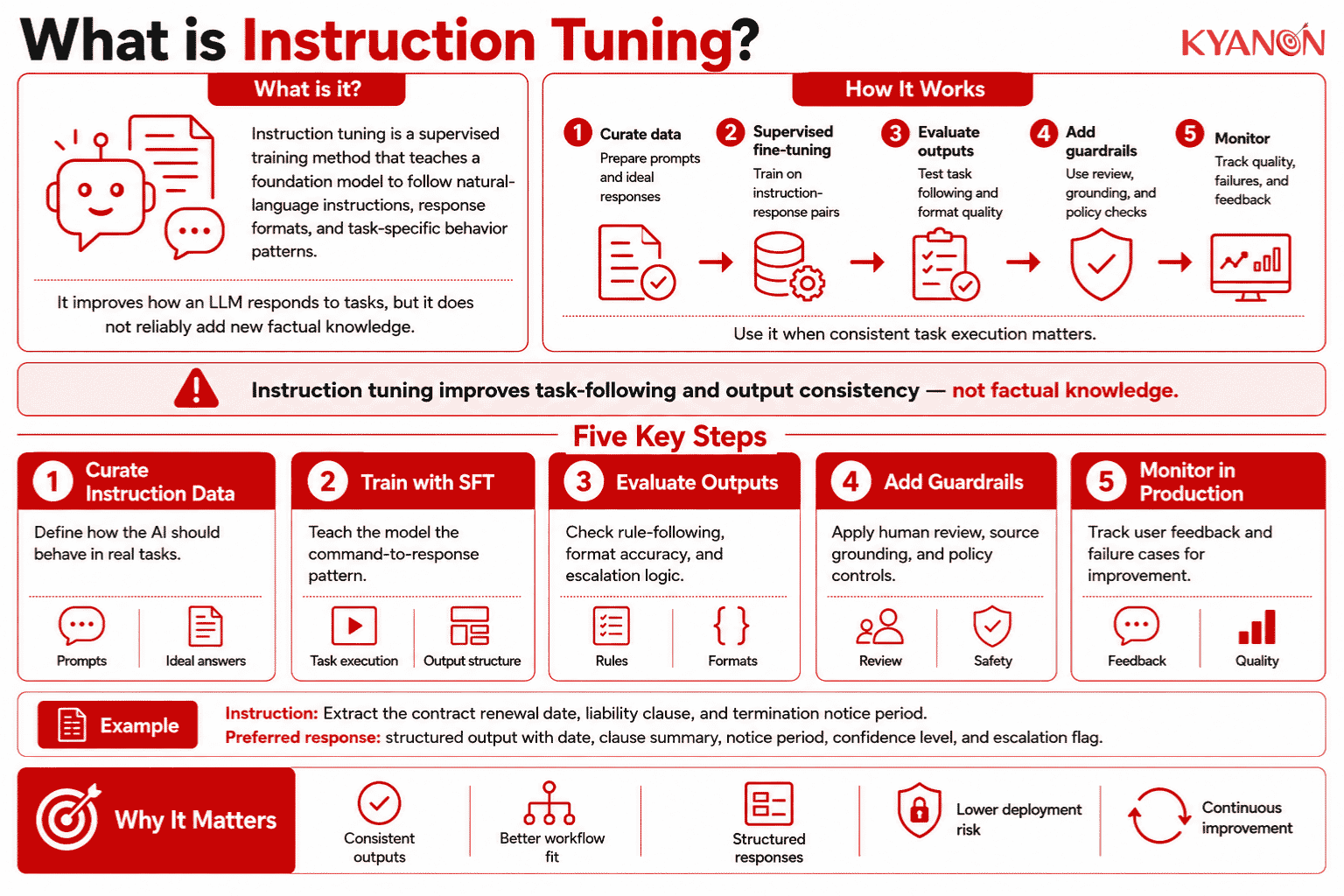
What is Instruction Tuning?
