Phân cụm là gì?
Phân cụm là một kỹ thuật học máy không giám sát, tự động phân tích các tập dữ liệu chưa được gắn nhãn và nhóm các điểm dữ liệu lại với nhau dựa trên sự tương đồng toán học vốn có, sự gần gũi về hành vi hoặc các mối quan hệ thống kê mà không cần dựa vào các danh mục được xác định trước hoặc các nhãn được chú thích thủ công.
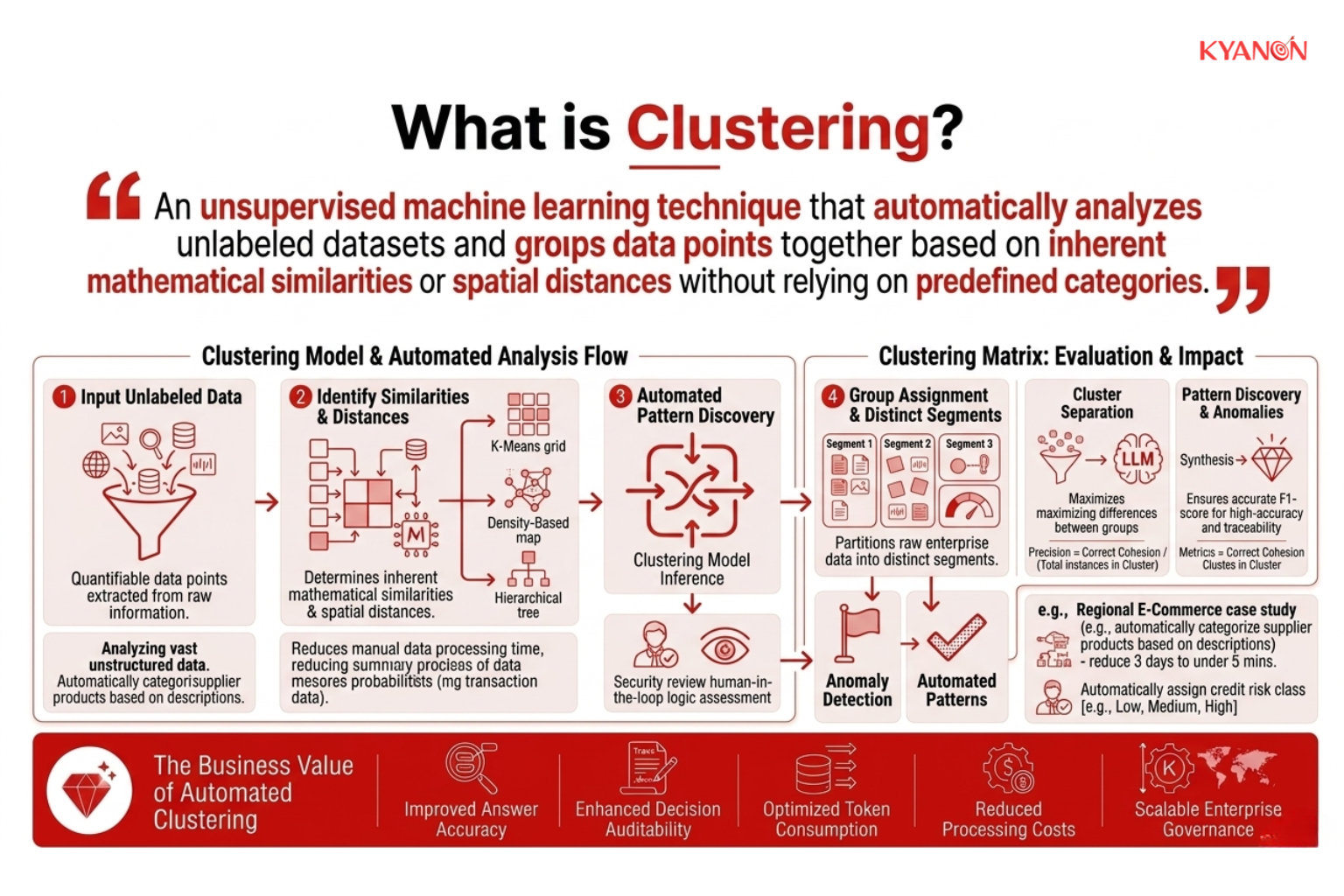
Thay vì dự đoán các kết quả đã biết, phân cụm khám phá các cấu trúc ẩn đã được nhúng sẵn bên trong dữ liệu doanh nghiệp. Bằng cách phân chia tập dữ liệu thành các nhóm mà các bản ghi trong cùng một cụm có độ tương đồng cao và các bản ghi trong các cụm khác nhau thể hiện sự khác biệt tối đa, phân cụm cho phép các tổ chức khám phá các mô hình hoạt động, phân khúc khách hàng, các bất thường và các mối quan hệ ẩn mà các hệ thống phân tích truyền thống thường không phát hiện được.
