What is batch inference?
Batch inference is the execution of a machine learning model on a large volume of accumulated data simultaneously at scheduled intervals, rather than processing individual requests instantly. It optimizes computational resources for non-latency-sensitive tasks by processing data offline and writing the predictions to a database for later consumption by end-user applications.
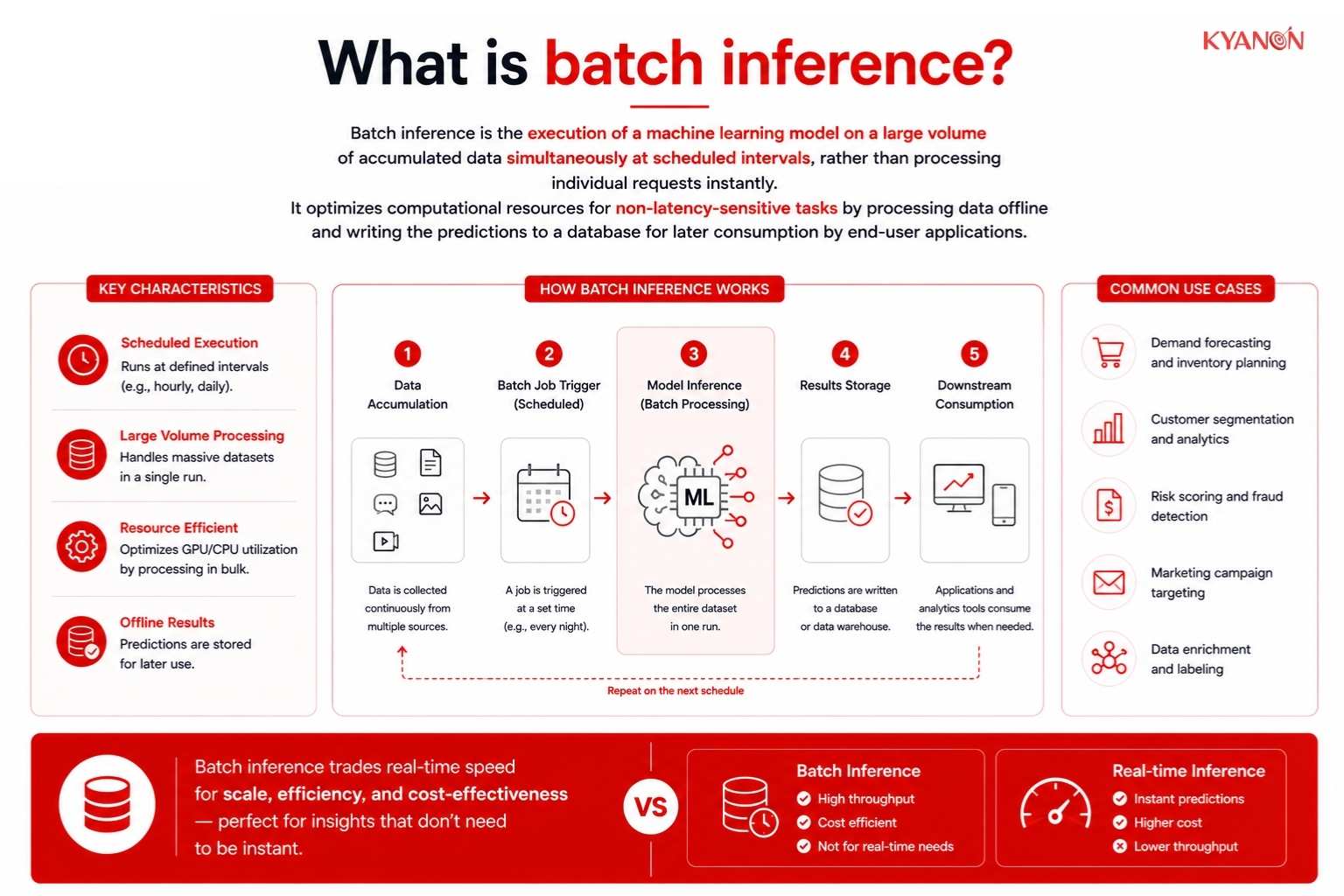
How batch inference works
The batch inference mechanism decouples the prediction generation process from the application’s user interface, allowing enterprise systems to execute massive machine learning workloads during off-peak operational hours.
