What is the Foundation Model?
A foundation model is a massive artificial intelligence framework trained on extensive, unannotated datasets using self-supervised learning, creating a general-purpose base that can be adapted for numerous specific downstream tasks. This architectural approach shifts AI development from training narrow, single-purpose algorithms from scratch to fine-tuning highly versatile systems.
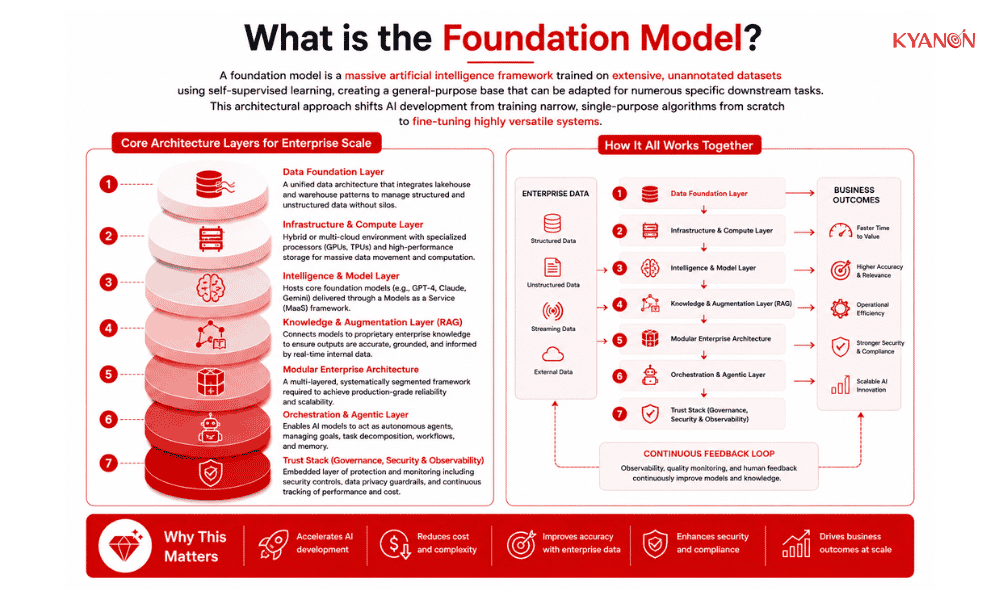
Core Architecture Layers for Enterprise Scale
- Data foundation layer: A unified data management architecture that integrates lakehouse and warehouse patterns to handle both structured and unstructured data without creating silos. Key components include automated data ingest, active archiving, and metadata catalogs.
- Infrastructure & compute layer: The foundational hardware and cloud environment (hybrid or multi-cloud) equipped with specialized processors (e.g., GPUs, TPUs) and high-performance storage designed to handle massive data movement and distributed computation.
- Intelligence & model layer: The tier that houses the core foundation AI models (such as GPT-4, Claude, and Gemini), frequently utilized through a Models as a Service (MaaS) framework.
- Knowledge & augmentation layer (RAG): The integration layer that connects foundation models to proprietary enterprise knowledge. This ensures that AI outputs remain accurate, grounded, and informed by real-time internal data.
- Modular enterprise architecture: A multi-layered, systematically segmented framework required to achieve production-grade reliability and scalability in enterprise environments.
- Orchestration & agentic layer: A specialized framework that empowers AI models to function as autonomous agents by managing complex operational processes, including goal definition, task decomposition, and memory management.
- Trust stack (governance, security & observability): An embedded layer of protection and monitoring that includes automated security controls, data privacy guardrails, and continuous tracking of model performance and operational costs.
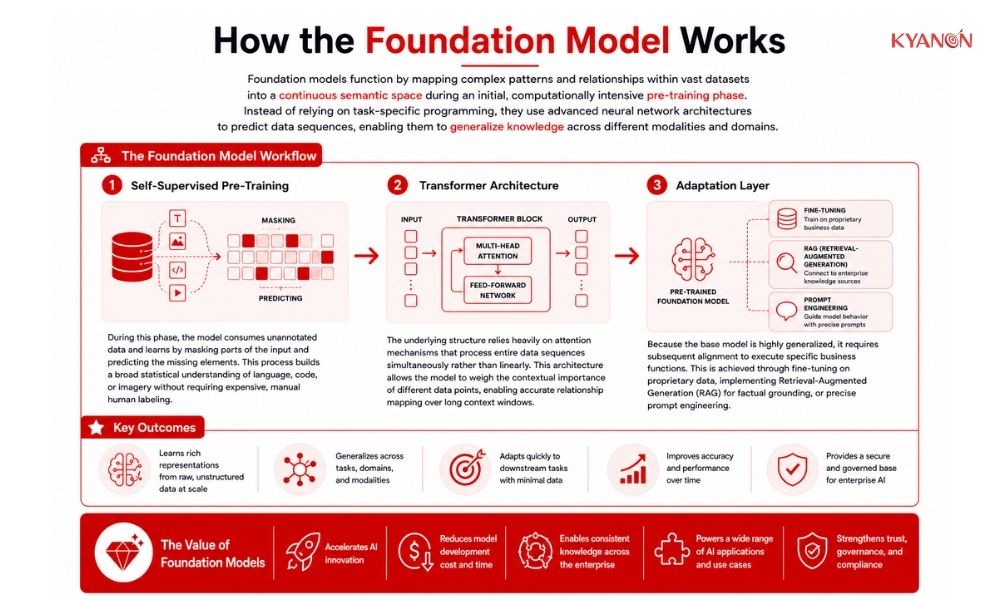
How the Foundation Model Works
Foundation models function by mapping complex patterns and relationships within vast datasets into a continuous semantic space during an initial, computationally intensive pre-training phase. Instead of relying on task-specific programming, they use advanced neural network architectures to predict data sequences, enabling them to generalize knowledge across different modalities and domains.
Self-Supervised Pre-Training
During this phase, the model consumes unannotated data and learns by masking parts of the input and predicting the missing elements. This process builds a broad statistical understanding of language, code, or imagery without requiring expensive, manual human labeling.
Transformer Architecture
The underlying structure relies heavily on attention mechanisms that process entire data sequences simultaneously rather than linearly. This architecture allows the model to weigh the contextual importance of different data points, enabling accurate relationship mapping over long context windows.
Adaptation Layer
Because the base model is highly generalized, it requires subsequent alignment to execute specific business functions. This is achieved through fine-tuning on proprietary data, implementing Retrieval-Augmented Generation (RAG) for factual grounding, or precise prompt engineering.
Foundation Model vs Large Language Model (LLM)
Both approaches customize AI outputs for enterprise use cases but differ fundamentally in how they handle data and knowledge retrieval.
|
Dimension |
Foundation Model |
Large Language Model (LLM) |
|
Scope of Modality |
Multimodal (Text, Image, Code, Audio) |
Primarily unimodal (Text) |
|