Đối với các tổ chức doanh nghiệp, phân cụm không chỉ đơn thuần là một bài toán toán học. Đó là một khung phát hiện mẫu có khả năng mở rộng, giúp chuyển đổi dữ liệu hoạt động thô thành thông tin kinh doanh hữu ích.
Các doanh nghiệp hiện đại sử dụng công nghệ phân cụm để:
- Khám phá các phân khúc khách hàng nhỏ có giá trị cao.
- Phát hiện hành vi gian lận hoặc bất thường
- Tự động sắp xếp các danh mục sản phẩm khổng lồ.
- Cải thiện công cụ cá nhân hóa
- Tối ưu hóa chuỗi cung ứng và hậu cần
- Xác định những điểm thiếu hiệu quả tiềm ẩn trong hoạt động.
- Xây dựng hệ thống đề xuất thích ứng
- Giảm sự phụ thuộc vào việc dán nhãn dữ liệu thủ công tốn kém.
Khác với các mô hình học máy có giám sát, phân cụm không yêu cầu nhãn lịch sử hoặc câu trả lời mục tiêu được xác định trước. Điều này làm cho nó đặc biệt có giá trị trong môi trường mà dữ liệu doanh nghiệp tăng trưởng nhanh hơn khả năng phân loại của con người.
Khi các tổ chức tạo ra khối lượng dữ liệu hành vi, giao dịch và đo lường ngày càng lớn, việc phân cụm trở nên thiết yếu để trích xuất thông tin hữu ích từ các hệ sinh thái thông tin không có cấu trúc.
Cách thức hoạt động của phân cụm
Không giống như các hệ thống học có giám sát học các ranh giới quyết định rõ ràng từ các ví dụ được gắn nhãn, các thuật toán phân cụm đánh giá các mối quan hệ toán học giữa các điểm dữ liệu trên không gian đặc trưng đa chiều.
Trong môi trường sản xuất doanh nghiệp, các quy trình phân cụm thường hoạt động qua ba giai đoạn chính:
- Xử lý dữ liệu sơ bộ và chuẩn hóa đặc trưng
- Tính toán độ tương đồng và khoảng cách
- Tối ưu hóa lặp và phân bổ cụm
Mỗi giai đoạn đều ảnh hưởng trực tiếp đến độ tin cậy của mô hình, chất lượng phân đoạn và tính hữu ích của nó đối với hoạt động kinh doanh sau này.
