What is the Fine-Tuning?
Fine-tuning is a machine learning process that adjusts the weights of a pre-trained foundation model using a smaller, domain-specific dataset to optimize its performance for specific tasks or stylistic behaviors. This mechanism transforms a generalized artificial intelligence into a specialized tool calibrated for exact enterprise requirements.
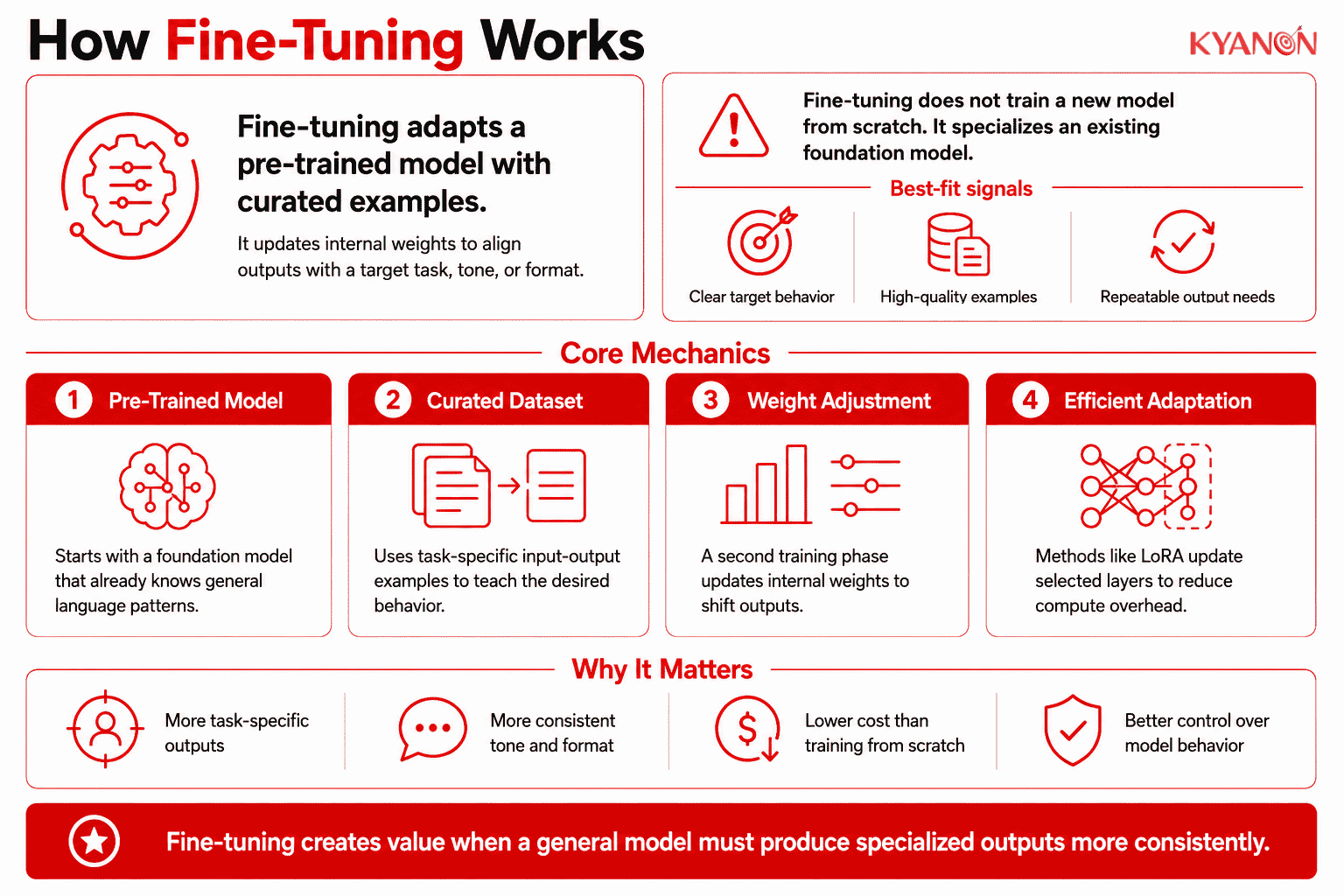
How the Fine-Tuning Works
Fine-tuning works by taking a foundation model that has already learned general language patterns and subjecting it to a secondary training phase with curated examples, modifying its internal parameters to align its output format and tone with the specialized dataset. This process relies on adjusting the neural network’s mathematical probabilities rather than building a new model from scratch.
