What is Underfitting?
Underfitting is a machine learning problem in which a model fails to learn the underlying patterns and relationships within a dataset, resulting in poor performance on both training and validation data. It occurs when the model is too simple or lacks sufficient capacity to capture the true structure of the data, causing it to produce inaccurate predictions even on the examples it was trained to analyze.
Underfitting is commonly associated with high bias, meaning the model relies on overly simplistic assumptions that prevent it from representing real-world patterns effectively. As a result, the model consistently generates high error rates and fails to extract meaningful insights from the available data.
How Underfitting Happens
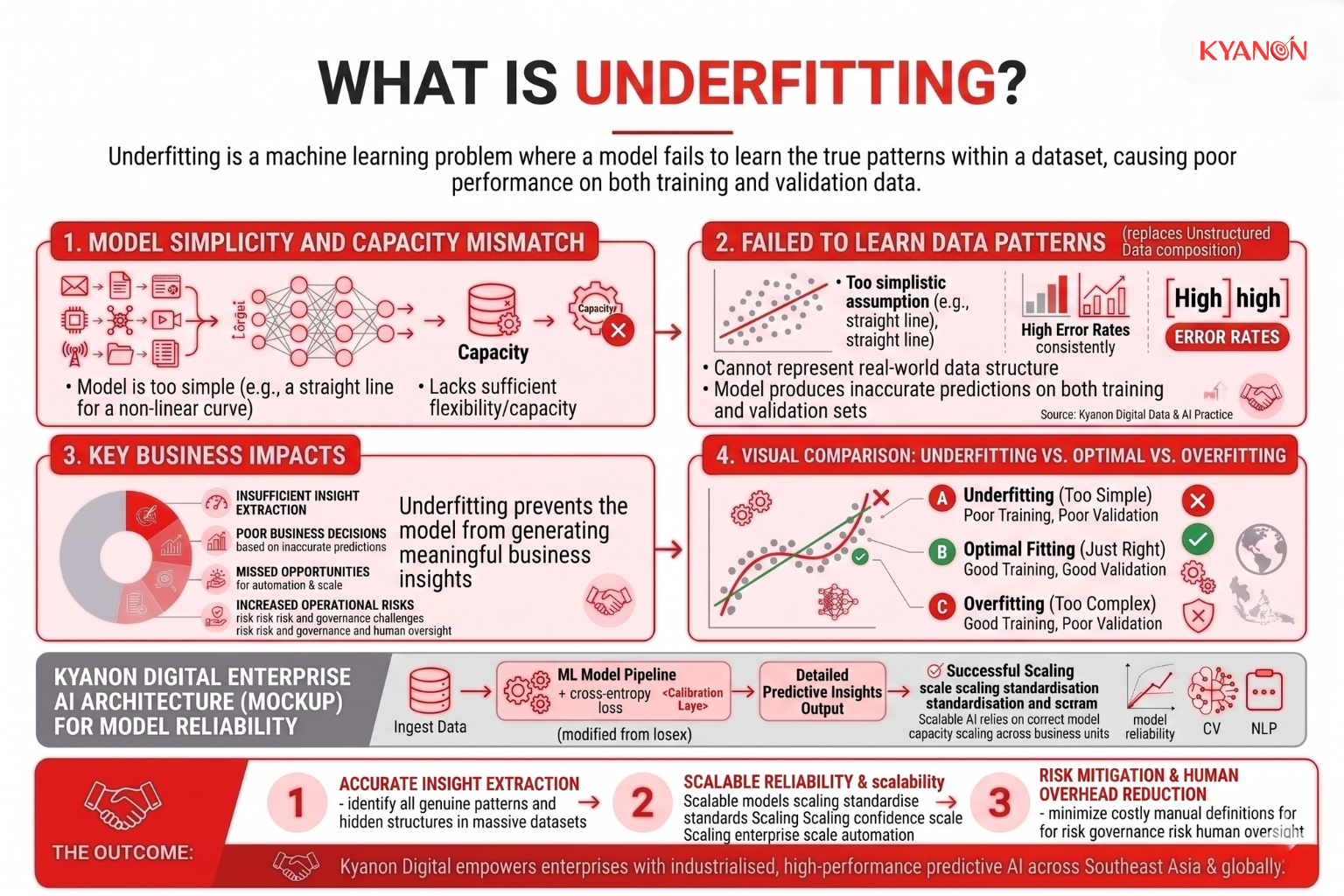
Underfitting occurs when there is a mismatch between the complexity of a real-world problem and the learning capacity of the machine learning model tasked with solving it. As a result, the model fails to capture the underlying patterns within the data and produces overly simplistic predictions. This leads to consistently high error rates on both training and validation datasets, indicating that the model has not learned enough from the available data.
Several factors can contribute to underfitting, including insufficient model complexity, inadequate feature representation, incomplete training, or optimization settings that prevent the model from learning effectively. Regardless of the cause, the outcome is the same: the model develops a high-bias representation of the problem and cannot accurately reflect the true relationships within the data.