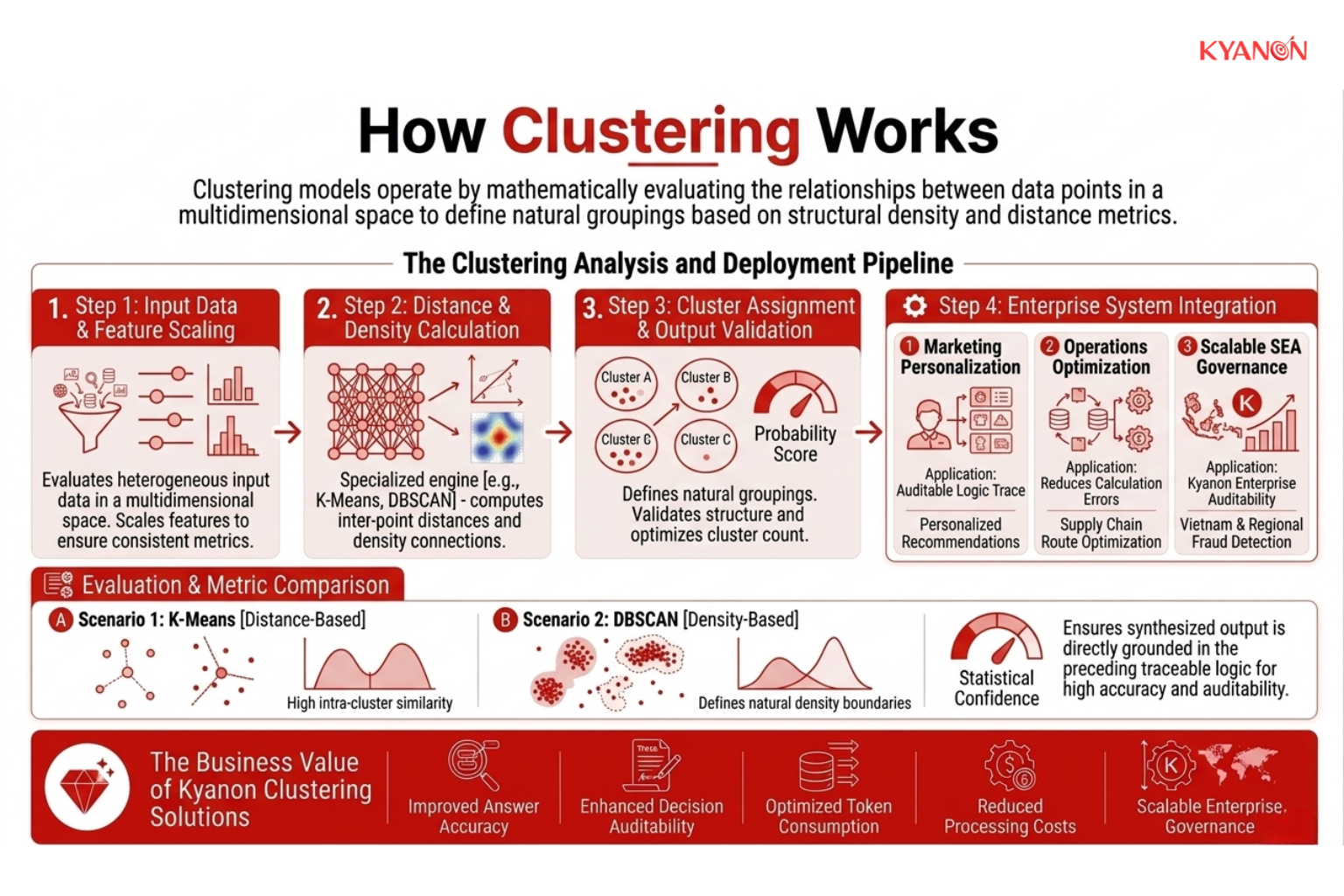
Xử lý sơ bộ dữ liệu và chuẩn hóa đặc trưng
Trước khi bắt đầu phân cụm, dữ liệu doanh nghiệp cần được làm sạch, sắp xếp và chuẩn hóa thành định dạng số nhất quán. Trong môi trường kinh doanh thực tế, các tập dữ liệu thường chứa các giá trị bị thiếu, các bản ghi trùng lặp, định dạng không nhất quán và các biến được đo lường trên các thang đo rất khác nhau. Nếu không được chuẩn bị đúng cách, những sự không nhất quán này có thể làm sai lệch đáng kể kết quả phân cụm.
Việc chuẩn hóa đặc trưng đặc biệt quan trọng vì các thuật toán phân cụm dựa nhiều vào các phép tính khoảng cách để xác định sự tương đồng giữa các điểm dữ liệu. Các biến có phạm vi giá trị lớn hơn, chẳng hạn như doanh thu hàng năm hoặc khối lượng giao dịch, có thể vô tình chi phối các biến có quy mô nhỏ hơn như tần suất tương tác hoặc xếp hạng của khách hàng. Chuẩn hóa đảm bảo rằng mỗi biến đóng góp một cách tương xứng hơn vào phân tích, cho phép mô hình phân cụm xác định các mối quan hệ hành vi có ý nghĩa thay vì bị thiên vị đối với một tập hợp nhỏ các chỉ số có giá trị cao.
