What is LLM Fine-Tuning?
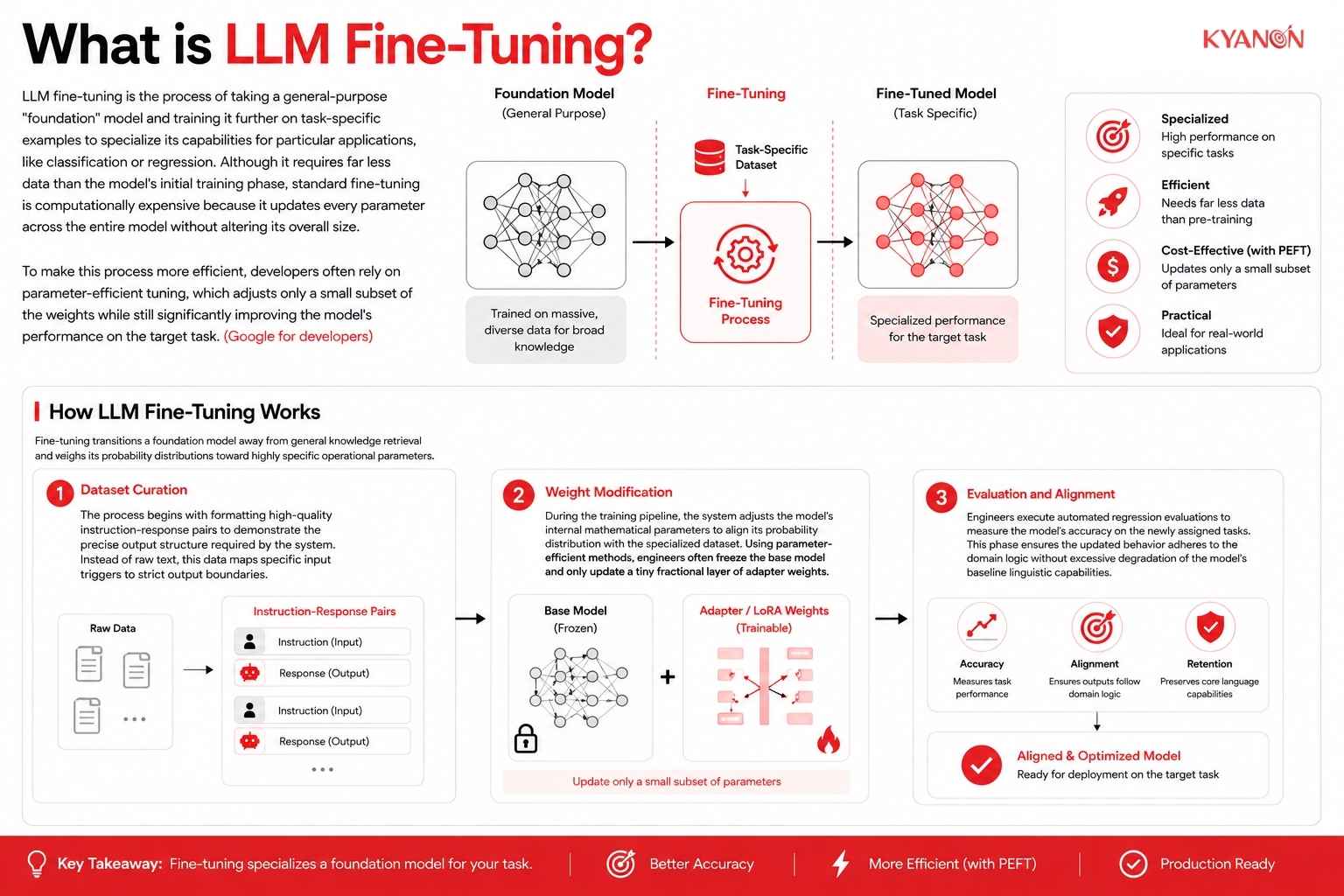
LLM fine-tuning is the process of taking a general-purpose “foundation” model and training it further on task-specific examples to specialize its capabilities for particular applications, like classification or regression. Although it requires far less data than the model’s initial training phase, standard fine-tuning is computationally expensive because it updates every parameter across the entire model without altering its overall size.
To make this process more efficient, developers often rely on parameter-efficient tuning, which adjusts only a small subset of the weights while still significantly improving the model’s performance on the target task. (Google for developers)
How LLM Fine-Tuning works
Fine-tuning transitions a foundation model away from general knowledge retrieval and aligns its probability distributions toward highly specific operational parameters.
