What Is Transformer Architecture?
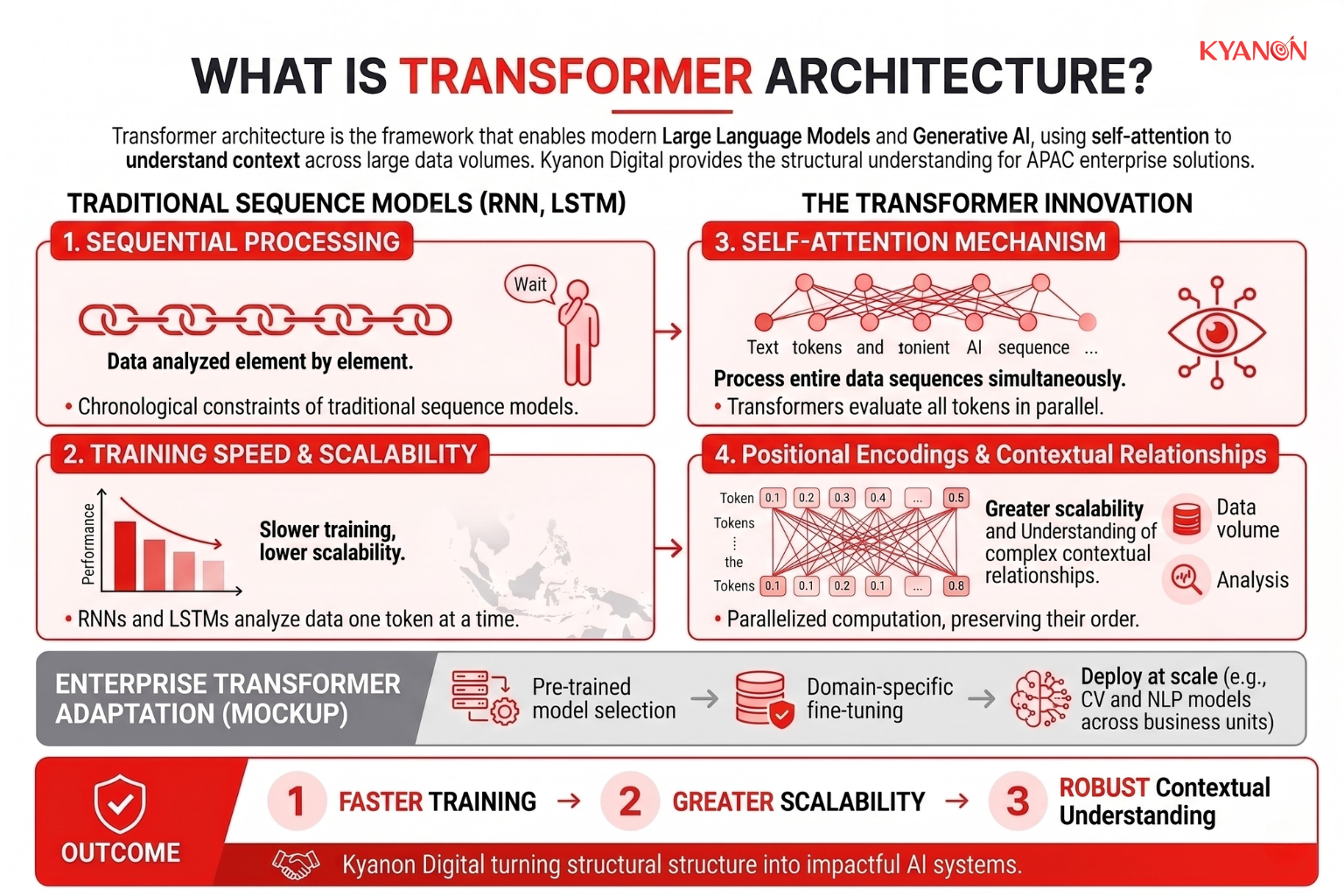
Transformer architecture is a deep learning framework that uses self-attention mechanisms to process entire data sequences simultaneously rather than sequentially. Unlike earlier neural network architectures such as Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks, which analyze data one element at a time, Transformers evaluate all tokens in a sequence in parallel while preserving their order through positional encodings. This design removes the chronological processing constraints of traditional sequence models, enabling highly parallelized computation, faster training, and greater scalability. As the foundational architecture behind modern large language models and generative AI systems, Transformers provide the structural framework for understanding complex contextual relationships across large volumes of data.
