What is Feature Engineering?
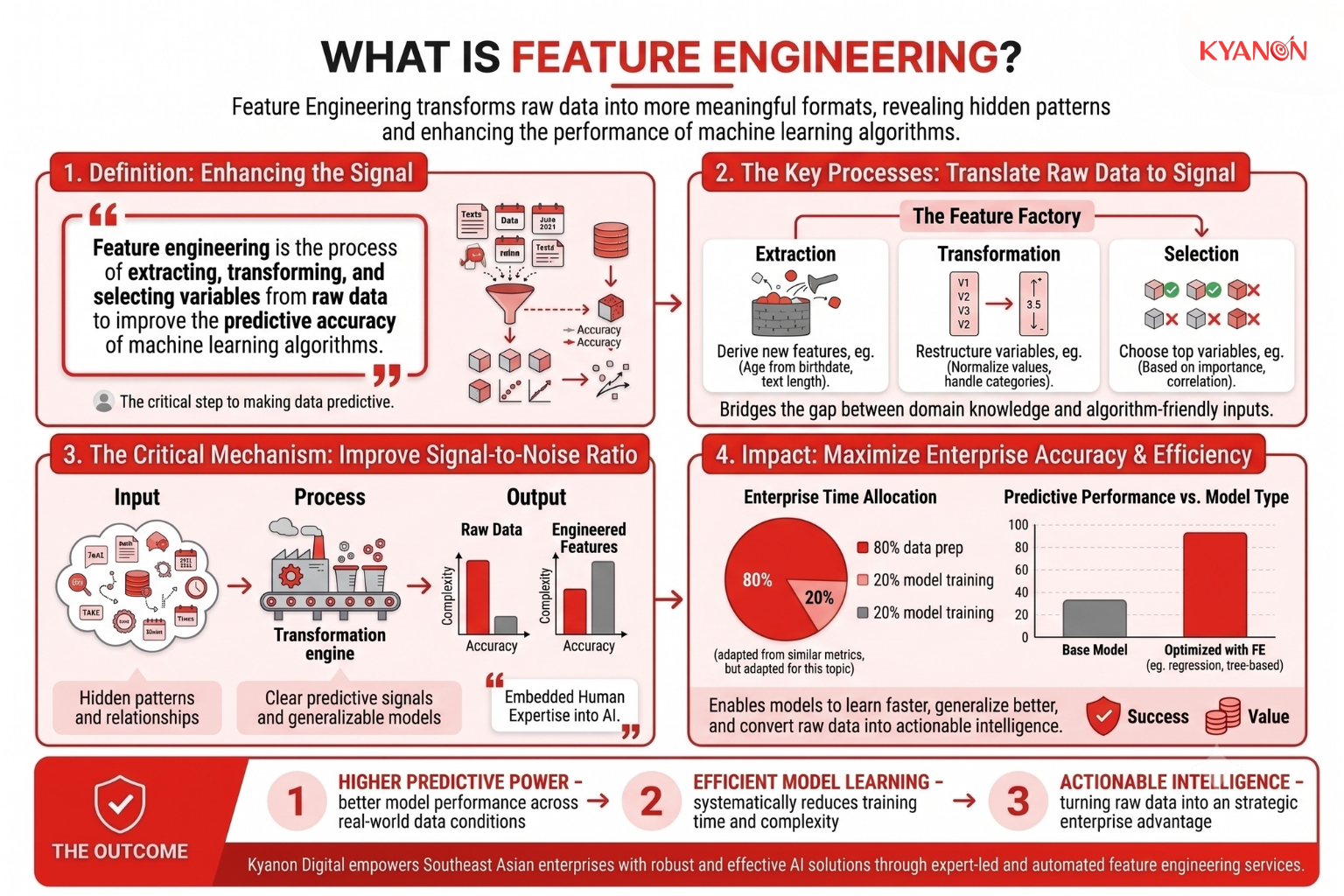
Feature engineering is the process of extracting, transforming, and selecting variables from raw data to improve the predictive accuracy and efficiency of machine learning models. It bridges the gap between raw datasets and mathematical algorithms by translating domain-specific knowledge, business logic, and real-world context into quantifiable signals that models can interpret more effectively.
Rather than changing the underlying information itself, feature engineering focuses on how data is represented. By restructuring raw inputs into more meaningful formats, it helps machine learning algorithms identify patterns, relationships, and predictive signals that might otherwise remain hidden.