Dataset Curation
The process begins with formatting high-quality instruction-response pairs to demonstrate the precise output structure required by the system. Instead of raw text, this data maps specific input triggers to strict output boundaries.
Weight Modification
During the training pipeline, the system adjusts the model’s internal mathematical parameters to align its probability distribution with the specialized dataset. Using parameter-efficient methods, engineers often freeze the base model and only update a tiny fractional layer of adapter weights.
Evaluation and Alignment
Engineers execute automated regression evaluations to measure the model’s accuracy on the newly assigned tasks. This phase ensures the updated behavior adheres to the domain logic without excessive degradation of the model’s baseline linguistic capabilities.
LLM Fine-Tuning vs RAG (Retrieval-Augmented Generation)
Both approaches customize AI systems for enterprise use, but they solve fundamentally different problems regarding knowledge access and architectural behavior.
|
Dimension |
LLM Fine-Tuning | RAG (Retrieval-Augmented Generation) |
| Primary objective | Modifying behavior, tone, and format |
Injecting factual, real-time knowledge |
|
Core mechanism |
Updates internal model weights | Retrieves external documents dynamically |
| Data updates | Requires full engineering retraining loop |
Instant via vector database updates |
|
Hallucination risk |
High if queried outside training data | Low (grounded in retrieved context) |
| System analogy | Cramming for an exam |
Taking an open-book exam |
When to consider LLM Fine-Tuning
Consider LLM Fine-Tuning if:
- Your AI system must consistently output responses in strict, proprietary formats, such as generating clean nested JSON schemas for internal APIs.
- You need to imprint a highly regulated corporate tone or domain-specific linguistic style (like medical terminology or legal phrasing) into the foundational behavior of the model.
- You aim to reduce inference latency and API costs by training a smaller, specialized open-source model to execute a narrow task previously handled by a massive generalized model.
It may not be the right priority if:
- Your primary objective is granting the model access to rapidly changing internal knowledge bases, factual documentation, or real-time inventory systems.
Why LLM Fine-Tuning matters for Enterprise AI
LLM fine-tuning matters for enterprise AI because it shifts organizations away from basic, costly experimentation toward highly specialized, task-driven automation that delivers measurable ROI. (Deloitte)
While open-domain large language models (LLMs) excel at general knowledge, they lack the specific stylistic guidelines, industry-compliant formatting, and resource efficiencies required to run corporate applications at scale. Fine-tuning acts as the primary tool to permanently adapt an AI model to an organization’s distinct operational architecture.
Four primary reasons why fine-tuning is vital for enterprise data ecosystems:
- Scaling “agentic” architectures and task-specific models
- Drastic reduction of cloud infrastructure costs
- Achieving strict formatting and deterministic compliance
- Mitigating third-party data risks
Common misconceptions
Fine-tuning is the best way to add new knowledge to our model
Reality: Fine-tuning modifies the model’s internal weights to adapt its tone, behavior, formatting, or task execution style, not its factual knowledge. Trying to inject thousands of internal corporate PDFs into a model via fine-tuning causes the model to hallucinate or misremember specific numbers. To give a model access to factual knowledge or documents, you must use RAG.
You need massive datasets and hundreds of thousands of dollars to train a model
Reality: Modern parameter-efficient architectures mean small engineering teams can fine-tune high-performing models on a minimal budget. By using techniques like LoRA (Low-Rank Adaptation), you only freeze the original model base and train a tiny fractional layer of adapter weights. Curated instruction-tuning datasets of just 1,000 to 5,000 high-quality samples can successfully reshape a model’s operational behavior.
A fine-tuned model keeps all of its original capabilities
Reality: Models suffer from a mathematical phenomenon known as Catastrophic Forgetting. When you optimize an LLM to become a specialist in one highly narrow task, the weight updates overwrite its generalized reasoning capabilities, causing the model to lose its baseline competency in general logic or math.
How Kyanon Digital applies LLM Fine-Tuning
Kyanon Digital delivers llm fine-tuning services for enterprise clients needing models that speak their exact domain language, spanning legal, medical, retail, and financial sectors with higher reliability than general models. Our engineering teams utilize parameter-efficient training pipelines to adapt open-source architectures, ensuring organizations achieve measurable reductions in total cost of ownership (TCO) and latency while maintaining strict control over their proprietary data environments.
Explore our AI and ML services:







")




 Create project brief with AI
Create project brief with AI