What is the bias-variance tradeoff?
The bias-variance tradeoff is a fundamental machine learning concept, where data scientists must balance underfitting (high bias) and overfitting (high variance) to ensure accurate, generalizable model performance. While increasing model complexity reduces bias, it simultaneously increases variance, requiring a search for an optimal, balanced, and flexible model. (IBM)
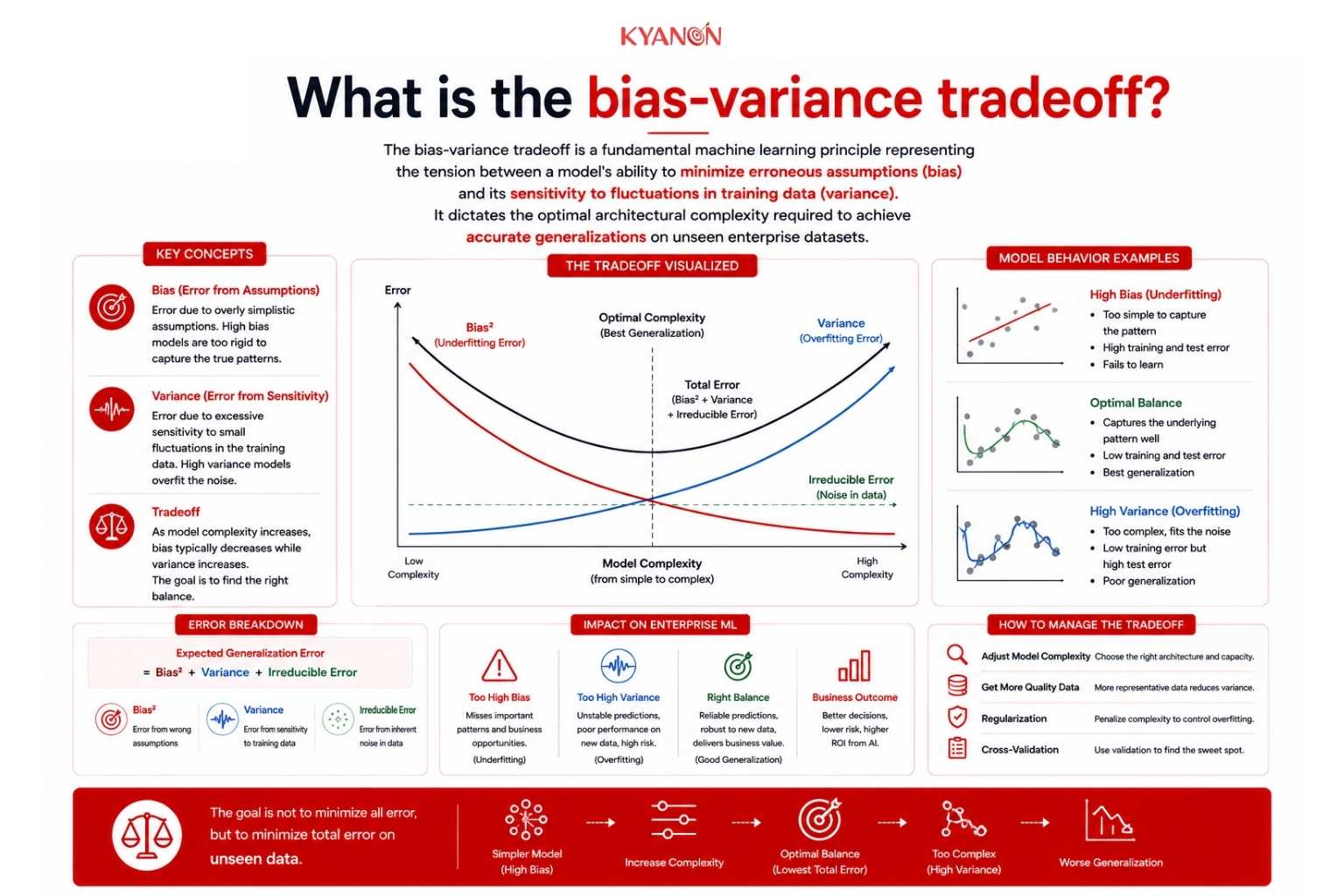
How the bias-variance tradeoff works
According to IBM, the bias-variance tradeoff works as a balancing act governed by model complexity. As you change a model’s flexibility to fit data, bias and variance move in opposite directions, directly impacting prediction errors.
