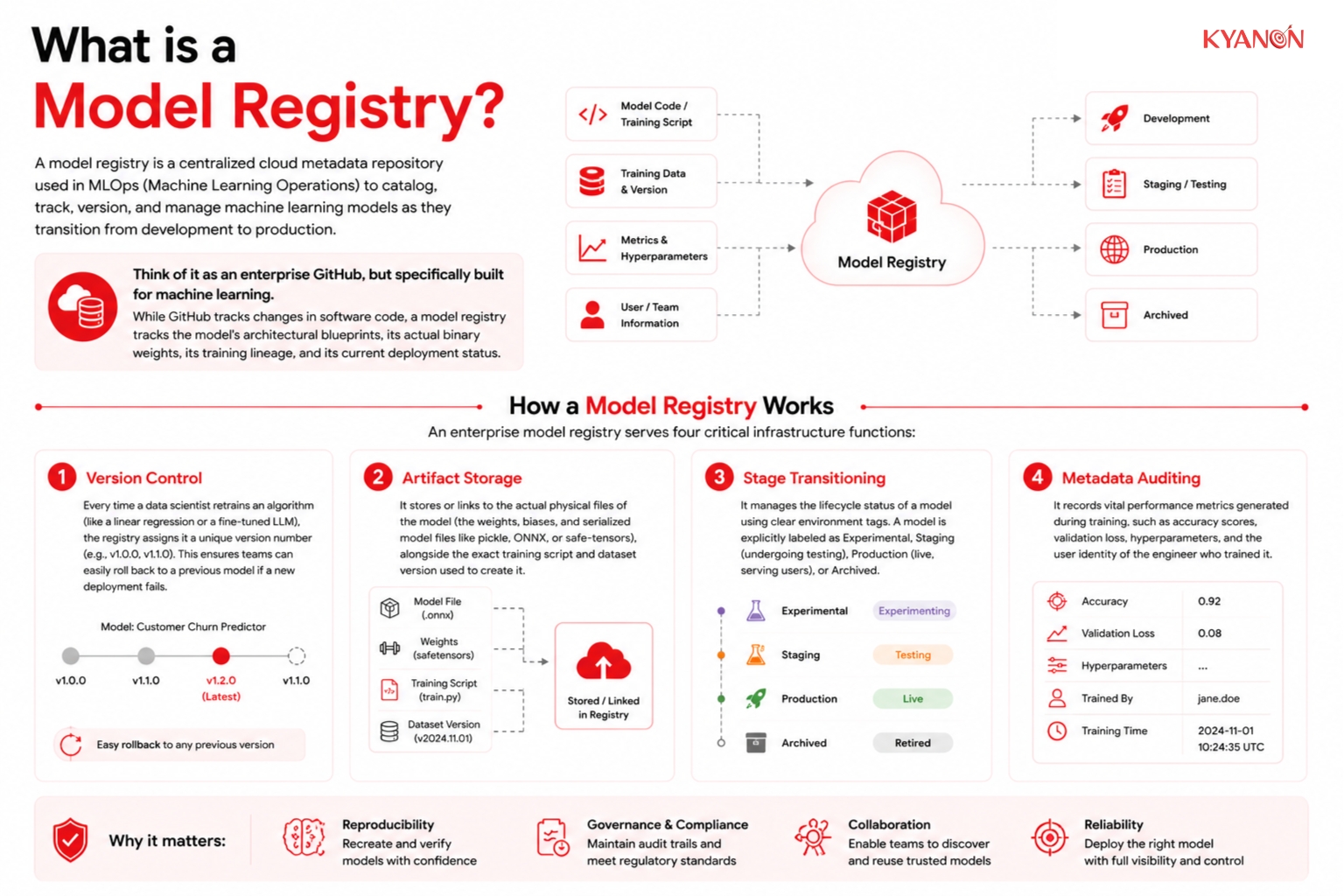
How a model registry works
An enterprise model registry serves four critical infrastructure functions:
Version Control
Every time a data scientist retrains an algorithm (like a linear regression or a fine-tuned LLM), the registry assigns it a unique version number (e.g., v1.0.0, v1.1.0). This ensures teams can easily roll back to a previous model if a new deployment fails.
Artifact Storage
It stores or links to the actual physical files of the model (the weights, biases, and serialized model files like pickle, ONNX, or safe-tensors), alongside the exact training script and dataset version used to create it.
Stage Transitioning
It manages the lifecycle status of a model using clear environment tags. A model is explicitly labeled as Experimental, Staging (undergoing testing), Production (live, serving users), or Archived.
