What is Hyperparameter Tuning?
Hyperparameter tuning is the systematic process of adjusting the external configuration settings of a machine learning algorithm to minimize generalization error and maximize predictive performance. It dictates how the model learns rather than what it learns from the data itself.
Unlike model parameters (weights and biases that are adjusted during training), hyperparameters are external controls set by the engineering team, meaning that poor choices at this stage cannot be corrected by more training data or longer compute runs.
Parameters vs. Hyperparameters
| Feature | Parameters (Internal) |
Hyperparameters (External) |
|
Source |
Learned automatically from training data. | Set manually by the practitioner. |
| Timing | Updated continuously during training. |
Determined completely before training starts. |
|
Examples |
Neural network weights, biases, split points. |
Learning rate, batch size, tree depth. |
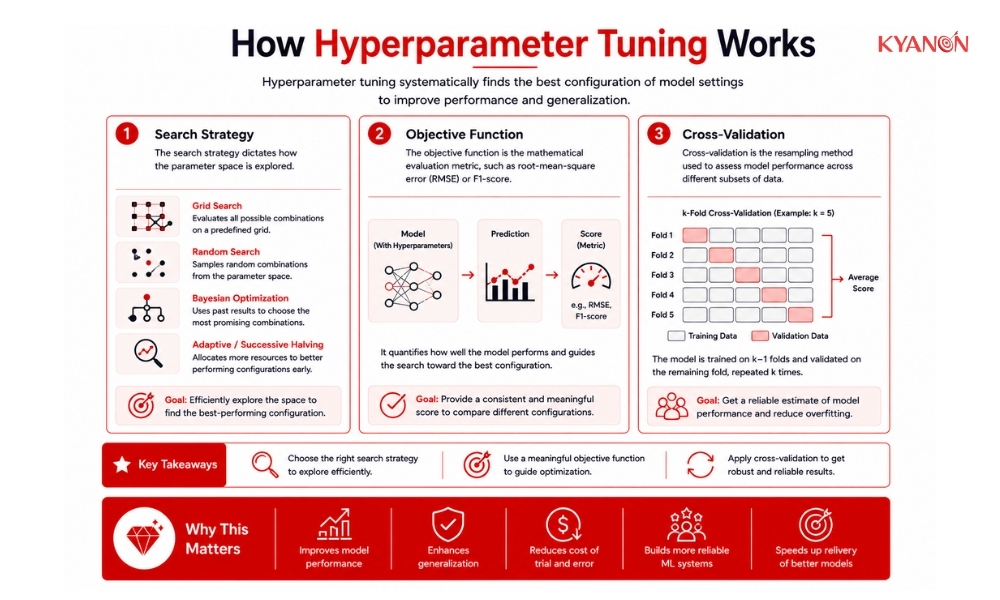
How Hyperparameter Tuning Works
Hyperparameter tuning works by searching a defined multi-dimensional configuration space of an algorithm to identify the combination of settings that minimizes a model’s target loss function on unseen data. This process maps out architectural boundaries, step sizes, and regularization penalties to find an optimal equilibrium point between model bias and variance.
Search Strategy
The search strategy dictates how the parameter space is explored. Algorithms like Bayesian optimization or randomized search systematically test parameter combinations to maximize efficiency and minimize the required computational overhead.
Objective Function
The objective function is the mathematical evaluation metric, such as root-mean-square error (RMSE) or F1-score. It establishes a quantitative benchmark to score and compare each hyperparameter configuration during the tuning process.
Cross-Validation
Cross-validation is the resampling method used to assess model performance across different subsets of data. It ensures that the selected hyperparameters generalize accurately to independent, real-world datasets rather than simply memorizing the training split.
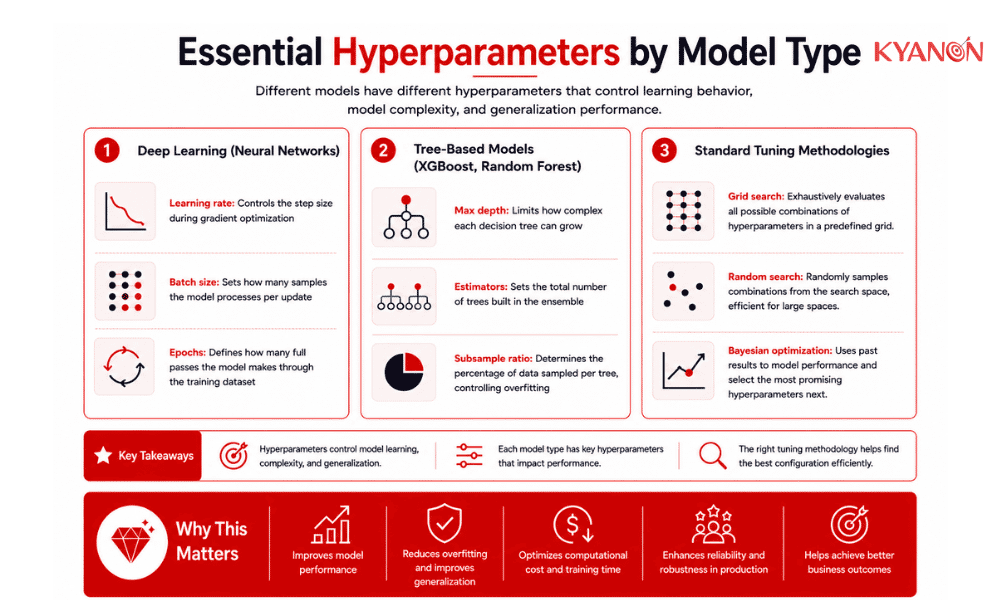
Essential Hyperparameters by Model Type
Deep Learning (Neural Networks)
- Learning rate: Controls the step size during gradient optimization
- Batch size: Sets how many samples the model processes per update
- Epochs: Defines how many full passes the model makes through the training dataset
Tree-Based Models (XGBoost, Random Forest)
- Max depth: Limits how complex each decision tree can grow
- Estimators: Sets the total number of trees built in the ensemble
- Subsample ratio: Determines the percentage of data sampled per tree, controlling overfitting
Standard Tuning Methodologies
- Grid search: Evaluates every predefined combination exhaustively. It is straightforward to implement but scales exponentially; a search across five hyperparameters with five values each requires 3,125 training runs. For complex models, this is computationally prohibitive.