Pre-trained Foundation Model
The foundational architecture serves as the baseline, containing vast amounts of general linguistic or structural data. It provides the core reasoning and language generation capabilities that will be subsequently specialized.
Curated Dataset
This consists of high-quality, task-specific examples structured as input-output pairs. The precision and relevance of this dataset directly dictate the targeted behavior and output quality of the resulting specialized model.
Weight Adjustment
During the secondary training phase, the model updates its internal parameters (weights) based on the curated dataset. Techniques like LoRA (Low-Rank Adaptation) restrict these updates to specific layers, minimizing computational overhead while shifting the model’s behavior.
Fine-Tuning vs Retrieval-Augmented Generation (RAG)
Both approaches customize AI outputs for enterprise use cases but differ fundamentally in how they handle data and knowledge retrieval.
|
Dimension |
Fine-Tuning |
RAG (Retrieval-Augmented Generation) |
|
Core mechanism |
Alters internal model weights permanently |
Connects frozen model to external databases |
|
Fact retrieval accuracy |
Moderate to low (prone to hallucinations) |
High (sources directly from provided documents) |
|
Upfront complexity |
High (requires dataset curation and training compute) |
Medium (requires vector database and pipeline setup) |
|
Dynamic data handling |
Static (requires retraining to update knowledge) |
Real-time (updates as external database updates) |
|
Best for |
Adjusting tone, formatting, and domain vocabulary |
Answering questions based on specific company data |
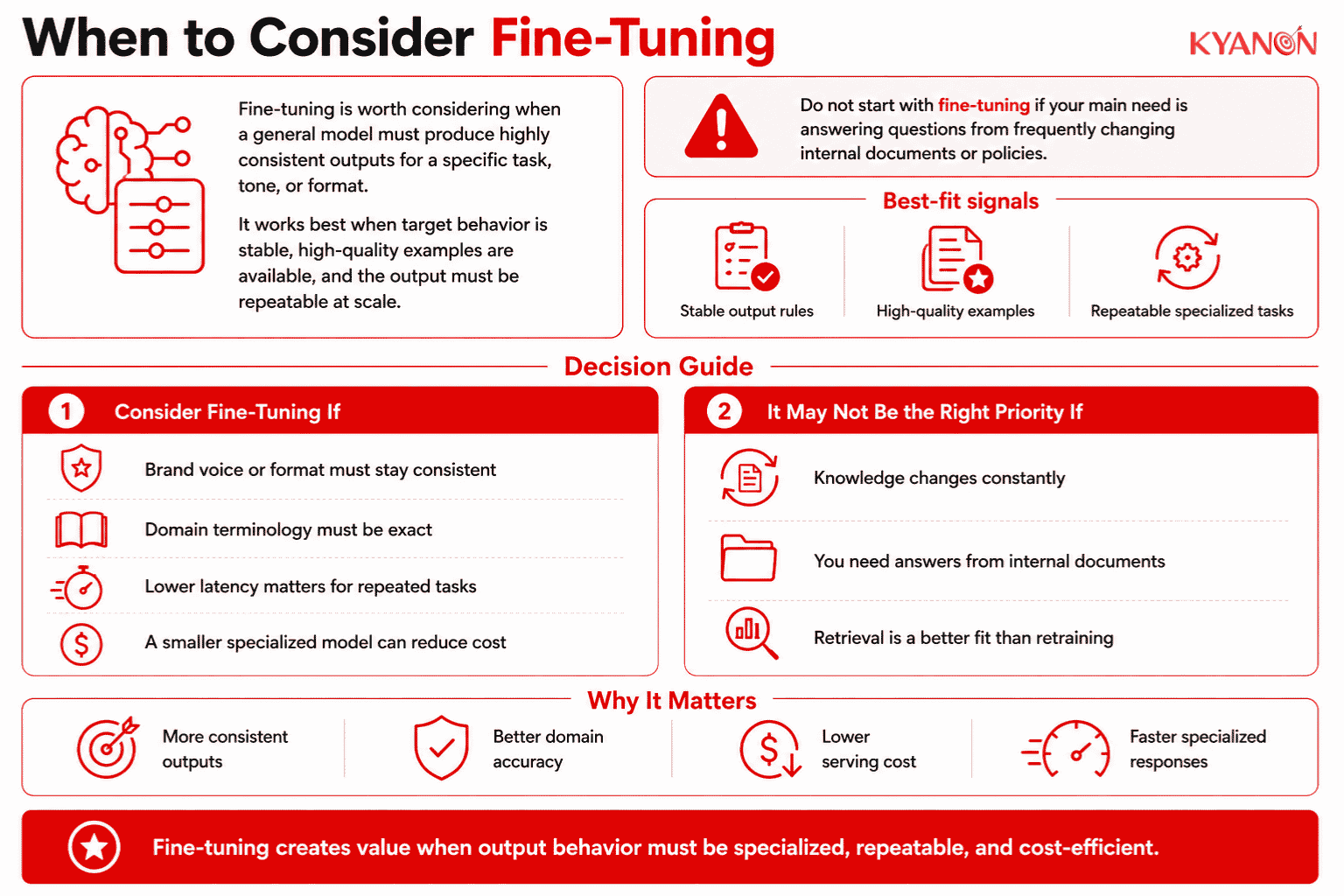
When to Consider the Fine-Tuning
Consider fine-tuning if:
- Your organization requires an AI model to consistently output responses in a highly specific, mandated brand voice or a strict regulatory format.
- You are deploying an AI assistant for a specialized technical domain where the base model consistently misinterprets or fails to generate exact industry-specific terminology.
- Your application demands reduced latency and lower inference costs by utilizing a smaller, highly specialized model rather than querying a massive, generalized LLM.
It may not be the right priority if:
- Your primary goal is to answer internal queries based on a constantly changing repository of employee handbooks, policies, or product catalogs.
Why Fine-Tuning Matters for Enterprise AI