Metadata Auditing
It records vital performance metrics generated during training, such as accuracy scores, validation loss, hyperparameters, and the user identity of the engineer who trained it.
Model Registry vs Feature Store
Both tools establish foundational control over the Machine Learning Operations (MLOps) pipeline, but they govern completely separate architectural phases.
|
Dimension |
Model Registry | Feature Store |
| Asset managed | Trained software binaries (the algorithm) |
Input data structures (the features) |
|
Pipeline phase |
Post-training lifecycle management | Pre-training preparation and inference data serving |
| Primary consumer | CI/CD pipelines and deployment systems |
Model training scripts and inference APIs |
|
Versioning target |
Model weights, hyperparameters, and metrics | Data transformations and mathematical schemas |
| Core objective | Ensuring algorithmic deployment traceability |
Ensuring training-serving data consistency |
When to consider a model registry
Consider a model registry if:
- Your engineering team is struggling to trace production prediction errors back to the specific training dataset and code version that generated the faulty model.
- Your organization requires strict audit trails for regulatory compliance to prove exactly which version of an algorithm made a specific automated decision on a given date.
- You are scaling your AI operations and need to replace manual model file transfers with automated, state-driven CI/CD deployment pipelines.
It may not be the right priority if:
- Your team relies exclusively on third-party, pre-trained AI APIs managed entirely by external vendors where you do not host, train, or govern custom algorithms internally.
Why a model registry matters for enterprise data systems
As companies move from managing one or two simple models to running hundreds of automated workflows across various departments, a centralized registry becomes a core compliance and operational requirement.
- Enforcing governance and audit trails: In highly regulated industries (e.g., banking or healthcare), an enterprise must be able to prove to auditors exactly how a live AI model was trained. The registry links the live production model back to its raw training parameters and validation data, creating a transparent audit trail.
- Preventing production downtime: Automated CI/CD (Continuous Integration/Continuous Deployment) pipelines pull directly from the registry. Instead of an engineer manually uploading a file to a server, software systems query the registry to automatically deploy the model tagged as Latest_Production.
- Cross-team collaboration: It breaks down data science silos. An engineering team building a LangChain agent can query the central registry to find and connect to an approved, fine-tuned LLM created by a completely separate data science team.
Popular model registry tools
Most enterprise data systems leverage one of these industry-standard solutions:
- MLflow model registry: The most widely adopted open-source tool, deeply integrated into platforms like Databricks.
- W&B (Weights & Biases) registry: Highly popular for deep learning and LLM tracking.
- Cloud-native registries: Built directly into major cloud platforms, such as Amazon SageMaker Model Registry, Google Vertex AI Model Registry, and Azure ML Registry.
Common misconceptions
It is just a glorified AWS S3 bucket for storing our model files
Reality: A storage bucket simply holds raw files, while a registry binds those files to reproducible execution data. A true model registry acts as a metadata ledger that links the model artifact to the exact training code version, the specific dataset used, and structural dependencies, giving teams the exact blueprint needed to audit or recreate the system.
Versioning is handled automatically just by saving files with new names
Reality: Naming files manually (e.g., model_v2_final.pkl) or relying on basic cloud file versioning is insufficient for automated production. A model registry manages semantic, state-aware versioning, ensuring that updating a model’s state to “Production” automatically triggers API route switches or downstream CI/CD deployment pipelines without risky manual transfers.
A model registry monitors real-time production performance
Reality: Registries handle static model assets, not dynamic production data streams. Identifying Model Drift, concept drift, or sudden API latency spikes is the specific job of a Model Monitoring system. The registry simply provides the definitive record of what is running; separate monitoring tools track how that specific version is performing in the real world.
You only need a model registry for massive deep learning networks
Reality: Simple models, such as linear regressions or decision trees, require exact registry governance to prevent operational damage. Enterprise compliance, audit trails, and automated deployment pipelines require every single revenue-impacting asset to be formally registered, regardless of its underlying mathematical complexity.
How Kyanon Digital applies a model registry
Kyanon Digital sets up model registries as a foundational component of enterprise MLOps infrastructure for clients across Vietnam, Singapore, ANZ, and the US. Our engineering teams integrate these centralized ledgers to provide organizations with complete governance and traceability over their AI model lifecycles, ensuring strict compliance and enabling highly reliable, automated deployment pipelines that directly reduce long-term maintenance costs.
Explore our Cloud and AI services:







")




 Create project brief with AI
Create project brief with AI