Insufficient Model Capacity
Model capacity determines the complexity of patterns that an algorithm can learn. When the model architecture is too simple, it lacks the flexibility required to represent the true structure of the data.
For example, a linear regression model may struggle to capture highly nonlinear relationships because it is mathematically constrained to fit a straight line. Similarly, in deep learning, a neural network with too few layers or neurons may lack the representational power needed to learn complex feature hierarchies. In both cases, the model is forced to generate overly generalized predictions that fail to reflect the underlying data patterns.
Poor Feature Representation
Even a powerful machine learning model can underfit if it lacks access to informative features. The model can only learn from the signals provided in the dataset, making feature quality a critical factor in predictive performance.
Underfitting often occurs when important variables are missing or when raw data is not transformed into meaningful features. For instance, attempting to predict housing prices using only square footage while ignoring factors such as location, age of the property, or nearby amenities will limit the model’s ability to learn accurate relationships. Effective feature engineering helps expose the patterns that models need to capture.
Incomplete Optimization
A model may also underfit when the training process fails to reach an optimal solution. Even if the architecture and features are appropriate, poor optimization can prevent the model from fully learning the patterns present in the data.
Common causes include stopping training too early, using too few training iterations, configuring learning rates improperly, or applying overly aggressive regularization constraints that suppress the model’s ability to adjust its parameters. In these situations, the model never converges on a sufficiently accurate representation of the data and remains trapped in a high-error state.
By understanding these causes, organizations can diagnose underfitting more effectively and make targeted improvements to model architecture, feature engineering, and training strategies to achieve better predictive performance.
Underfitting vs Overfitting
Underfitting and overfitting represent opposite ends of the model generalization spectrum.
|
Dimension |
Underfitting | Overfitting |
| Training accuracy | Low |
Very high |
|
Validation accuracy |
Low | Lower than training |
| Model complexity | Too simple |
Too complex |
|
Bias level |
High | Low |
| Variance level | Low |
High |
|
Generalization ability |
Weak | Weak |
| Typical solution | Increase capacity or features |
Add regularization or simplify model |
A well-performing model balances learning capacity and generalization rather than minimizing training error alone.
Business Impact of Underfitting
Underfitting directly reduces the business value of machine learning investments because the model fails to capture meaningful patterns and predictive signals hidden within enterprise data. Even when organizations possess large volumes of historical information, an underfitted model cannot translate that data into actionable insights, leading to poor predictions, inaccurate recommendations, and suboptimal business decisions.
In production environments, underfitted models often perform only marginally better than simple rule-based systems. This limits the return on AI investments and can prevent organizations from realizing the operational efficiencies, revenue gains, and decision-making improvements that machine learning is intended to deliver.
Poor data readiness and inadequate model performance remain major barriers to AI success. Gartner found that only 28% of AI use cases fully succeed and meet ROI expectations, while 20% fail outright, with poor data quality and limited data readiness frequently cited as contributing factors. When models fail to learn meaningful patterns from available data, organizations struggle to generate measurable business value from their AI initiatives.
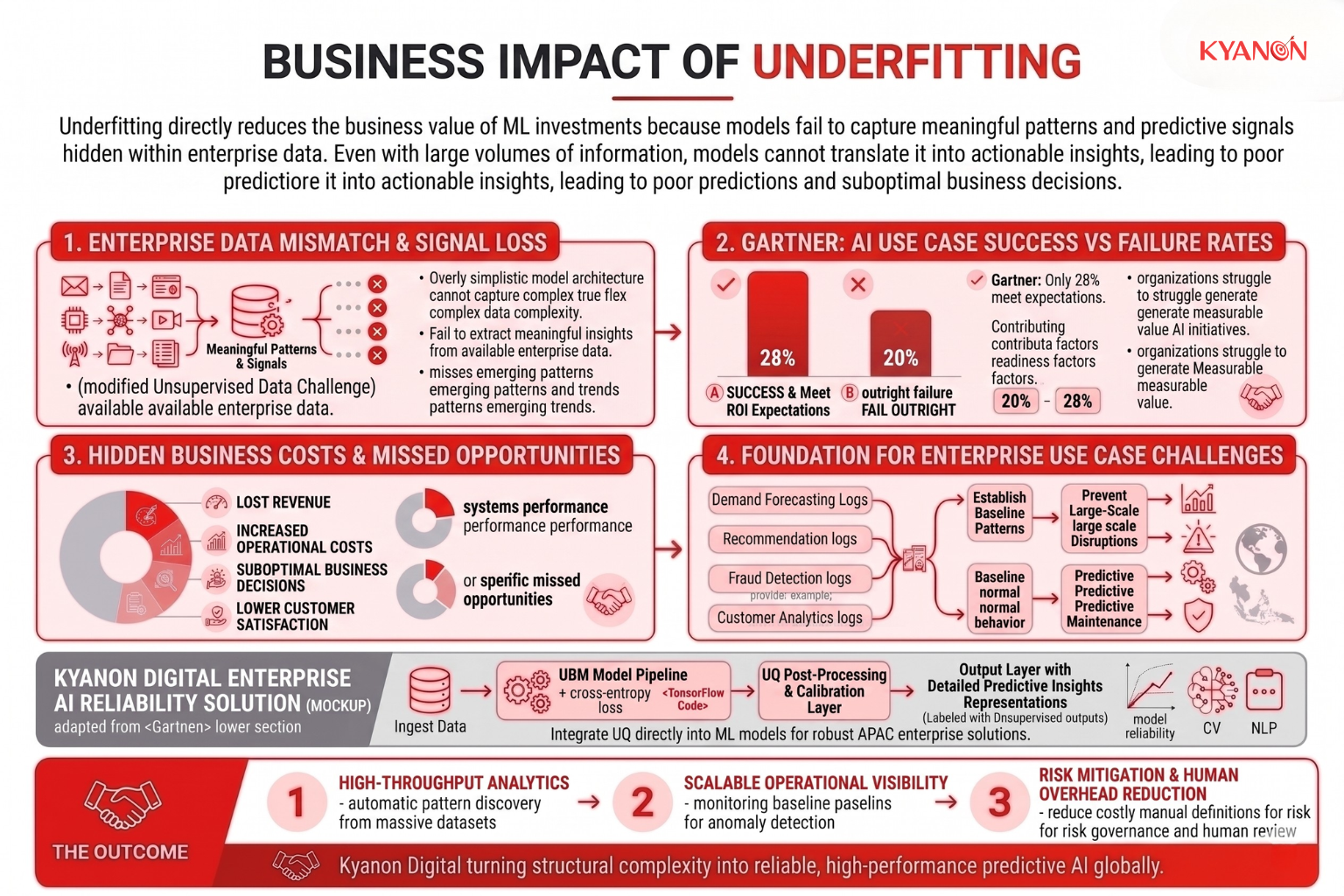