Instruction tuning is a supervised training method that teaches a foundation model to follow natural-language instructions, response formats, and task-specific behavior patterns. It improves how an LLM responds to tasks, but it does not reliably add new factual knowledge to the model.
How Instruction Tuning Works
Instruction tuning works by training a pre-trained model on curated instruction-response pairs, usually through supervised fine-tuning. The model learns the pattern of command to response, making it more consistent at following tasks, formats, and workflow rules.
The Training Process
| Step | What happens |
Business meaning |
|
1. Curate instruction data |
Teams prepare examples of prompts and ideal responses. | Defines how the AI assistant should behave in real business tasks. |
| 2. Train with supervised fine-tuning | The model learns from instruction-response pairs. |
Improves consistency in task execution and output structure. |
|
3. Evaluate outputs |
Teams test whether the model follows rules, formats, and escalation logic. | Reduces risk before deployment. |
| 4. Add guardrails | Human review, source grounding, and policy checks are added where needed. |
Keeps high-risk workflows controlled. |
|
5. Monitor in production |
Output quality, failure cases, and user feedback are tracked. |
Supports continuous improvement after launch. |
Example
- Instruction: “Extract the contract renewal date, liability clause, and termination notice period.”
- Preferred response: A structured output with the renewal date, liability summary, termination notice period, confidence level, and escalation flag.
For enterprise AI assistants, instruction tuning is useful when the same task must be completed repeatedly in a consistent format.
Instruction-Response Dataset
The instruction-response dataset defines how the model should respond to business tasks. For enterprise use cases, the dataset should include accepted output formats, refusal rules, escalation examples, and examples of weak responses to avoid.
Supervised Fine-Tuning
Supervised fine-tuning adjusts the model so it follows instructions more consistently. The objective is not to memorize company documents, but to improve behavior such as formatting, tone, task completion, and workflow discipline.
Evaluation and Guardrails
Evaluation checks whether the tuned model follows instructions under normal, ambiguous, and risky inputs. Guardrails are still required because instruction-tuned models can hallucinate, over-follow user assumptions, or produce answers that sound correct but fail compliance requirements.
Instruction Tuning vs Pre-Training vs Domain Fine-Tuning
Instruction tuning teaches a model to follow instructions, while pre-training builds general language capability, and domain fine-tuning adapts a model to a specific industry or task.
|
Dimension |
Pre-Training | Instruction Tuning |
Domain Fine-Tuning |
|
Main goal |
Build broad language understanding | Teach instruction-following behavior |
Adapt the model to a domain or task |
| Primary data format | Large-scale unstructured text | Curated instruction-response pairs |
Specialized domain text or labeled examples |
|
Typical output |
General foundation model | Assistant-like model that follows prompts | Model adapted to a business domain |
| Best for | Building base model capability | Enterprise assistants and structured workflows |
Legal, medical, retail, finance, or industry-specific use cases |
|
Adds new knowledge? |
Learns broad knowledge during training | Not reliable for factual knowledge injection | Can adapt domain behavior, but not ideal for live facts |
| Business use | Base model development | Consistent task execution |
Specialized performance improvement |
|
Key risk |
Expensive and data-intensive | Over-following user framing or weak instructions |
Forgetting base capabilities or overfitting |
Instruction Tuning vs Fine-Tuning
Instruction tuning is a specific type of fine-tuning focused on teaching a model how to follow instructions, while general fine-tuning can target broader task performance, domain adaptation, or output style.