Data Accumulation Layer
The accumulation layer collects and aggregates raw incoming data, such as user interaction logs or daily transaction records over a specified period. This staging phase ensures the model has a sufficiently large, structured dataset to process efficiently during the scheduled execution window.
High-Throughput Processing Engine
The processing engine loads the pre-trained machine learning model and applies it to the accumulated dataset in bulk. This component prioritizes throughput (the total volume of data processed per hour) over latency (the time it takes to process a single request), utilizing specialized compute clusters to handle the heavy workload.
Storage and Retrieval System
Once predictions are generated, the system writes the outputs to a centralized data warehouse or operational database. Downstream applications, such as marketing automation tools or reporting dashboards, then query these stored results instantly without waiting for live model execution.
Batch Inference vs Real-Time Inference
Both deployment methods generate model predictions, but they differ fundamentally in latency thresholds, infrastructure requirements, and resource allocation
|
Dimension |
Batch Inference | Real-Time Inference |
| Processing mechanism | Scheduled bulk execution |
Instant per-request execution |
|
Latency tolerance |
High (minutes to hours) | Low (milliseconds) |
| Cost efficiency | High (utilizes off-peak spot compute) |
Low (requires 24/7 active endpoints) |
|
Infrastructure demand |
Scalable data storage and ETL pipelines | High-availability API clusters |
| Primary use case | Daily recommendations, bulk document parsing |
Fraud detection, live AI chatbots |
When to consider batch inference
Consider batch inference if:
- Your organization needs to generate millions of personalized product recommendations overnight before dispatching morning email marketing campaigns.
- Your engineering team faces escalating cloud infrastructure costs and needs to utilize off-peak spot instances for heavy analytical workloads rather than maintaining constantly active servers.
- You are processing large volumes of asynchronous administrative data, such as auditing historical transaction logs or parsing folders of uploaded legal contracts.
It may not be the right priority if:
- Your core application relies on immediate, deterministic reactions to live user inputs, such as authorizing point-of-sale financial transactions or managing dynamic pricing at checkout.
Why batch inference matters for enterprise AI
Implementing a batch processing layer for machine learning directly addresses the primary financial bottleneck in scaling enterprise artificial intelligence: continuous and underutilized compute costs.
According to AWS, inference accounts for up to 90% of total machine learning infrastructure costs over an application’s lifecycle. A Southeast Asian e-commerce retailer migrated its daily product recommendation engine from a real-time API to a batch inference pipeline, reducing its monthly GPU compute expenses by 65%. This demonstrates how transitioning non-critical workloads to asynchronous processing directly converts architectural adjustments into measurable margin improvements.
Common misconceptions
Inference is the easy part compared to training the model in the first place
Reality: Over the lifecycle of a production AI system, inference consumes the vast majority of infrastructure resources and budget because it operates continuously. Training is episodic, but generating predictions at scale requires permanent, optimized infrastructure.
Batch and Real-time are competitors; we have to choose one architecture for our platform
Reality: The two methods are complementary. In enterprise architectures, real-time inference might flag a suspicious payment transaction instantly, while batch inference handles the subsequent heavy processing of daily audit logs and stakeholder notifications.
Batch inference is just ‘delayed’ real-time inference, which means a compromised experience
Reality: This view ignores the significant cost optimization benefits. Batch processing allows companies to use off-peak compute capacity or discounted “spot pricing,” drastically reducing operational expenses for tasks that inherently do not require sub-second latency.
How Kyanon Digital applies batch inference
Kyanon Digital implements batch inference pipelines for enterprise clients across Vietnam, Singapore, and ANZ who require daily or weekly machine learning predictions at scale. Our engineering approach focuses on matching the correct compute provisioning to specific business workflows, ensuring that high-volume data tasks run efficiently on optimized cloud infrastructure to strictly control the total cost of ownership (TCO) without sacrificing analytical accuracy.
Explore our ML and Big Data services:







")




 Create project brief with AI
Create project brief with AI