- Random search: Samples configurations randomly within defined bounds. It consistently finds comparable or better results than grid search in significantly less compute time, particularly when only a subset of hyperparameters meaningfully affects performance.
- Bayesian optimization: Uses results from previous trials to build a probabilistic model of which configurations are likely to perform well, then targets the next most promising region of the search space. It is the most computationally efficient method for complex models with expensive training runs, reaching equivalent performance in far fewer trials than either grid or random search.
Hyperparameter Tuning vs AutoML
Both hyperparameter tuning and AutoML optimize model configurations, but they operate at different levels of automation and require different levels of team involvement to govern the outputs.
|
Dimension |
Hyperparameter Tuning | AutoML |
| Scope | Optimizes configuration settings for a chosen model architecture |
Searches across architectures, features, and configurations simultaneously |
|
Team control |
Engineering team defines the search space and evaluates results | Automated pipeline selects model type and configuration with minimal human input |
| Compute cost | Scales with search strategy, Bayesian methods are cost-efficient |
Higher per run due to broader search scope |
|
Transparency |
Full visibility into which settings were tested and why | Output model may be difficult to interpret or audit |
| Production fit | Team validates the final configuration before deployment |
Requires additional review to ensure outputs meet governance requirements |
|
Best for |
Teams with a defined model architecture optimizing for a specific business metric | Teams that need rapid model selection across a large problem space |
| Risk profile | Controlled, changes are scoped to configuration settings |
Higher, architecture changes can introduce unexpected behavior in production |
When to Consider Hyperparameter Tuning
Consider hyperparameter tuning if:
- Your baseline machine learning models underperform on validation data despite utilizing high-quality, fully pre-processed datasets.
- You deploy models to high-stakes production environments where a fractional increase in predictive accuracy translates to direct financial impact.
- Your current model exhibits high variance between training and testing scores, indicating an immediate requirement for optimized regularization parameters.
It may not be the right priority if:
- Your data infrastructure remains immature, and engineering teams are actively resolving data pipeline reliability, missing values, or basic unstructured data ingestion.
Why Hyperparameter Tuning Matters for Enterprise AI
Hyperparameter tuning is the difference between a model that performs in controlled testing and one that delivers consistent results against a business metric in production.
Systematic hyperparameter tuning yields accuracy gains of up to 25% and F1-score improvements of up to 30%, depending on the model and dataset (Yuvaraj, IJRASET, 2025). For enterprise deployments, where ML outputs feed pricing decisions, fraud scoring, demand forecasting, or customer segmentation, performance differences at this magnitude translate directly into measurable business outcomes.
Common Misconceptions
“Grid search is the best and most thorough way to tune our models.”
Reality: Grid search evaluates every single combination of a predefined parameter set, making it highly inefficient and computationally expensive. Modern approaches like Bayesian optimization or randomized search consistently yield superior configurations in a fraction of the compute time.
“Tuning can fix a flawed or inaccurate model.”
Reality: Hyperparameter tuning functions strictly as the final optimization layer. It cannot correct a model suffering from poor data quality, incorrect target definitions, or misframed business logic.
“More tuning trials always yield better production results.”
Reality: Running continuous optimization trials after a model converges leads to wasted compute budget. Exhaustive searching frequently causes hyperparameter overfitting, where the configuration becomes entirely specific to the validation split rather than generalizing to unseen data.
How Kyanon Digital Applies Hyperparameter Tuning
Kyanon Digital includes hyperparameter tuning as a defined stage within ML model development for enterprise clients across Vietnam, Singapore, Malaysia, Thailand, ANZ, the US, and Nordic Europe. Within the analysis & augment service line, specifically under custom ML model deployment and AI-driven decision engines, tuning is scoped to each client’s model architecture, target business metric, training data volume, and compute budget.
The team selects the search strategy based on deployment context:
- Bayesian optimization for complex models with expensive training runs and random search for faster iteration on simpler architectures.
- Validation strategy is treated as a governance requirement, not a technical preference, particularly for clients in retail, banking, and logistics, where ML outputs feed directly into operational decisions.
Kyanon Digital’s data governance and warehousing capabilities ensure that the data tuning runs on is representative, permissioned, and consistent with production conditions before the process begins.
→ Explore our Analyse & Augment services.







")




 Create project brief with AI
Create project brief with AI