What is Data Labeling?
Data labeling is the structural process of identifying and adding informative metadata, categories, or bounding boxes to raw unstructured datasets to generate high-fidelity training inputs for machine learning models. This standardized annotation process establishes the fundamental semantic context required for algorithms to correctly classify patterns, make decisions, and execute predictive tasks. By transforming raw files, such as multi-spectral images, continuous video feeds, clinical text, and voice recordings, into labeled formats, organizations can systematically train, validate, and tune neural networks.
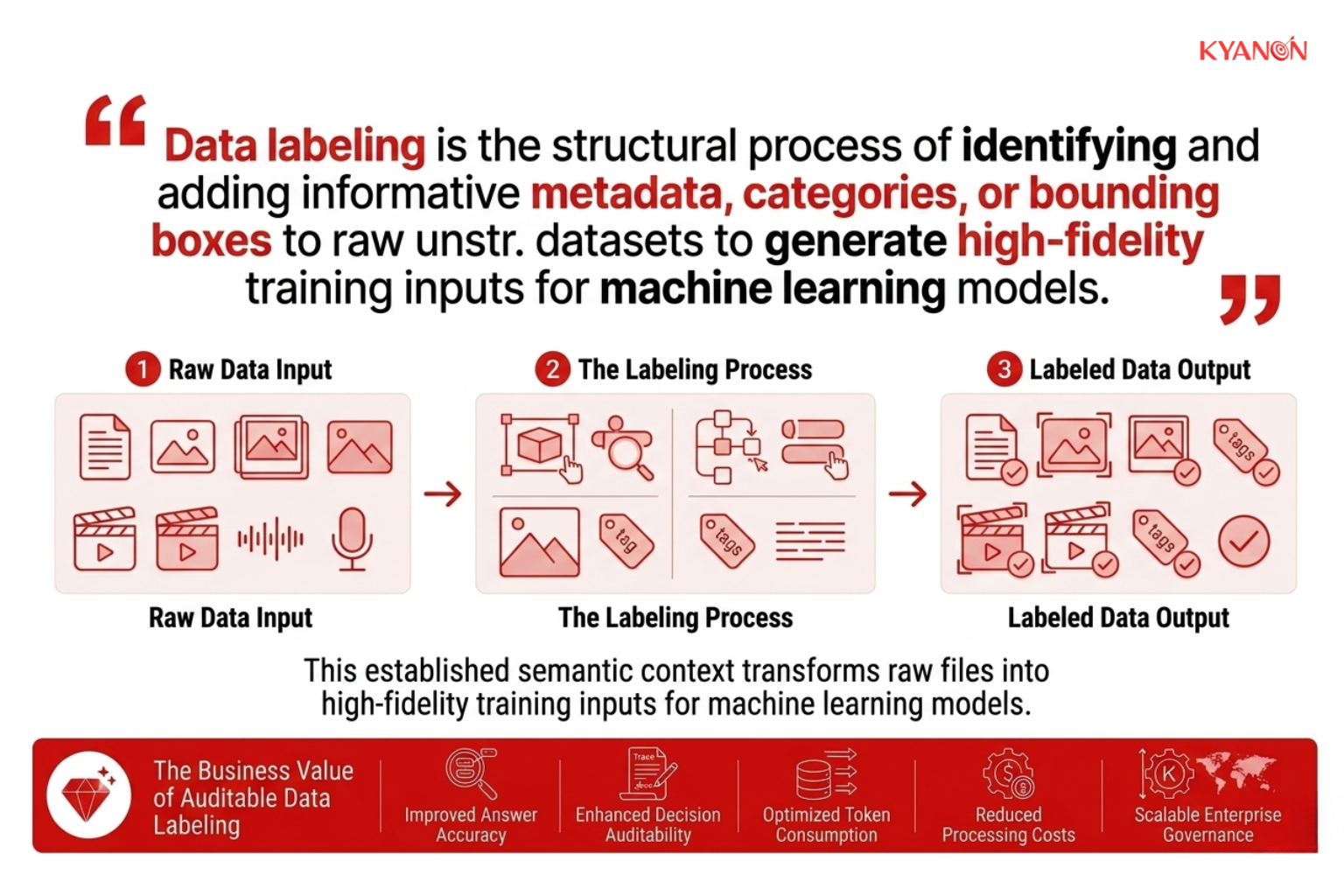
Core Data Labeling Types
- Computer Vision: Drawing bounding boxes, polygons, and keypoints or performing pixel-level semantic segmentation on images and video.