At its core, feature engineering involves creating useful features from existing data, transforming variables into formats suitable for model training, and removing redundant or low-value inputs. This process improves the signal-to-noise ratio within a dataset, enabling models to learn more efficiently, generalize better, and achieve higher predictive performance.
Often considered one of the most important stages of the machine learning lifecycle, feature engineering serves as a critical mechanism for embedding human expertise directly into AI systems, allowing organizations to convert raw data into actionable intelligence.
How Feature Engineering Works
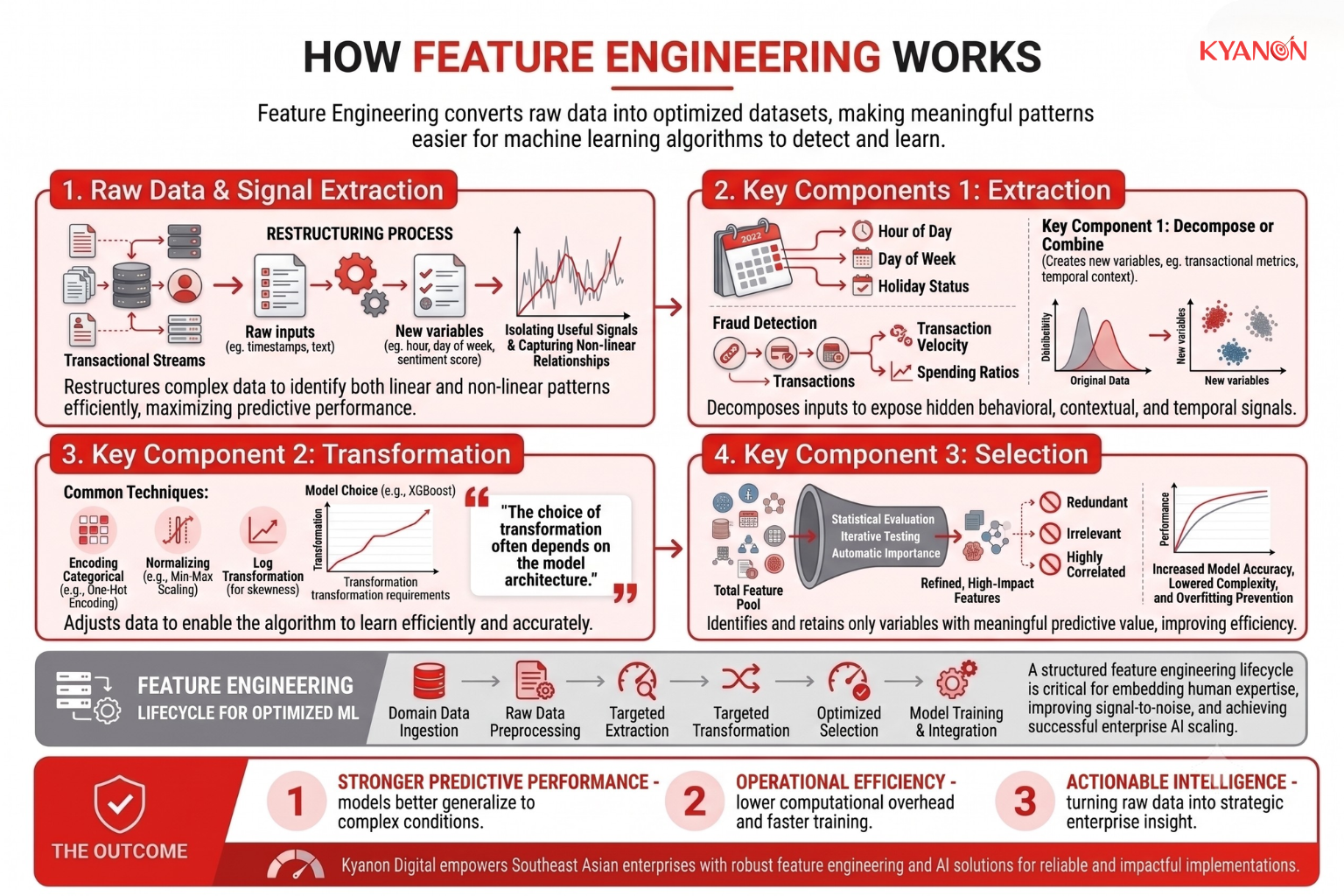
Feature engineering works by restructuring raw data into a format that makes meaningful patterns easier for machine learning algorithms to detect and learn. Rather than feeding unprocessed data directly into a model, the process extracts useful signals, transforms data into mathematically suitable representations, and removes low-value variables that may introduce noise or complexity.