|
Dimension |
Instruction Tuning |
Fine-Tuning |
|
Primary purpose |
Improve instruction-following behavior | Adapt model behavior or performance |
| Training data | Instruction-response pairs |
Task-specific, labeled, or domain-specific data |
|
Main output |
More consistent task execution | Better performance on a specific use case |
| Knowledge injection | Weak method for adding facts |
Still limited for live factual grounding |
|
Best for |
AI assistants, data extraction, compliance workflows, structured responses | Classification, domain adaptation, model specialization |
| Key risk | Model may become too agreeable to user framing |
Model may lose general capability if training data is narrow |
|
Business value |
Better workflow consistency |
Better task performance when scope is clear |
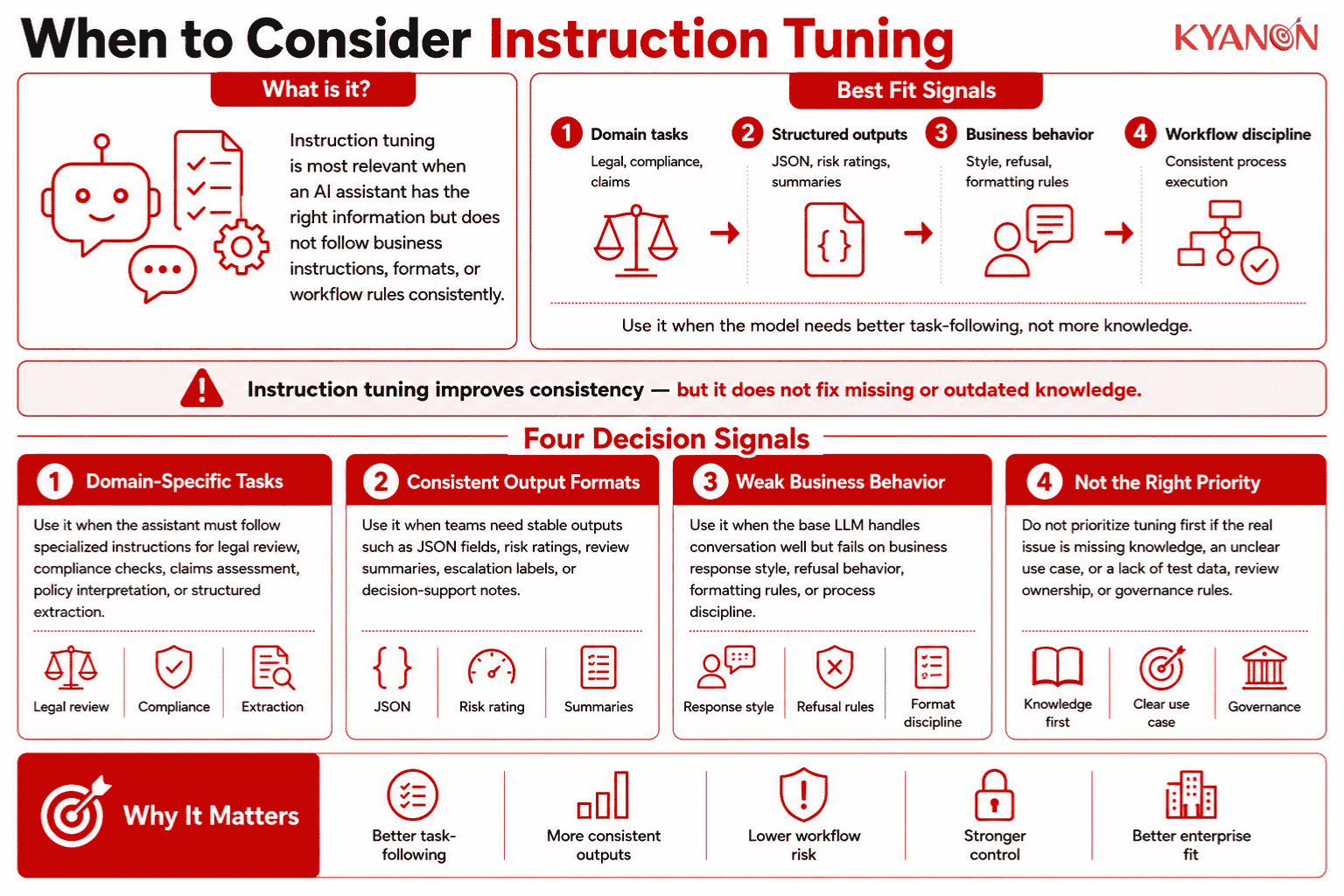
When to Consider Instruction Tuning
Instruction tuning is relevant when an enterprise AI assistant has access to the right information but does not follow business instructions, formats, or workflow rules consistently.
