

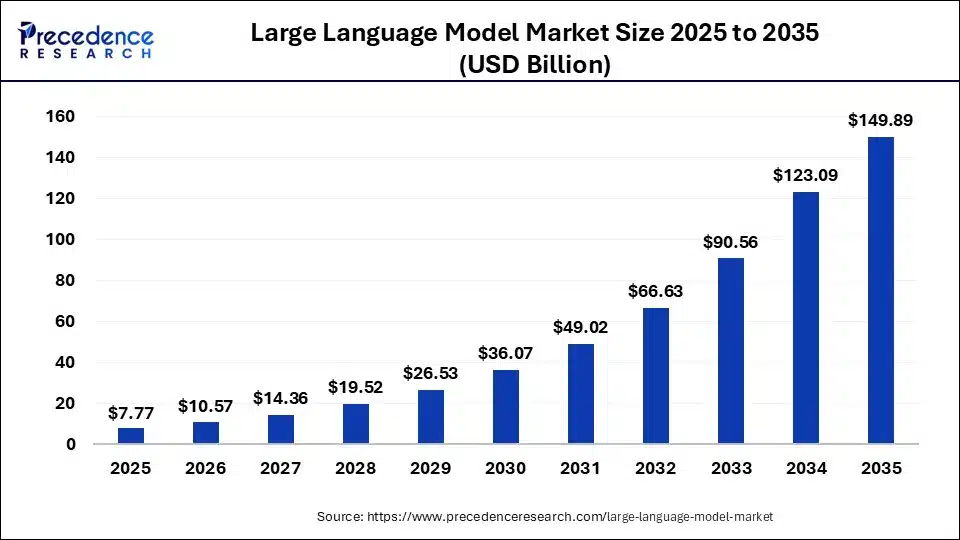
Enterprise AI adoption has crossed a point of no return. According to McKinsey’s State of AI 2025 report, 72% of organizations now use generative AI, up from just 33% in 2024. The global large language model market size is calculated at USD 7.77 billion in 2025 and is predicted to increase from USD 10.57 billion in 2026 to approximately USD 149.89 billion by 2035, expanding at a CAGR of 34.44% from 2026 to 2035. (Precedence Research)
The boardroom decision is made. The business case is approved. Now comes the harder question that every procurement team, CFO, and technical lead is quietly asking: how much does this actually cost, who charges fairly, what are the hidden fees, and are we about to overpay?
This guide gives you the real numbers, broken down by cost driver, deployment model, and technical approach. No vague ranges. No vendor spin. Just defensible figures to bring into your internal planning.
The 4 real LLM cost drivers (and why enterprises get surprised)
Before you fixate on model licensing or API pricing, you should know that the model is rarely the largest expense. The real LLM cost structure is distributed across four drivers that most enterprises systematically underestimate.

The 4 real LLM cost drivers
This is the most underestimated phase. Enterprises often assume their data is “AI-ready,” only to find it trapped in legacy silos or unstructured formats. Gartner‘s guidance on enterprise LLM adoption emphasizes that enterprise data becomes a key differentiator, necessitating data preparation, quality checks, versioning, and overall management to meet fine-tuning requirements.
The reality: You aren’t just paying for storage; you are paying for Data Engineering.
The cost sink:
- Cleaning & labeling: Converting messy PDFs, SQL tables, and Slack logs into a clean “Vector Database” (RAG) requires massive human-in-the-loop hours.
- Pipeline maintenance: Data drifts. If your internal documentation changes, your LLM needs a real-time ingestion pipeline, which costs 2–3x more than a one-time upload.
The surprise: Most firms spend $4 on data prep for every $1 spent on the model itself.
Inference & compute: The “Success Tax”
The economics of LLMs are non-linear. What works in a pilot (POC) often breaks the budget at scale.
1M vs. 10M Requests:
- At 1M requests/month, managed APIs (like OpenAI/Anthropic) are cheap and efficient.
- At 10M+ requests/month, “Token Burn” becomes a massive liability. If your prompt includes a long system instruction (Context Window), you are paying for those same thousands of tokens every single time a user clicks “Enter.”