Xử lý sơ bộ hiệu quả giúp cải thiện độ chính xác phân đoạn, tính ổn định của mô hình và độ tin cậy tổng thể của kết quả phân cụm trong kinh doanh.
Đo lường sự tương đồng
Sau khi dữ liệu được chuẩn hóa, hệ thống phân cụm sẽ đánh giá mức độ liên quan chặt chẽ giữa các bản ghi khác nhau dựa trên nhiều biến số. Quá trình này được gọi là đo lường độ tương đồng.
Thuật toán này sử dụng các phép tính khoảng cách toán học, chẳng hạn như khoảng cách Euclidean hoặc khoảng cách Manhattan, để xác định mức độ tương đồng hoặc khác biệt giữa các điểm dữ liệu. Trong các ứng dụng doanh nghiệp, các mối quan hệ này có thể thể hiện sự tương đồng trong hành vi khách hàng, hoạt động mua hàng, hiệu suất hoạt động, mô hình giao dịch hoặc mức độ tương tác kỹ thuật số.
Mục tiêu là xác định các bản ghi có hành vi tương tự nhau dựa trên các đặc điểm chung. Các điểm dữ liệu có sự tương đồng cao được đặt gần nhau hơn trong cấu trúc phân cụm, trong khi các bản ghi có hành vi khác biệt đáng kể được đặt cách xa nhau hơn.
Phân tích độ tương đồng này tạo nền tảng cho việc xác định các mô hình ẩn, các phân khúc hành vi và các mối quan hệ vận hành mà có thể không hiển thị thông qua các hệ thống báo cáo truyền thống hoặc phân tích thủ công.
Phân bổ cụm lặp lại
Sau khi thiết lập các mối quan hệ tương đồng, thuật toán phân cụm bắt đầu nhóm các bản ghi thành các cụm. Hệ thống liên tục gán các điểm dữ liệu vào tâm cụm, vùng dày đặc hoặc nhóm hành vi dựa trên mức độ liên quan chặt chẽ của chúng với các bản ghi xung quanh.
Đây là một quy trình tối ưu hóa lặp đi lặp lại. Khi các điểm dữ liệu mới được gán, thuật toán liên tục tính toán lại ranh giới cụm và điều chỉnh vị trí nhóm để cải thiện độ chính xác tổng thể. Mục tiêu là giảm thiểu sự biến đổi trong mỗi cụm đồng thời tối đa hóa sự phân tách giữa các cụm khác nhau.
Qua nhiều lần lặp, mô hình dần dần tinh chỉnh cấu trúc nhóm cho đến khi các cụm trở nên ổn định và nhất quán hơn. Kết quả cuối cùng lý tưởng là tạo ra các phân đoạn trong đó các bản ghi bên trong cùng một cụm có sự tương đồng mạnh mẽ về hành vi hoặc hoạt động, trong khi các bản ghi trong các cụm riêng biệt thể hiện những khác biệt có ý nghĩa.
Trong môi trường doanh nghiệp, các nhóm này sau đó có thể được chuyển đổi thành những thông tin kinh doanh hữu ích như phân khúc khách hàng, chỉ số gian lận, hồ sơ rủi ro vận hành, danh mục đề xuất hoặc cơ hội tối ưu hóa quy trình.
Phân cụm so với phân loại
Cả hai đều là những kỹ thuật học máy cơ bản được sử dụng để phân loại dữ liệu, nhưng chúng khác nhau về bản chất ở chỗ phụ thuộc vào các nhãn lịch sử và kết quả được xác định trước.
|
Kích thước |
Phân cụm | Phân loại |
| Phương pháp học tập | Không giám sát (không có nhãn) |
Có giám sát (yêu cầu dữ liệu được gắn nhãn) |
|
Mục tiêu chính |
Khám phá những cấu trúc ẩn và các nhóm mới | Phân loại dữ liệu vào các danh mục đã được xác định trước. |
| Yêu cầu dữ liệu | Dữ liệu thô chưa được gắn nhãn |
Khối lượng lớn dữ liệu được chú thích thủ công |
|
Loại đầu ra |
Mã định danh nhóm hoặc tâm nhóm | Nhãn danh mục rời rạc hoặc xác suất |
| Trường hợp sử dụng trong doanh nghiệp | Phân khúc khách hàng, phát hiện bất thường |
Lọc thư rác, định tuyến vé |
Khi nào nên xem xét việc phân cụm?