Primary Function |
Generalized base for varied adaptations |
Natural language processing and generation |
|
Adaptability |
|
Narrower (optimized for linguistics) |
|
Architectural Hierarchy |
Parent category |
Sub-category |
|
Enterprise Use Case |
Cross-functional AI infrastructure |
Chatbots, text summarization, translation |
When to Consider the Foundation Model
Consider the foundation model if:
- Your organization needs to automate diverse, cross-departmental tasks requiring different modalities, such as analyzing legal text and processing visual quality control data simultaneously.
- Your engineering team plans to deploy multiple specialized generative AI applications over the next 12–18 months and requires a unified, scalable architectural base.
- You have massive archives of unstructured enterprise data and need a system capable of extracting insights without manually labeling millions of individual records.
It may not be the right priority if:
- Your immediate requirement is a highly specific, low-latency predictive task, such as numerical anomaly detection in IoT sensors, where traditional, lightweight machine learning models are far more cost-effective.
Why Foundation Models Matter for Enterprise Technology
Deploying adaptable base models shifts capital expenditure away from redundant algorithm training toward high-value application development and proprietary data integration.
Deploying adaptable foundation models shifts enterprise investment away from repeatedly training narrow AI systems toward reusable AI infrastructure, proprietary data integration, and faster application delivery. Gartner forecasted in 2025 that worldwide end-user spending on generative AI models would reach $14.2 billion in 2025, with foundation generative AI models representing the largest category of enterprise AI investment. Gartner also predicted that by 2027, more than half of enterprise generative AI models will become domain-specific models optimized for particular industries or business functions.
Common Misconceptions
“Foundation models work perfectly out-of-the-box for enterprise tasks.”
Reality: Foundation models are starting points, not finished products. They operate probabilistically based on token patterns and require significant adaptation, such as fine-tuning or retrieval-augmented generation (RAG), to minimize hallucinations and excel at specific, high-stakes business logic.
“We need to train our own model from scratch to ensure true data security.”
Reality: Training cutting-edge foundation models requires prohibitive computational resources and budget. True strategic autonomy is achieved by selecting existing open-weight or commercial models and securely governing them with your private data within isolated cloud environments.
“A single, massive model will handle every use case across the company.”
Reality: Different architectural variations excel at distinct tasks like summarization, coding, or visual reasoning. Enterprises achieve lower total cost of ownership and higher accuracy by deploying an orchestrated mix of specialized, right-sized models rather than routing all queries through one massive endpoint.

How Kyanon Digital Applies the Foundation Model
Kyanon Digital implements foundation models as the core infrastructure for our Data & AI practice, carefully evaluating open-source and commercial options to match enterprise requirements. Our approach focuses on securely deploying the exact right model for each client’s specific performance criteria, computational budget, and data privacy constraints, utilizing RAG and fine-tuning to ensure the final generative application delivers measurable ROI without compromising proprietary data.
→ Explore our AI Systems Integration.







")




 Create project brief with AI
Create project brief with AI