- Natural Language Processing (NLP): Identifying text entities, tagging parts of speech, and executing sentiment analysis on textual data.
- Audio Processing: Transcribing spoken words, identifying distinct speakers, and tagging background acoustic environments.
Operational Frameworks
- Human-in-the-Loop (HITL): Utilizing human annotators to label complex datasets or manually audit and correct machine-generated predictions.
- Model-Assisted Labeling: Deploying pre-trained AI models to auto-label data, drastically reducing manual annotation time.
- Active Learning: Programmatically selecting only the most ambiguous data points for human review to optimize labeling budgets.
Key Operational Challenges
- Label Drift: Shifts in data patterns over time that cause training labels to become obsolete or inaccurate.
- Annotator Bias: Inconsistencies introduced when different human annotators interpret subjective labeling guidelines differently.
- Scalability Bottlenecks: Managing the exponential cost and time required to manually clean and annotate petabyte-scale datasets.
The Role of Ground Truth
Data labeling provides the “ground truth” necessary for supervised machine learning models to detect patterns, classify objects, and perform semantic analysis. Without accurate and verified labels, mathematical algorithms cannot distinguish between noise and actual signals, leading to model degradation and operational failure in production environments.
How Data Labeling Works
The mechanism of data labeling operates by translating raw unstructured inputs into structured representations that a machine learning model can interpret through statistical optimization. When raw data is ingested, it lacks the explicit boundaries and semantic markers required for supervised training algorithms. To resolve this, a systematic data preparation pipeline must classify, segment, and tag the target features of the dataset.
During this pipeline, unstructured items are mapped into mathematical representations, such as high-dimensional vector embeddings, allowing downstream models to calculate geometric distances and probability distributions. The systematic execution of this process relies on active learning loops, programmatic heuristics, and quality verification workflows to ensure that the resulting labels are both representative of real-world scenarios and free from structural noise.
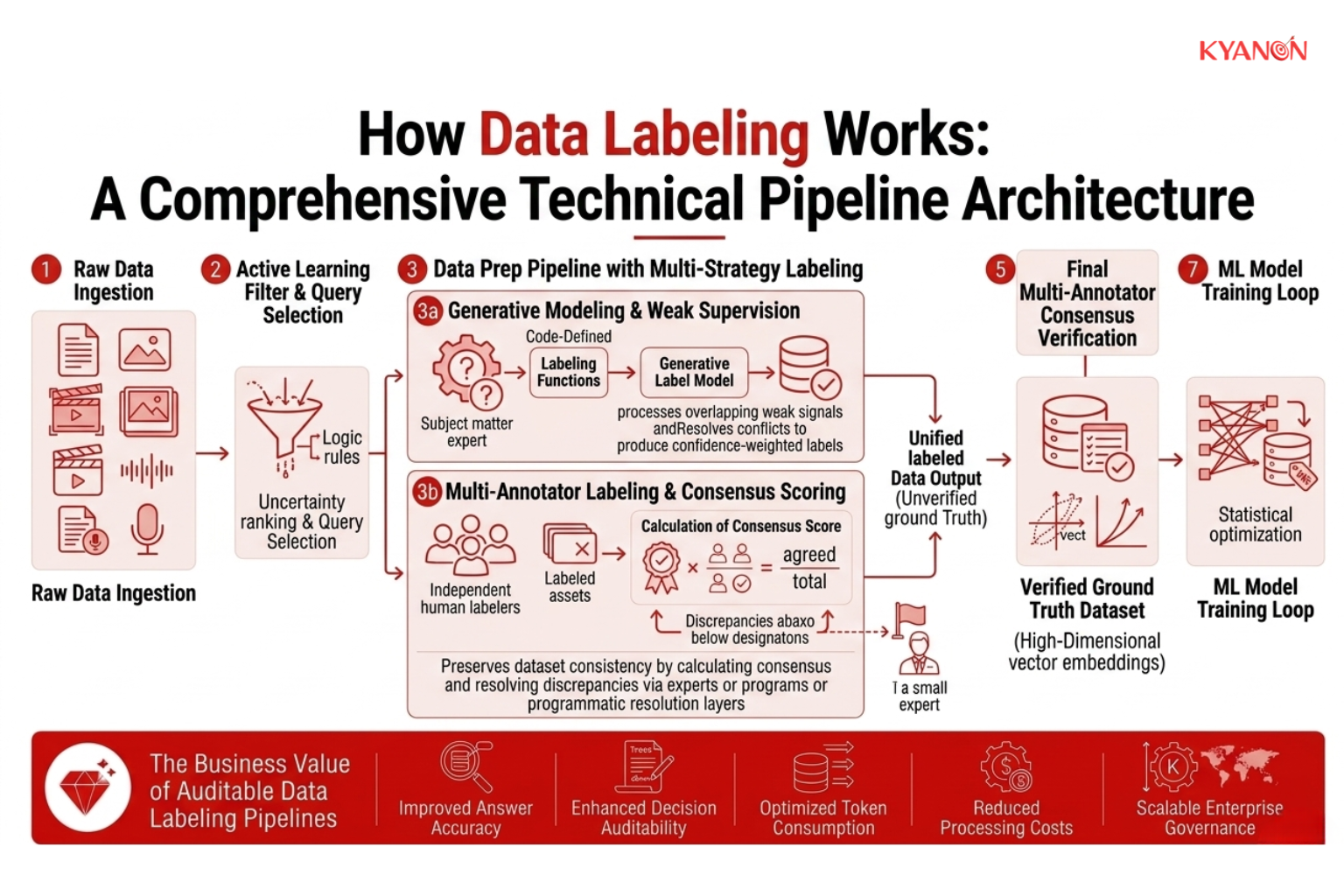
An active learning pipeline manages raw and ground-truth datasets by utilizing probability-based selective sampling to extract the most uncertain model predictions for manual verification, reducing manual labeling overhead.
Key Component 1: Active Learning and Query Selection