At a high level, feature engineering follows a structured pipeline that converts raw inputs into an optimized dataset for model training. By improving how information is represented, feature engineering helps algorithms identify both linear and non-linear relationships more efficiently, leading to stronger predictive performance and better generalization.
Feature Extraction
Feature extraction creates new variables from existing data to expose hidden behavioral, contextual, or temporal patterns.
For example, a raw timestamp may be decomposed into features such as hour of day, day of week, or holiday status. In fraud detection systems, transaction histories can be transformed into metrics such as transaction velocity or spending ratios. For text data, feature extraction may generate sentiment scores, keyword frequencies, or entity indicators that convert unstructured content into machine-readable signals.
By isolating relevant characteristics from raw inputs, feature extraction helps models focus on information that is most likely to influence predictions.
Feature Transformation
Feature transformation modifies the scale, format, or distribution of data so it aligns with the mathematical requirements of a machine learning model.
Common techniques include encoding categorical values into numerical representations, normalizing numerical ranges, and reshaping highly skewed distributions through logarithmic transformations. The choice of transformation often depends on the model architecture. Distance-based algorithms may require standardized inputs, while tree-based models such as XGBoost and Random Forests often benefit more from transformations that improve data distribution rather than scaling.
The goal is to ensure that data is represented in a form that enables the algorithm to learn efficiently and accurately.
Feature Selection
As new features are created, datasets can quickly become large and complex. Feature selection identifies and retains only the variables that contribute meaningful predictive value while removing redundant, irrelevant, or highly correlated features.
This can be achieved through statistical evaluation, iterative model-based testing, or algorithms that automatically determine feature importance during training. By reducing unnecessary variables, feature selection improves model efficiency, lowers computational overhead, and helps prevent overfitting.
Together, extraction, transformation, and selection create a refined dataset that maximizes signal while minimizing noise, allowing machine learning models to learn more effectively from available data.
Feature Engineering vs AutoML
Both approaches aim to optimize the inputs fed into predictive models, but they differ significantly in their reliance on human domain expertise versus brute-force computation.
|
Dimension |
Feature Engineering | AutoML |
| Domain logic integration | High |
Low |
|
Computational cost |
Low | High |
| Model interpretability | High |
Low |
|
Risk of spurious correlations |
Low | High |
| Best for | Complex transactional/tabular data |
Rapid baseline model generation |
When to Consider Feature Engineering
Consider Feature Engineering if:
- Your predictive models exhibit stagnant accuracy plateaus despite significant increases in the volume of raw training data.
- You are deploying algorithms in regulated environments where every input variable must map directly to explainable, auditable business logic.
- Your data science infrastructure is standardizing around a central Feature Store to share calculated variables across multiple production models.
It may not be the right priority if:
- Your model relies exclusively on raw, unstructured sensory data, such as high-resolution images or audio files, where neural networks handle representation learning natively.
Why Feature Engineering Matters for Enterprise ML
The commercial viability of predictive analytics depends heavily on the quality of the features used to train machine learning models. Regardless of how sophisticated an algorithm may be, its ability to generate accurate and actionable predictions is constrained by the quality of the underlying data representation. Feature engineering helps transform raw data into meaningful signals that better reflect real-world business behavior, enabling models to identify patterns that would otherwise remain hidden.

For enterprise organizations, the impact extends beyond model accuracy. Effective feature engineering improves fraud detection, demand forecasting, customer segmentation, recommendation systems, and operational analytics by making predictive relationships easier to learn and generalize. Well-designed features can often deliver greater performance gains than switching to a more complex algorithm.
Common Misconceptions
Deep Learning completely eliminates the need for manual feature creation
While true for raw sensory data like images, manual feature engineering remains strictly essential for tabular and transactional data. Deep Learning architectures struggle to implicitly learn complex relational concepts or domain-specific business rules from raw numbers without targeted mathematical transformations.
Generating thousands of automated features gives the model more options to find patterns
Generating excessive, uncurated features exposes models to the curse of dimensionality and inflates training times drastically. It increases the risk of spurious correlations, leading to bloated, fragile models that overfit to noise rather than identifying repeatable business signals.