Hãy cân nhắc sử dụng phân cụm nếu:
- Bộ phận marketing của bạn cần phân chia cơ sở dữ liệu khách hàng khổng lồ, chưa được phân loại thành các phân khúc hành vi riêng biệt để cá nhân hóa chi tiêu marketing mà không cần phải tự xác định các quy tắc phân khúc.
- Nhóm bảo mật hoặc vận hành CNTT của bạn cần thiết lập một tiêu chuẩn cơ bản về hành vi mạng bình thường để tự động cô lập các sự cố bất thường, dữ liệu ngoại lai và các mối đe dọa zero-day khó lường.
- Nền tảng thương mại điện tử của bạn cần một công cụ đề xuất tự động có khả năng nhóm các sản phẩm có chức năng tương tự nhau dựa trên nhiều thuộc tính khác nhau, thay vì gắn thẻ thủ công và cứng nhắc.
Có thể đó không phải là ưu tiên đúng đắn nếu:
- Nhóm kỹ thuật của bạn cần dự đoán liệu một người dùng cụ thể có rời bỏ dịch vụ vào tháng tới hay không dựa trên dữ liệu lịch sử về tỷ lệ người dùng rời bỏ, điều này đòi hỏi phải sử dụng mô hình phân loại hoặc hồi quy có giám sát.
Tại sao phân cụm lại quan trọng đối với dữ liệu doanh nghiệp?
Các doanh nghiệp hiện đại hoạt động trong môi trường dữ liệu ngày càng phức tạp. Mỗi tương tác với khách hàng, giao dịch tài chính, phiên sử dụng ứng dụng di động, phiếu hỗ trợ, yêu cầu mạng và sự kiện chuỗi cung ứng đều tạo ra dữ liệu hoạt động bổ sung. Mặc dù các tổ chức đã trở nên cực kỳ hiệu quả trong việc thu thập thông tin, nhưng nhiều tổ chức vẫn gặp khó khăn trong việc chuyển đổi thông tin đó thành những hiểu biết chiến lược có ý nghĩa.
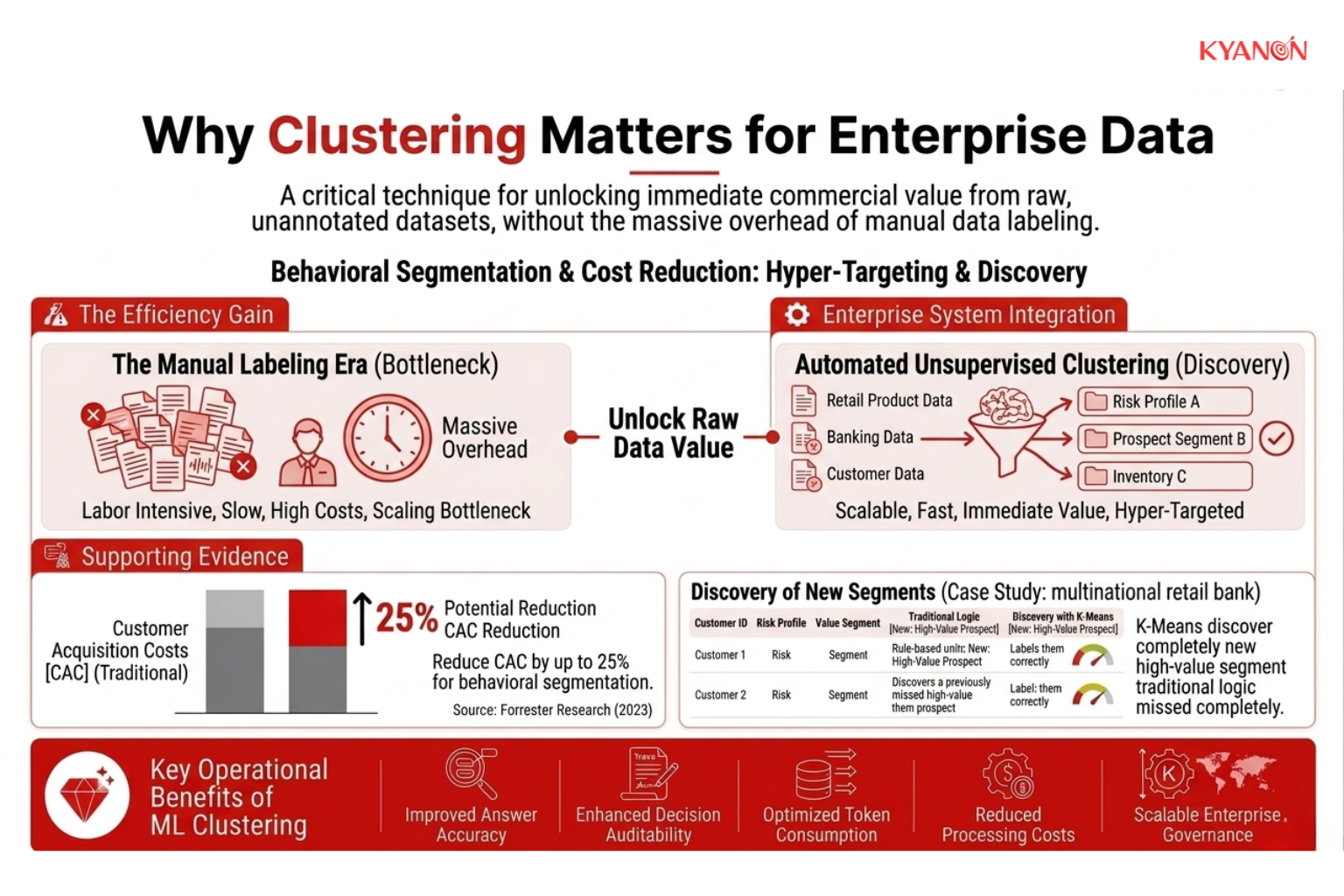