Scaling economics: To save money at scale, enterprises must invest in Prompt Engineering (shortening inputs) or Model Distillation (training a tiny 7B model to do the job of a 175B model).
Infrastructure: The “Buy vs. Build” dilemma
Choosing between a Managed API and Self-Hosting is a capital expenditure (CapEx) decision, not just a technical one.
Managed APIs (SaaS): Zero upfront cost, but high variable cost. You are at the mercy of the provider’s pricing and uptime.
Self-Hosted (Private Cloud):
- An NVIDIA A100/H100 instance typically runs between $3,000–$9,000/month per node.
- The trap: You pay for the GPU even when it’s idle. Unless you have 80%+ utilization, self-hosting is often more expensive than APIs due to the “Idle Compute Tax” and the need for specialized DevOps engineers to manage the stack.
Governance & Compliance: The “Regulatory surcharge”
In highly regulated sectors like Finance or Healthcare, the cost of “doing it right” can double the project budget.
- The surcharge: It’s not a line item from the vendor; it’s the cost of safety and legal friction.
- PII masking: Software to automatically scrub Social Security numbers or patient names before they hit the LLM.
- Auditability: Storing every prompt/response for 7 years to meet SEC or HIPAA requirements.
- Red teaming: Hiring specialists to try and “break” the model to ensure it doesn’t give out legal advice or leak trade secrets.
The framing: If your budget is $100k, don’t look for a $100k model. Look for a $15k model and keep $85k for the plumbing, the people, and the protection.
Build vs. Buy vs. Partner: TCO Comparison
When evaluating LLM strategy, the “Build” vs. “Buy” vs. “Partner” decision determines your Total Cost of Ownership (TCO) and long-term technical debt. Most enterprises start with Buy for quick wins, but realize that Partnering often offers the best balance of speed and data control without the astronomical overhead of building a proprietary foundation.
LLM Strategy: TCO Decision Matrix:
|
Dimension |
Build In-House (Custom Model) | Buy Off-the-Shelf (SaaS/API) | Partner with Specialist (Hybrid/Managed) |
| Upfront Cost | Highest: Requires AI researchers ($300k+ salaries) & massive GPU clusters. | Lowest: Minimal setup; usually a “pay-per-token” or monthly subscription. |
Mid: Initial professional services fee + recurring platform costs. |
|
Customization |
Full: You own the weights, the architecture, and the fine-tuning logic. | None: You are limited to the vendor’s prompt window and “system instructions.” | High: Tailored RAG pipelines and fine-tuning on your specific industry data. |
| Time to Deploy | 12–18 Months: From data collection to production-ready latency. | Days: Just get an API key and connect it to your UI. |
8–16 Weeks: Iterative sprints to build a specialized, secure application. |
|
Hidden Cost Risk |
Highest: Research failure, model drift, and high DevOps turnover. | Medium: “Token creep” where high usage leads to unpredictable monthly bills. | Lowest: Fixed-scope delivery and managed infrastructure maintenance. |
| Data Control | Full: 100% On-premise/VPC; no data ever leaves your firewall. | Low: Data is processed by a third party (OpenAI, Google, etc.). |
Configurable: Specialist sets up a private instance within your cloud. |
The “Build” burden: Talent & infrastructure
Building in-house isn’t just about the A100 GPUs; it’s about the “Talent Tax.” You need Machine Learning Engineers, Data Scientists, and MLOps specialized in distributed training.
- The TCO trap: You spend 70% of your time on infrastructure plumbing rather than business value. If the model underperforms, you’ve sunk millions into a depreciating asset.
The “Buy” burden: The token tax & lock-in
Buying an API feels cheap at first, but it creates “Vendor Gravity.”
- The TCO trap: As you scale to 10M+ requests, your variable costs skyrocket. Furthermore, if the vendor updates the model version (e.g., GPT-4o to GPT-5), your prompts might “break,” forcing an expensive manual re-alignment of your entire system.
The “Partner” advantage: The middle path
Partnering with an AI specialist/boutique firm allows you to leverage pre-built frameworks (like LangChain or Haystack) while keeping the solution inside your own Azure/AWS/GCP environment.