Fine-tuning enables organizations to transition from relying on generic external APIs to operating specialized, proprietary models that execute specific workflows with high precision and lower latency.
OpenAI reported in 2025 that Lowe’s improved product tagging accuracy by 20% and error detection by 60% after fine-tuning GPT-3.5 on its product data. For an e-commerce or marketplace operator, that is not a model-lab metric; it is a search, discoverability, and catalog-governance metric tied to revenue quality.
OpenAI’s 2025 documentation states that supervised fine-tuning produces a model that more reliably follows the desired style and content for a specific use case, while its model-optimization guidance frames fine-tuning as part of an eval-driven workflow used to improve task performance and efficiency. For enterprise teams, that makes fine-tuning a specialization lever, not a generic “make the model smarter” step.
Common Misconceptions
“Fine-tuning is the best way to teach our LLM new internal facts and company data”
Reality: Fine-tuning is highly inefficient for factual knowledge injection and freezes information at the time of training. It is designed to teach behavior, formatting, and tone, while RAG is the standard for real-time factual retrieval.
“Feeding more data into the fine-tuning pipeline will automatically make the model more accurate”
Reality: Quality strictly outweighs quantity in fine-tuning pipelines. Injecting excessive, low-quality, or conflicting data often causes catastrophic forgetting, stripping the model of its baseline reasoning capabilities and increasing hallucinations.
“If a fine-tuned model performs poorly, we can easily revert it to its original state”
Reality: Fine-tuning alters the model’s structural weights permanently. Once a model undergoes fine-tuning, removing the degraded behavioral history is technically difficult and often requires starting the fine-tuning process over from the baseline model.

How Kyanon Digital Applies Fine-Tuning
Kyanon Digital implements fine-tuning using parameter-efficient techniques like LoRA and QLoRA for enterprise clients needing AI models specialized in their industry vocabulary and compliance requirements across Southeast Asia, ANZ, and the US.
Our approach focuses on adapting secure, open-weight models to ensure organizations retain full control over their proprietary workflows while achieving measurable reductions in inference costs.
→ Explore our LLM fine-tuning and machine learning services.







")




 Create project brief with AI
Create project brief with AI