Các hệ thống phân tích truyền thống phụ thuộc rất nhiều vào cấu trúc báo cáo được xác định trước, bảng điều khiển được thiết kế thủ công và các danh mục kinh doanh cứng nhắc. Những phương pháp này hoạt động tốt khi các tổ chức đã biết mình đang tìm kiếm điều gì. Tuy nhiên, chúng trở nên kém hiệu quả hơn đáng kể khi các mô hình hành vi liên tục thay đổi hoặc khi những thông tin chi tiết có giá trị nhất vẫn chưa được biết đến.
Điều này tạo ra một số thách thức lớn về mặt vận hành đối với các nhóm doanh nghiệp.
Các bộ phận marketing thường gặp khó khăn trong việc vượt ra khỏi phân khúc nhân khẩu học rộng lớn vì hành vi khách hàng thay đổi nhanh hơn so với khả năng thích ứng của các hệ thống báo cáo truyền thống. Các nhóm bảo mật phải giám sát hàng triệu sự kiện hành vi trên môi trường cơ sở hạ tầng đám mây mà không có khả năng điều tra thủ công từng sự bất thường. Các tổ chức bán lẻ và thương mại điện tử quản lý danh mục sản phẩm đang mở rộng nhanh chóng, nơi việc phân loại thủ công trở nên không bền vững về mặt vận hành. Các tổ chức tài chính phải đối mặt với các mô hình gian lận ngày càng tinh vi, vượt qua các hệ thống phát hiện dựa trên quy tắc tĩnh.
Phân cụm giải quyết những thách thức này theo cách khác biệt so với các nền tảng phân tích kinh doanh truyền thống. Thay vì yêu cầu hệ thống xác nhận các giả định đã biết, phân cụm tự động xác định các cấu trúc ẩn bằng cách đánh giá cách dữ liệu tự sắp xếp một cách tự nhiên.
Điều này cho phép các tổ chức khám phá ra:
- Các phân khúc khách hàng dựa trên hành vi mà trước đây không thể nhìn thấy.
- Các mô hình hoạt động bất thường trước khi chúng leo thang thành sự cố.
- Các mối quan hệ sản phẩm mới nổi bên trong các danh mục sản phẩm lớn
- Những điểm thiếu hiệu quả tiềm ẩn trong quy trình vận hành.