- The TCO win: You get the speed of “Buy” with the security of “Build.” The specialist handles the “Data Readiness” (the 40–70% cost driver) so your internal team can focus on the user experience.
The Strategic Verdict
- Build if AI is your product (e.g., you are a tech company like Bloomberg building BloombergGPT).
- Buy for generic productivity tasks (e.g., summarizing internal emails or basic chatbots).
- Partner for core business workflows (e.g., medical claims processing, legal discovery, or financial forecasting) where accuracy and data privacy are non-negotiable.
Fine-Tuning vs. RAG vs. Prompt Engineering: Cost per Approach
The total cost of ownership (TCO) for these approaches is determined by where the financial weight is placed: Prompt Engineering is nearly all OpEx (operating expenses), Fine-Tuning is heavily front-loaded CapEx (capital expenditure), and RAG sits in the middle with significant infrastructure overhead
Cost comparison matrix:
|
Approach |
Upfront Dev Cost | Monthly Infrastructure | Unit Inference Cost | Talent/Skills Needed |
| Prompt Engineering | $5K – $20K | Lowest ($0) | Standard (API rates) |
Low (Domain experts) |
|
RAG |
$50K – $200K | Mid ($1K – $10K+) | Higher (Prompt + Context) | Medium (Data Engineers) |
| Fine-Tuning | $100K – $500K | High ($2K – $20K) | Potentially Lower (via SLM) |
High (ML/Data Science) |
Disclaimer: All pricing information in this table is for reference purposes only.
Prompt engineering: The “Low-risk” entry
This is the baseline for nearly all projects. You are essentially paying for experimentation time rather than deployment or training.
- Cost profile: Almost entirely variable. You only pay for the tokens you use.
- Hidden costs: As prompt complexity grows (e.g., adding many “few-shot” examples), your per-query cost increases because you are sending more tokens every single time.
- Best for: Prototyping, content generation, and general reasoning tasks. (Research Gate)
RAG: The “Knowledge” tax
RAG shifts spending from “training” to ongoing infrastructure.
- Infrastructure costs: You must pay for a Vector Database (e.g., Pinecone, Weaviate), hosting for embedding models, and retrieval engines, which can range from $500 to $10,000+/month at scale.
- Higher inference costs: Each query is “heavier” because it includes the user question plus retrieved documents, leading to higher token consumption compared to a base prompt.
- Maintenance: Requires dedicated engineers to manage data pipelines and “chunking” strategies.
Gartner has noted that enterprises are employing RAG to customize LLMs without the full cost and complexity of fine-tuning, and the adoption of this pattern is accelerating across regulated industries.
Best for: Internal knowledge management, customer support with proprietary product data, compliance question answering, document-heavy workflows.
Fine-Tuning: The “Front-Loaded” Heavyweight
Fine-tuning flips the cost structure by requiring a massive upfront investment in data prep and compute, but it can potentially lower long-term costs.
- Training costs: Significant spend on high-quality labeled data and GPU time
- Potential saving: By “teaching” a smaller, cheaper model (like a 7B parameter model) to perform as well as a larger one, you can reduce your per-query inference cost significantly.
- Maintenance debt: Fine-tuning is fragile. If your data changes, you must re-train the model, incurring the high training cost all over again. (DEV Community)
By 2027, Gartner predicts organizations will implement small, task-specific AI models at usage volumes three times higher than general-purpose LLMs – which means the fine-tuning economics become more favorable as organizations mature. But entering this path without the supporting infrastructure is one of the most common causes of LLM project failure.
Best for: Highly specialized domains with proprietary terminology (legal, medical, financial), use cases where base model behavior is inadequate even with RAG, organizations with existing MLOps capability.
Strategic Recommendation
Most successful enterprises follow a “Escalation Framework”:
- Start with Prompt Engineering to validate the use case in days.
- Move to RAG if the model needs to “know” proprietary data that changes frequently.
- Use Fine-Tuning as a last resort, only when you need to change how the model behaves (e.g., specialized lingo or brand tone) or if high volume justifies training a smaller, cheaper model.