The consequences of underfitting can be particularly severe in forecasting, recommendation systems, fraud detection, and customer analytics. Because the model cannot recognize important relationships within the data, it often misses emerging trends, customer preferences, seasonal fluctuations, or abnormal behaviors. This results in decisions that are based on incomplete or oversimplified representations of reality.
For example, a retailer using an underfitted demand forecasting model may systematically overlook seasonal purchasing patterns, regional demand shifts, or promotional effects. Despite having years of historical sales data, the model may generate overly generalized forecasts that lead to inventory shortages during peak demand periods and excess stock during slower seasons. The result is lost revenue, increased operational costs, and reduced customer satisfaction.
Similarly, in recommendation systems, underfitting can prevent models from identifying nuanced customer preferences, resulting in generic product suggestions that fail to drive engagement or conversions. In fraud detection environments, underfitted models may overlook subtle indicators of suspicious behavior, reducing detection effectiveness and increasing financial risk.
Ultimately, underfitting represents a hidden business cost. Organizations may believe they have successfully deployed machine learning solutions, yet the models remain incapable of extracting the full value contained within their data. Addressing underfitting through improved model design, feature engineering, and optimization is therefore essential not only for technical performance but also for maximizing the return on enterprise AI investments.
Common Misconceptions About Underfitting
Underfitting only happens with small models
Large neural networks and Transformer models can underfit if optimization fails, training ends prematurely, gradients become unstable, or critical features are missing.
More data automatically fixes underfitting
Underfitting is primarily a model capacity and representation problem. Adding more examples does not solve a model’s inability to learn complex relationships.
High training error always proves underfitting
High training error can also result from noisy data, inconsistent labels, or irreducible uncertainty within the dataset. Diagnosis requires evaluating data quality alongside model performance.
Regularization only prevents overfitting
Excessive regularization can create underfitting, but certain regularization techniques such as normalization layers are often necessary to make deep models train effectively.
Underfitting should always be eliminated
In some production environments, organizations intentionally accept slight underfitting to reduce infrastructure costs, improve explainability, and maintain predictable system behavior.
For CTOs and IT leaders, the goal is not maximum model complexity; it is achieving the best business outcome within operational, governance, and cost constraints.
How Kyanon Digital Addresses Underfitting
Kyanon Digital addresses underfitting through a business-first machine learning methodology that focuses on data quality, feature representation, and domain context rather than relying solely on increasingly complex algorithms. In enterprise AI initiatives, underfitting is often caused by missing business signals, fragmented data sources, or insufficient feature engineering rather than limitations in the underlying model architecture.
A key differentiator is the ability to connect machine learning development with real business processes. Domain expertise, operational knowledge, and industry-specific context are incorporated into the modeling workflow to ensure that algorithms learn from the factors that genuinely influence business outcomes. This approach helps prevent models from relying on incomplete or overly simplified representations of complex business environments.
Through a combination of enterprise data engineering, domain-driven feature development, validation frameworks, and continuous optimization practices, Kyanon Digital helps organizations across Southeast Asia, ANZ, and global markets reduce underfitting risk, improve predictive accuracy, and maximize the business value generated from AI and machine learning investments.
→ Explore our Machine Learning Development services.







")




 Create project brief with AI
Create project brief with AI