Rather than labeling repetitive or low-signal assets, modern workflows utilize active learning algorithms to isolate informative data points. Techniques such as pool-based sampling and stream-based selective sampling rank unlabeled data according to uncertainty or entropy. This ensures that annotators spend their time only on assets that lie near the model’s decision boundaries, preventing resource waste on redundant features.
Key Component 2: Multi-Annotator Labeling and Consensus Scoring
To eliminate individual cognitive bias, identical data assets are routed to multiple independent labelers. The platform measures label agreement by calculating a consensus score, derived by dividing the sum of agreeing labels by the total number of labels assigned per asset. Discrepancies that fall below the designated consensus threshold are automatically flagged and redirected to expert adjudicators or programmatic resolution layers to preserve dataset consistency.
Key Component 3: Generative Modeling and Weak Supervision
For large-scale enterprise deployments, manual labeling is supplemented by weak supervision frameworks. Subject matter experts write code-defined labeling functions that represent heuristic rules, pattern matches, or external database lookups. A generative label model then processes these overlapping and conflicting weak signals, automatically estimates their relative accuracies, and resolves conflicts to produce unified, confidence-weighted training labels.
Data Labeling vs Data Augmentation
Both techniques are vital for training set engineering, but they manipulate data at different stages of the machine learning pipeline.
While data labeling assigns descriptive semantic tags to existing unstructured inputs, data augmentation computationally synthesizes new training instances from those labeled assets to expand overall dataset diversity.
|
Dimension |
Data Labeling | Data Augmentation |
| Core Concept | Identifying and tagging existing unstructured data. |
Generating synthetic variations of existing labeled data. |
|
Input Source |
Raw, unannotated real-world files. | Previously labeled real-world assets. |
| Primary Mechanism | Manual annotation or rule-based programmatic functions. |
Geometric transformations, color shifts, or generative modeling. |
|
Computational Overhead |
Low (Primarily bound by human and tooling interfaces). | High (Demands dedicated GPU resources for generative rendering). |
| Primary Failure Mode | Inter-annotator inconsistency and subjective labeling bias. |
Overfitting to artificial distortions that do not occur in reality. |
|
Scale Efficiency |
Constrained by human workforces or heuristic rules. |
High scalability through algorithmic variations. |
When to Consider Data Labeling
Enterprises should transition to structured data labeling workflows when engineering audits reveal that data preparation tasks consume over 60% of machine learning deployment timelines or when model accuracy drops during production-scale inference.