The three-year TCO reality: A worked example
To move from theory to a business case, let’s look at a Three-Year Total Cost of Ownership (TCO) for a typical enterprise use case: An Intelligent Customer Support & Internal Knowledge Agent handling ~500,000 queries per month.
This comparison looks at Buy (Managed API + RAG) vs. Partner/Build (Open-Source SLM + Fine-Tuning + RAG).
Scenario: The “Knowledge Agent” (500k queries/mo)
|
Phase |
Buy (e.g., GPT-4o + Pinecone) | Partner/Build (e.g., Llama-3-70B + VPC) |
| Year 1: Setup & Data | $150k (RAG Dev + Data Cleaning) |
$450k (Custom Pipeline + Fine-tuning + GPU Setup) |
|
Year 2: Scaling |
$300k (High Token Vol + Vector DB) | $180k (Fixed GPU Instance + Maintenance) |
| Year 3: Optimization | $350k (Increased Usage + Model Drift) |
$150k (Optimized Inference + Internal Ops) |
|
3-Year TCO |
~$800,000 |
~$780,000 |
*Note: The figures provided in this Total Cost of Ownership (TCO) analysis are composite estimates based on current market benchmarks, cloud provider pricing (AWS/Azure/GCP), and historical data from enterprise AI deployments. These figures are intended for strategic planning purposes and do not represent a guaranteed quote or a fixed financial obligation.
Year 1: The “Entry Price” Illusion
- Buy: You spend very little on infrastructure. Most of your budget goes to Data Readiness (60%), cleaning your internal documentation so the RAG system doesn’t hallucinate.
- Partner/Build: The cost is 3x higher upfront. You are paying for high-end AI talent to build a private “sovereign” stack, fine-tune a model on your specific brand voice, and set up local hosting.
- The surprise: Most enterprises choose “Buy” here because the $150k looks safer than $450k.
Year 2: The “Token Trap” vs. “Fixed Compute”
- Buy: As your users adopt the tool, your Variable Costs explode. At 500k queries, you are sending millions of tokens into the cloud daily. You are also paying “Retail Margins” to the model provider.
- Partner/Build: Your costs drop sharply. Once the model is trained and the infrastructure is live, your primary cost is the monthly lease of the GPUs (e.g., 2x A100 nodes). Whether you run 100k or 1M queries, your server cost remains relatively flat.
- The surprise: Year 2 is where the “Buy” model often starts to feel like a “Success Tax.”
Year 3: Optimization & Sovereignty
- Buy: You are locked into the vendor’s ecosystem. If they raise prices or deprecate the model version you rely on, you face an expensive migration.
- Partner/Build: You now own the intellectual property (IP). You can “distill” your model into an even smaller, faster version (SLM) that runs on cheaper hardware, further driving down TCO.
- The surprise: By Year 3, the “Build/Partner” approach is often 50% cheaper per query than the “Buy” approach.
The “Break-Even” Decision Rule
- Volume threshold: If you expect <100k queries/month, Buy. The overhead of managing your own stack isn’t worth it.
- Data sensitivity: If a data leak costs you more than $1M (legal/brand), Partner/Build immediately to keep data inside your VPC.
- Complexity: If the task is “Generic” (summarizing meetings), Buy. If the task is “Specialized” (underwriting insurance), Partner/Build to ensure accuracy.
The good news: Token prices continue to fall. Gartner forecasts LLM inference costs will drop over 90% by 2030 compared to 2025 levels, which means inference will increasingly account for a smaller share of TCO even as capabilities improve. However, enterprise buyers should not expect providers to pass through all savings, demand for agentic AI capabilities, which require significantly more tokens per task, will partially offset inference cost reductions.
What is included (and not included) in a vendor quote
What’s Included: The “Build” Fundamentals
These are the core engineering deliverables usually covered in the initial development fee.
- Development Sprints: Agile delivery of the application logic, backend infrastructure, and frontend UI.
- Model Selection & Benchmarking: Technical evaluation of various LLMs (e.g., GPT-4o vs. Claude 3.5 vs. Llama 3) to find the “sweet spot” for your specific accuracy and latency requirements.