- Bias (The Assumptions): This measures how far off a model’s average predictions are from the true values. High bias means the model makes overly rigid assumptions (e.g., fitting a straight line to curved data), causing it to underfit.
- Variance (The Sensitivity): This measures how much the model’s predictions change when trained on a different dataset. High variance means the model is hypersensitive to small fluctuations, memorizing random noise instead of learning the true signal, causing it to overfit.
- Irreducible Error (The Noise): This is the inherent noise in the data itself (e.g., measurement errors). No algorithm can eliminate this error, regardless of how well it is trained.
Bias-Variance Tradeoff vs Double Descent
Both concepts describe how algorithmic complexity impacts generalization error, but they apply to fundamentally different scales of machine learning architecture.
|
Dimension |
Classical Bias-Variance Tradeoff | Double Descent Phenomenon |
| Primary application | Traditional statistical models (e.g., Random Forests) |
Over-parameterized neural networks (e.g., LLMs) |
|
Error curve shape |
U-shaped | Peak followed by secondary decline |
| Complexity vs Variance | High complexity strictly increases variance |
Extreme complexity eventually reduces variance |
|
Interpolation threshold |
Avoids reaching zero training error |
Passes through zero training error |
|
Data requirement |
Performs well on moderate datasets |
Requires massive scale to enter the second descent |
When to consider the bias-variance tradeoff
Consider the bias-variance tradeoff if:
- Your engineering team reports high validation accuracy during testing, but significant performance degradation occurs immediately after deployment to production environments.
- You are transitioning from simplistic rule-based automation to predictive machine learning and must establish strict validation protocols for hyperparameter tuning.
- Your current predictive models generate highly erratic outputs when processing slightly varied batches of standard operational data.
It may not be the right priority if:
- Your architecture relies exclusively on pre-packaged, closed-source SaaS analytics where internal algorithm weights and complexity limits cannot be audited or modified.
Why the bias-variance tradeoff matters for enterprise AI
For enterprise AI, the bias-variance tradeoff represents the thin line between a high-performing digital asset and a multi-million-dollar financial liability. When deploying machine learning at scale, mismanaging this tradeoff creates severe operational, financial, and regulatory risks.
A recent report by MIT Sloan Management Review / Fortune reveals a sobering reality: 95% of generative AI pilots at companies are failing to yield any measurable business value. A significant factor behind these algorithmic stalls is the inability to transition models successfully from isolated test environments to volatile, real-world enterprise data, the exact challenge governed by the bias-variance tradeoff.
Common Misconceptions
Lower bias is always better, and we should aim for zero training error
Reality: Aiming for zero bias frequently forces the model into extreme variance, heavily overfitting the system. A perfect training score is typically a negative indicator, signaling that the architecture has simply memorized statistical noise rather than extracting generalizable business logic.
The tradeoff is always a strict U-shaped curve where more complexity eventually ruins the model
Reality: While textbook theory dictates a strict U-shaped error curve, modern deep learning networks exhibit a ‘double descent’ behavior. In highly over-parameterized models like large language models, error initially spikes but drops to new lows as the parameter count scales far beyond the interpolation threshold.
Feeding the model more data will automatically fix any variance problems
Reality: Expanding the dataset helps mitigate variance in overly sensitive models, but a fundamentally biased or mathematically constrained architecture will remain inaccurate regardless of data volume.
How Kyanon Digital applies the bias-variance tradeoff
Kyanon Digital engineers actively navigate the bias-variance tradeoff when defining architectural complexity for custom data and AI systems. We execute systematic hyperparameter tuning and cross-validation pipelines for enterprise clients across Southeast Asia and the US. Our technical approach ensures deployed models avoid overfitting, scale efficiently across production environments, and maintain strict generalization accuracy without inflating cloud inference costs.
Explore our services:







")




 Create project brief with AI
Create project brief with AI