- các cơ hội thị trường chưa được xác định trước đây
Khi các tổ chức tiếp tục chuyển từ phân tích dựa trên quy tắc sang các hoạt động thích ứng dựa trên trí tuệ nhân tạo, việc phân cụm ngày càng trở nên quan trọng đối với cá nhân hóa, phát hiện bất thường, hệ thống đề xuất, giám sát an ninh mạng và các sáng kiến tự động hóa thông minh.
Những quan niệm sai lầm thường gặp
“Phân cụm chỉ là một hình thức phân loại khi bạn chưa biết các danh mục.”
Thực tế: Phân cụm khám phá ra các mối quan hệ toán học hoàn toàn mới dựa trên sự tương đồng thô, trong khi phân loại huấn luyện một thuật toán để sao chép một ranh giới quyết định cụ thể do con người định nghĩa. Phân cụm có thể nhóm người dùng dựa trên các chỉ số không có nhãn dễ hiểu đối với con người nhưng lại có ý nghĩa thống kê rất cao.
“Thuật toán sẽ luôn đưa ra các nhóm thực sự, tự nhiên trong dữ liệu.”
Thực tế: Nhiều thuật toán phân cụm sẽ ép dữ liệu vào các nhóm riêng biệt về mặt toán học, ngay cả khi dữ liệu cơ bản hoàn toàn ngẫu nhiên và thiếu cấu trúc vốn có, một hiện tượng được gọi là ảo ảnh phân cụm. Kết quả đầu ra cần được các chuyên gia trong lĩnh vực xác nhận để kiểm chứng xem các cụm toán học đó có thực sự đại diện cho các phân khúc kinh doanh có ý nghĩa và khả thi hay không.
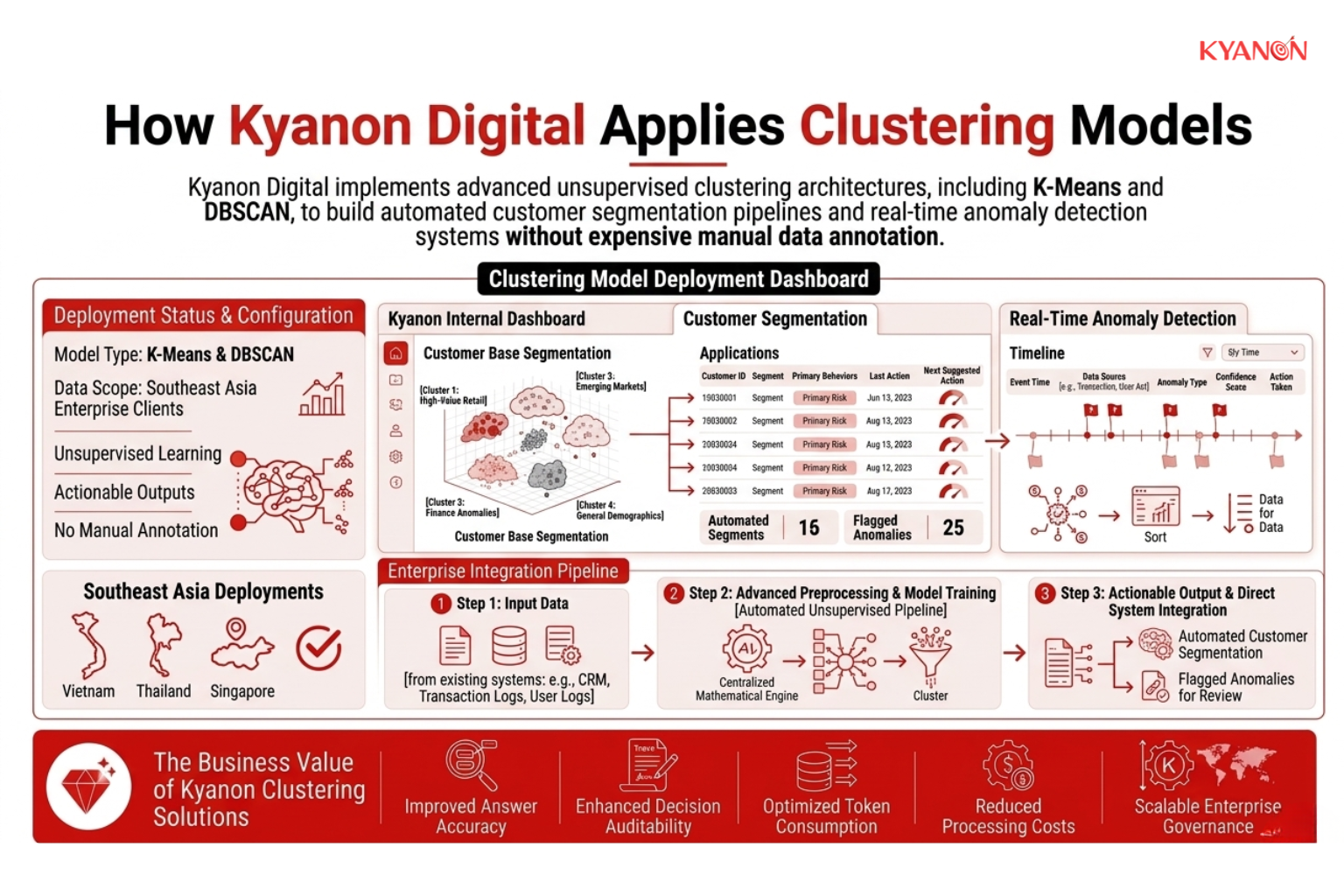
Cách Kyanon Digital áp dụng phân cụm
Kyanon Digital giúp các tổ chức chuyển đổi dữ liệu doanh nghiệp phân tán thành trí tuệ vận hành có khả năng mở rộng thông qua các sáng kiến hiện đại hóa dựa trên trí tuệ nhân tạo (AI). Đội ngũ của chúng tôi hỗ trợ toàn bộ vòng đời chuyển đổi, từ đánh giá kiến trúc dữ liệu và hiện đại hóa phân tích đến tích hợp AI, chiến lược tự động hóa và thiết kế quy trình làm việc thông minh.