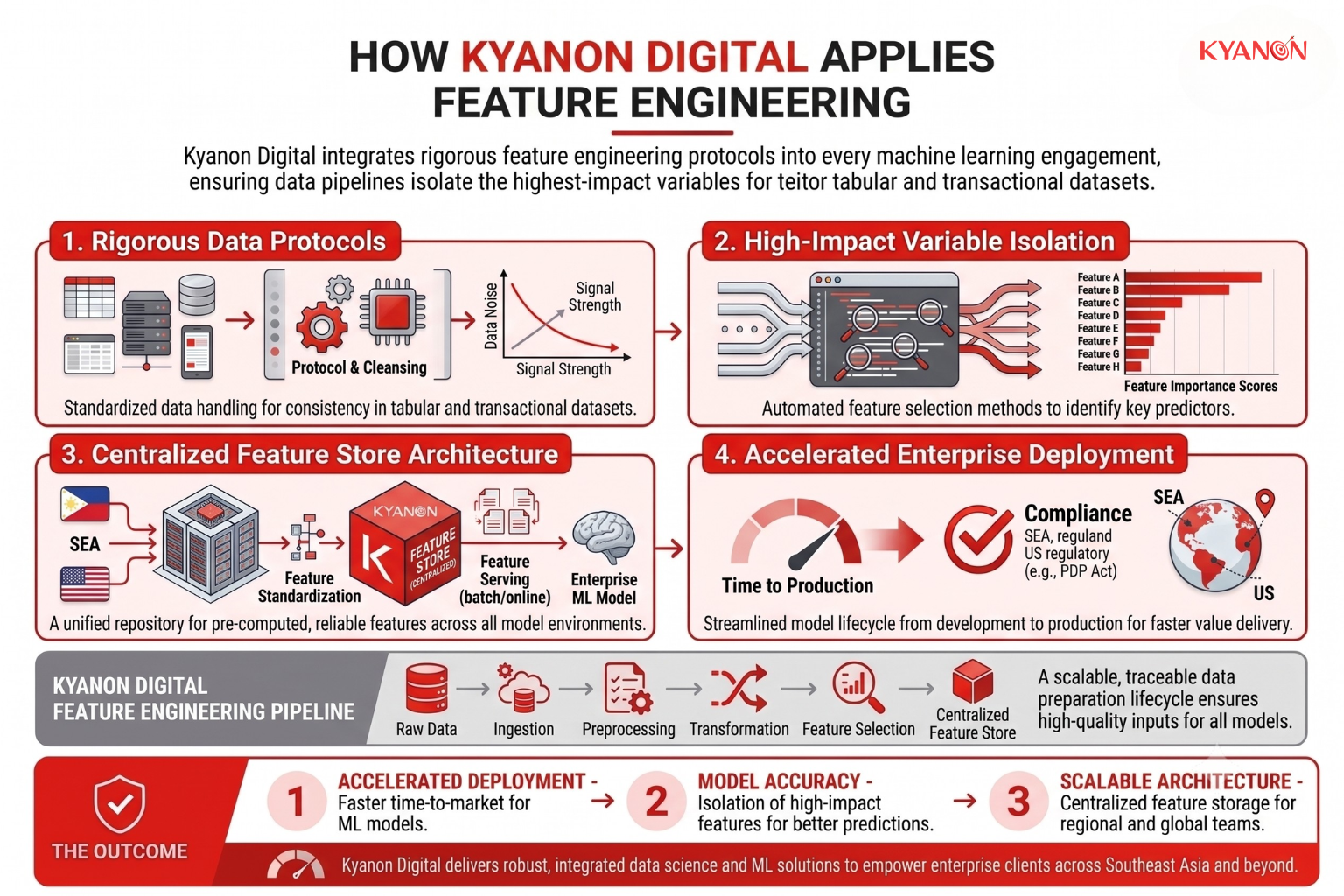
How Kyanon Digital Applies Feature Engineering
Kyanon Digital integrates rigorous feature engineering protocols into every machine learning engagement, ensuring data pipelines isolate the highest-impact variables for tabular and transactional datasets. Our data science teams utilize centralized architecture to standardize and serve features across environments, accelerating accurate model deployment for enterprise clients across Southeast Asia and the US.
→ Explore our Machine Learning Development services.







")




 Create project brief with AI
Create project brief with AI