Consider Instruction Tuning if:
- Your AI assistant must follow domain-specific instructions for legal review, compliance checking, claims assessment, policy interpretation, or structured data extraction.
- Your team needs consistent output formats such as JSON fields, risk ratings, review summaries, escalation labels, or decision-support notes.
- Your current LLM performs well in general conversation but fails on business-specific response style, refusal behavior, formatting rules, or process discipline.
It may not be the right priority if:
- Your main issue is missing, outdated, or fragmented knowledge. Retrieval-Augmented Generation, data integration, or knowledge base improvement should usually come first.
- Your use case is still unclear. Instruction tuning works best when the task, output format, evaluation criteria, and failure cases are already defined.
- Your organization lacks test data, review ownership, or governance rules. Tuning without evaluation can make a model sound better while becoming harder to control.
Why Instruction Tuning Matters for Enterprise AI Assistants
Instruction tuning matters for enterprise AI assistants because AI adoption is moving from pilots into business workflows, where consistent task execution is more important than model size alone. According to McKinsey’s 2025 State of AI survey, 78% of respondents said their organizations use AI in at least one business function, making workflow reliability, instruction-following behavior, and governance more important for enterprise deployment.
This means model behavior should be evaluated against business outcomes: task accuracy, format compliance, source usage, escalation quality, review time, and total cost of ownership.
Recent research shows that instruction tuning should be treated as behavior alignment, not factual grounding. A 2025 ACL study found that after instruction tuning, three out of four tested models became more susceptible to misinformation presented by the user role, showing why enterprise assistants still need retrieval, validation, escalation rules, and human review.
For example, a legal operations team may use instruction tuning to make an AI assistant produce review notes in a fixed format: issue summary, clause risk, evidence reference, confidence level, and escalation recommendation. The measurable value comes from repeatable review behavior, not from assuming the tuned model has memorized every legal document.
Common Misconceptions
The biggest enterprise misconception is that instruction tuning turns an LLM into a company’s knowledge base.
“If we instruct on company documents, the model will know our policies.”
Reality: Instruction tuning mainly teaches response behavior, not reliable factual recall. If the assistant must answer from current policies, contracts, or product data, use RAG or governed retrieval before tuning.
“Fine-tuning always makes the model better.”
Reality: Instruction tuning can improve workflow usability, but a narrow or low-quality dataset can reduce general capability. The business question is not “Can we tune it?” but “Can we prove it performs better on our approved evaluation set?”
“Instruction-tuned models are automatically more objective.”
Reality: Instruction tuning can make a model sound more helpful, but that does not guarantee factual correctness or resistance to user misinformation. Enterprise assistants still need source grounding, escalation rules, and human review for high-risk outputs.
“Instruction tuning is the only way to teach instruction following.”
Reality: Many foundation models can follow instructions through prompting, system messages, workflow design, and retrieval context. Instruction tuning becomes more relevant when the same workflow must run repeatedly with strict output rules and measurable failure thresholds.

How Kyanon Digital Applies Instruction Tuning
Kyanon Digital applies instruction tuning when building enterprise AI assistants that must follow domain-specific instructions for legal review, compliance checking, data extraction, workflow routing, and internal knowledge operations. The implementation approach combines model selection, instruction dataset design, RAG where factual grounding is required, structured output rules, human evaluation, and deployment monitoring for enterprise clients across Vietnam, Singapore, Malaysia, Thailand, ANZ, the US, and Nordic Europe.
→ Explore our machine learning software development services.







")




 Create project brief with AI
Create project brief with AI