- API Integration: Connecting the LLM to your internal systems (ERP, CRM, Slack) and setting up the “plumbing” (RAG pipelines, vector databases).
- User Acceptance Testing (UAT): A structured period where users test the AI in a sandbox to ensure it follows brand guidelines and doesn’t “hallucinate” on key business facts.
What’s NOT Included: The “Operational” Lifecycle
These are the external or ongoing costs that often catch enterprises by surprise. A transparent quote must flag these early.
- Training data acquisition: The labor or licensing fees required to get your data “AI-ready.” This includes cleaning messy PDFs, labeling datasets, or buying third-party data.
- Post-launch fine-tuning: AI models are not “set and forget.” As your business logic or market conditions change, the model may need periodic retraining (Fine-Tuning) to remain relevant.
- Compliance & regulatory audits: Specialized security testing (e.g., SOC2, HIPAA compliance, or AI Bias audits) required by legal/finance departments before full production.
- Ongoing inference & compute costs: The “monthly utility bill.” Every time a user asks the AI a question, there is a cost (tokens or GPU runtime). This is a variable OpEx paid to the cloud provider, not the development partner.
A vendor who quotes only the build cost without projecting the first 12 months of operational spend is not giving you a TCO, they are giving you a down payment figure. Ask specifically: “What will we pay in month 13?”
What is included (and not included) in a vendor quote
At Kyanon Digital, our practice is to scope full TCO before a project starts, not just the build cost. We model inference projections, data preparation effort, and compliance requirements upfront so your procurement team works with numbers that hold.
How Kyanon Digital scopes LLM projects
Enterprise LLM engagements fail most often at the handoff between build and operate. Here is how we structure our engagements to eliminate that gap.
Discovery phase: Cost estimation workshop
Before any development begins, we run a structured discovery engagement, available as a fixed-fee workshop to produce a defensible cost model. This covers data readiness assessment, use case prioritization, model selection rationale, and an initial TCO projection across 12, 24, and 36 months. This phase typically runs 2 to 3 weeks.
TCO modelling before the project starts
Our project scopes include a three-year cost model that breaks down build cost, infrastructure cost, inference projection, and maintenance overhead. The model is built with your actual usage projections, not generic assumptions. This becomes the document your CFO and procurement team can defend internally.
Transparent inference cost projection
Kyanon Digital provides monthly inference cost estimates based on your expected request volume, prompt complexity, and chosen model tier. These estimates are updated at each sprint review as actual usage patterns emerge from testing.
Flexible engagement models
Kyanon Digital team offers three engagement structures depending on your organization’s maturity and risk preference:
- Fixed price: Best for well-scoped projects with stable requirements. Provides budget certainty with defined deliverables.
- Time and materials (T&M): Best for exploratory or research-heavy phases where scope evolves. Provides flexibility with transparent hourly visibility.
- Dedicated team: Best for enterprises that want an embedded specialist team for 6 to 18 months. Combines the flexibility of T&M with the continuity of a long-term partnership.
We also support hybrid structures, fixed price for the build phase combined with a dedicated team for ongoing operations, which tend to perform best for enterprises in regulated industries with evolving compliance requirements.

Optimizing LLM development cost for long-term value
Estimating LLM development cost in 2026 requires a lifecycle view, from data and model development to infrastructure, integration, and ongoing optimization. The true cost of LLM depends on use case complexity, scale, and model strategy.
Enterprises that take a focused, modular approach can better control LLM cost and maximize ROI, while continuously optimizing LLM costs as adoption grows. For a clearer roadmap and cost-efficient implementation, contact Kyanon Digital to turn your LLM strategy into measurable results.
Disclaimer: This blog references data from McKinsey State of AI 2025, Gartner enterprise AI research (2025 to 2026), Fortune Business Insights Enterprise LLM Market Report, Menlo Ventures 2025 Mid-Year LLM Market Update, and practitioner cost analyses from enterprise LLM deployments in 2025 to 2026. All cost estimates are composite figures derived from industry data and should be validated against your specific use case with a qualified advisor.















")




 Create project brief with AI
Create project brief with AI