Trong các lĩnh vực bán lẻ, thương mại điện tử, dịch vụ tài chính và hoạt động doanh nghiệp, chúng tôi triển khai các mô hình phân cụm giúp chuyển đổi lượng lớn dữ liệu giao dịch, hành vi và hoạt động thành thông tin kinh doanh hữu ích.
Đối với một khách hàng trong lĩnh vực bán lẻ và thương mại điện tử, các kỹ thuật phân cụm đã được áp dụng cho dữ liệu giao dịch và tương tác của khách hàng để xác định các phân khúc hành vi riêng biệt. Những hiểu biết này cho phép thực hiện các chiến dịch tiếp thị nhắm mục tiêu hiệu quả hơn, cải thiện chiến lược cá nhân hóa và phân bổ ngân sách khuyến mãi hiệu quả hơn.
Đối với một tổ chức dịch vụ tài chính, các phương pháp phân cụm dựa trên mật độ đã giúp xác định các mô hình giao dịch bất thường, khác biệt so với hành vi thông thường của khách hàng. Bằng cách hỗ trợ quy trình phát hiện gian lận với việc khám phá các bất thường không cần giám sát, tổ chức đã cải thiện hiệu quả giám sát đồng thời giảm sự phụ thuộc vào các quy tắc được định nghĩa thủ công.
Các nhóm khoa học dữ liệu và kỹ thuật của chúng tôi tích hợp trực tiếp kết quả phân cụm vào hệ thống CRM, phân tích và vận hành doanh nghiệp, đảm bảo rằng những hiểu biết về phân khúc có thể được kích hoạt trong toàn bộ quy trình tương tác khách hàng, quản lý rủi ro và ra quyết định kinh doanh. Điều này cho phép các tổ chức vượt ra khỏi báo cáo tĩnh và xây dựng các hoạt động dựa trên dữ liệu, liên tục thích ứng với hành vi thay đổi của khách hàng và thị trường.
→ Khám phá các dịch vụ Phát triển Trí tuệ Nhân tạo và Học máy của chúng tôi .







")




 Create project brief with AI
Create project brief with AI