Consider Data Labeling if:
- Your data engineering and data science teams are spending up to 80% of their operational cycles aggregating, cleaning, and manually formatting unstructured datasets rather than designing, training, and deploying model architectures.
- Your models exhibit high performance during hand-curated laboratory proofs-of-concept but suffer immediate accuracy collapse when exposed to real-world edge cases and noisy operational data in production.
- Your business functions within highly regulated sectors, such as autonomous mobility, clinical healthcare, or global finance, where mislabeled training data can lead to severe safety failures, compliance violations, or immediate operational liabilities.
- You are migrating from general-purpose conversational systems to domain-specific, highly specialized applications that require custom terminology, proprietary product lines, or localized dialect understanding.
It may not be the right priority if:
- Your application is in an early validation phase utilizing standard commercial pre-trained models, where zero-shot or few-shot prompting techniques are sufficient to meet your initial business outcomes without proprietary model tuning.
- Your core business logic relies primarily on unsupervised learning methods, anomaly detection, or statistical clustering where explicit ground-truth targets are not required to generate value.
Why Data Labeling Matters for Retail and E-commerce
Deploying machine learning systems within enterprise environments requires structured, annotated datasets to achieve measurable returns on investment. The performance of customer-facing applications, predictive inventory engines, and automated discovery tools is bound directly to the fidelity of their underlying training labels.
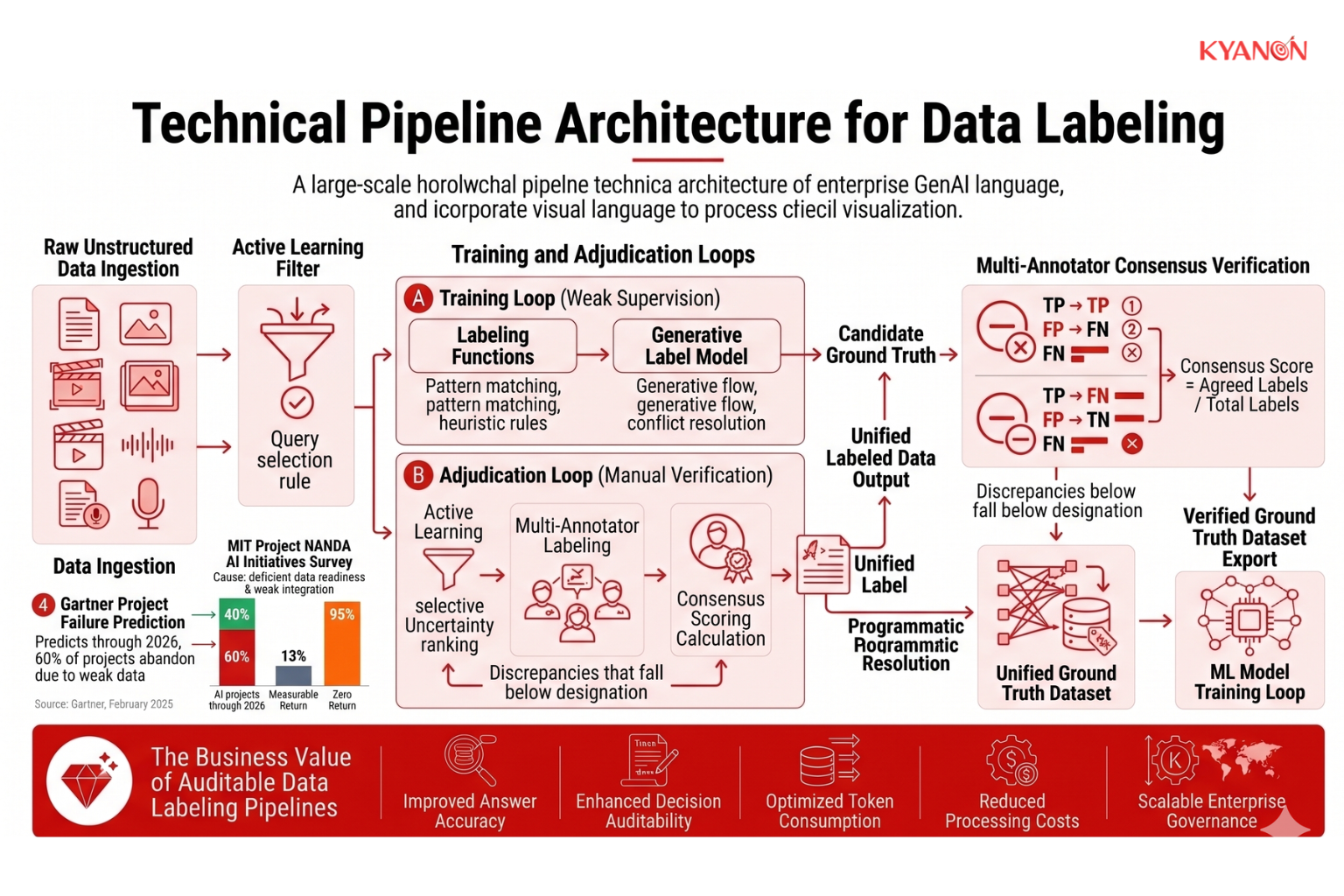
A research survey from 2020 indicates that poor data quality costs organizations an average of USD 12.9 million annually, representing a major financial bottleneck for unstandardized data pipelines. This operational challenge is further validated by a Gartner study from February 2025, which predicts that through 2026, organizations will abandon 60% of AI projects that are not supported by AI-ready data, identifying poor data readiness as the leading point of failure for enterprise models.
Furthermore, a 2025 preliminary report from MIT’s Project NANDA covering 300-plus AI initiatives revealed that 95% of organizations saw zero measurable return from generative AI due to deficient data readiness and weak workflow integration.
For retail and e-commerce platforms, visual search and advanced recommendation engines are key drivers of digital transaction volume. Achieving high classification accuracy across catalog items is critical because search users represent high-intent shoppers who trust visual and textual search bars to locate specific products.
When catalog images are annotated with detailed, structured attributes, computer vision systems can extract high-level semantic features, identifying object types, materials, styles, and patterns. According to Gartner, retailers implementing visual search capabilities see an average conversion rate increase of 30%, showing how accurate item tagging directly unlocks search-driven revenue.
By converting raw images into rich, labeled training datasets, platforms can decrease zero-result rates and minimize exit-after-search actions, turning unorganized collections into structured, discoverable assets.
Common Misconceptions
Misconception 1: “Data labeling is quick and easy to automate.”
Reality: Manual human-in-the-loop validation remains non-substitutable for complex unstructured datasets, as completely automated labeling systems fail to resolve subtle semantic ambiguities and edge cases. While programmatic pre-labeling tools can accelerate initial runs, manual intervention is necessary to train high-accuracy models. Without human verification, automated labelers can propagate systematic biases and classification errors, such as a self-driving system misidentifying a partially obstructed warning sign.
Misconception 2: “More data is always better than clean data.”
Reality: A highly curated, smaller dataset with perfect semantic consistency consistently outperforms a massive, noisy dataset containing conflicting labels. Large, chaotic datasets introduce high noise, which confuses gradient descent algorithms and causes model drift.
Misconception 3: “Data labeling is always a cheap, commoditized process.”
Reality: Complex domain labeling (such as 3D medical scans or conversational NLP transcripts) requires certified subject matter experts and rigorous validation protocols. Cheap, low-quality labels trigger expensive re-labeling loops, inflate the total cost of ownership (TCO), and delay enterprise product time-to-market.
Misconception 4: “Data labeling is an objective, purely technical activity.”
Reality: Annotation guidelines are inherently subjective and reflect human bias, which can become encoded in the model’s weights and result in unfair predictions. MLOps workflows require alignment audits and bias mitigation protocols to prevent systematic distortion.
How Kyanon Digital Applies Data Labeling
Kyanon Digital coordinates managed data labeling workflows across Vietnam, Singapore, Malaysia, Thailand, ANZ, the US, and Nordic Europe to accelerate time-to-market for enterprise AI solutions while minimizing overall total cost of ownership.
Our teams act as an implementation-first engineering partner, managing dataset ingestion, annotation coordination, tooling customization, and multi-layered quality control for computer vision and natural language processing models.
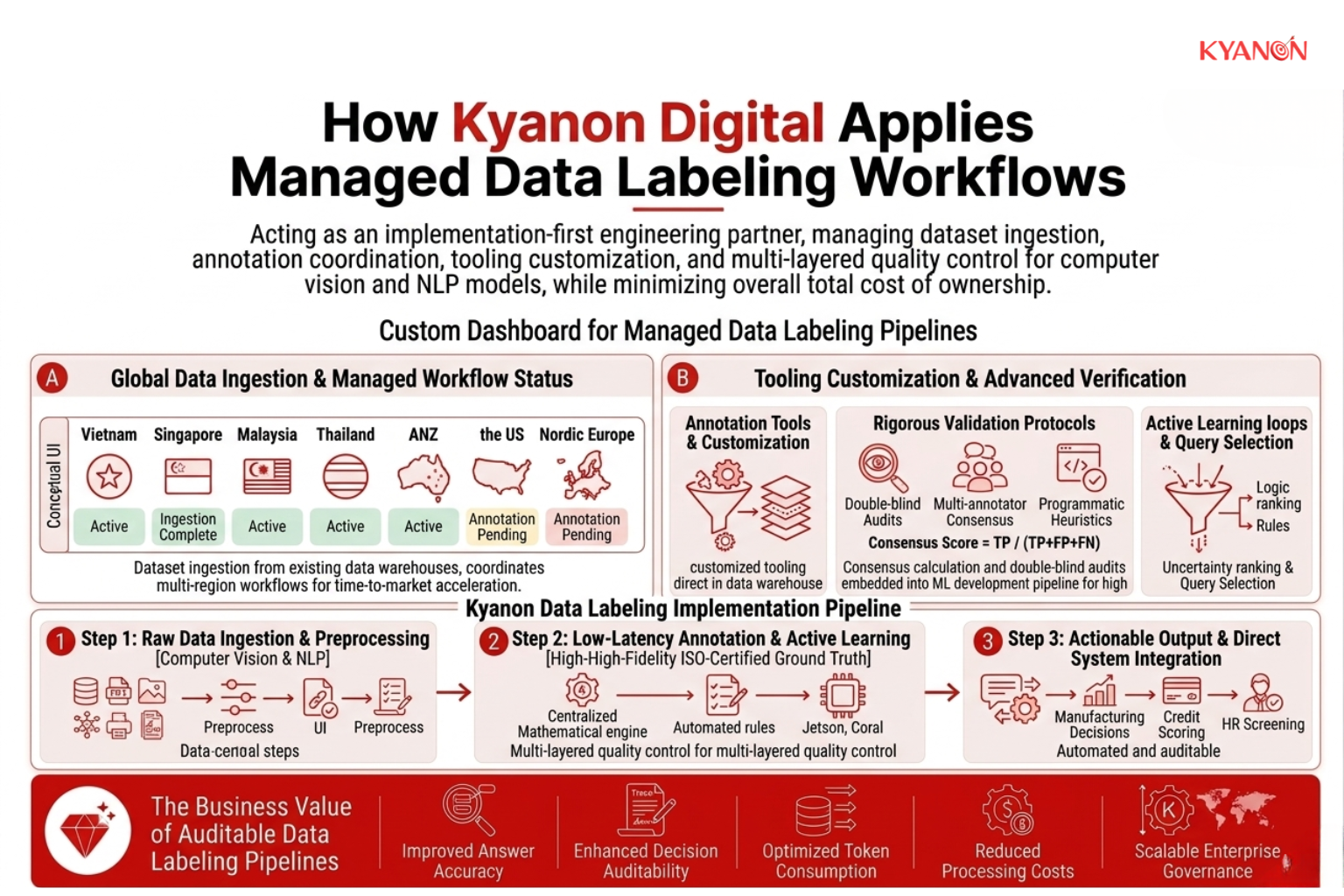
We address the bottlenecks of training set engineering by deploying customized annotation tools and active learning loops directly within your existing data warehouse.
Rather than treating data annotation as an isolated consulting task, Kyanon Digital embeds rigorous validation protocols, including consensus calculations and double-blind audits, into the core machine learning software development pipeline.
This ensures that your technical teams receive high-fidelity, ISO-certified ground truth data, significantly reducing time-to-market, preventing production model drift, and optimizing the total cost of ownership of your enterprise AI infrastructure.
→ Explore our Machine Learning Software Development services.







")




 Create project brief with AI
Create project brief with AI