How Transformer Architecture Works
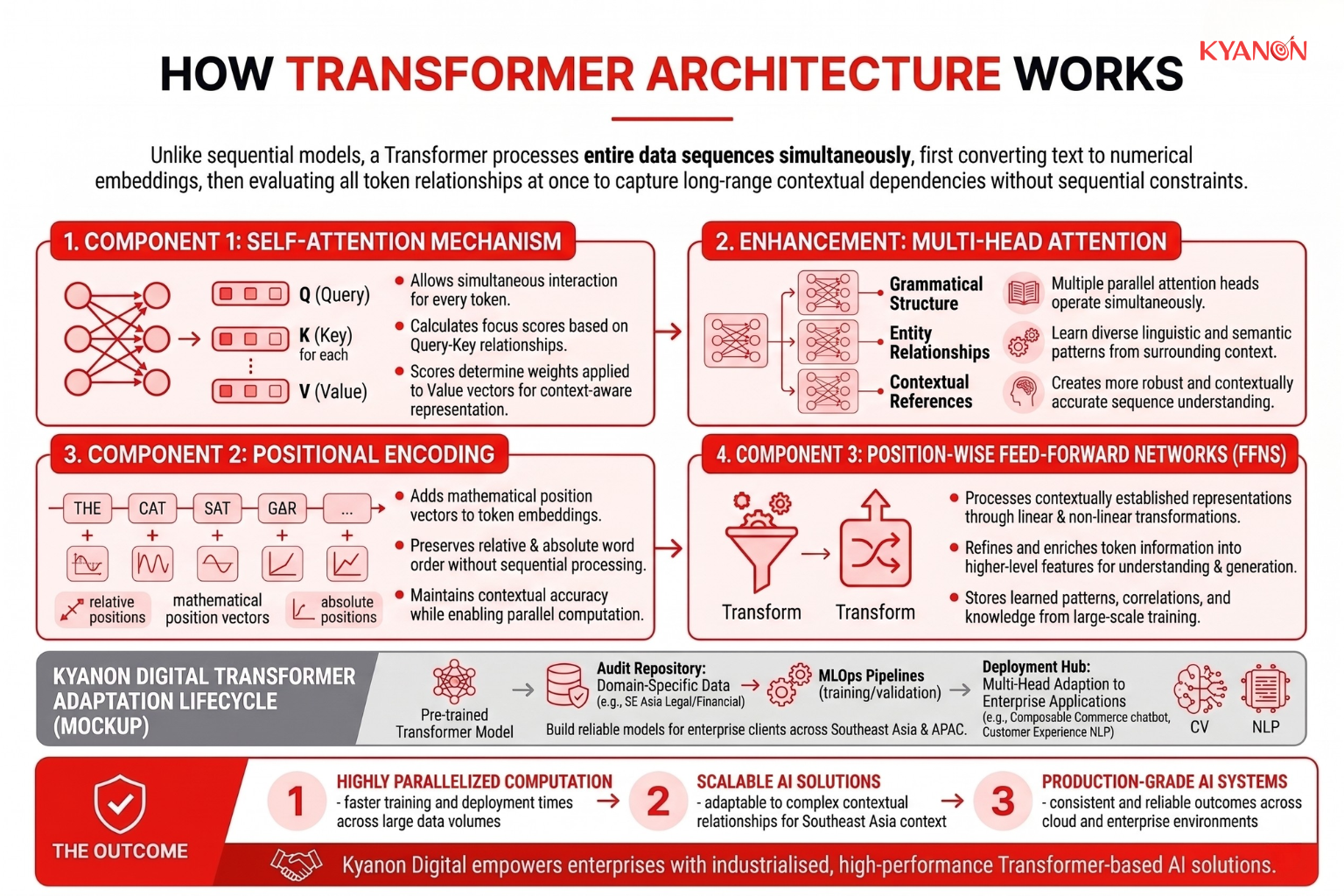
Unlike traditional models that process text sequentially, a Transformer analyzes all tokens in a sequence simultaneously. It first converts input text into numerical token embeddings and then evaluates the relationships between every token at once, enabling the model to capture long-range contextual dependencies without losing information across lengthy sequences.
Self-Attention Mechanism
Self-attention is the core computational mechanism that allows every token in a sequence to interact with every other token simultaneously. For each token, the model generates three representations:
- Query (Q): what the token is seeking from the surrounding context.
- Key (K): the information used to determine relevance to other tokens.
- Value (V): the actual content carried by the token.
The model calculates attention scores between queries and keys to determine how much focus each token should place on every other token. These scores are converted into attention weights and applied to the value vectors, producing context-aware representations that reflect the meaning of the entire sequence rather than isolated words.
To capture multiple types of relationships simultaneously, Transformers use Multi-Head Attention, where several attention mechanisms operate in parallel. Each attention head can learn different linguistic or semantic patterns, such as grammatical structure, entity relationships, or contextual references.
Positional Encoding
Because Transformers process all tokens at the same time, they do not inherently understand word order. Positional encoding addresses this limitation by adding mathematical position vectors to token embeddings before they enter the attention layers.
These encodings provide information about the relative and absolute positions of words within a sequence, allowing the model to distinguish between sentences that contain the same words but in different orders. By preserving sequence structure without introducing sequential processing, positional encoding enables efficient parallel computation while maintaining contextual accuracy.
Feed-Forward Networks (FFNs)
After contextual relationships are established through attention, the resulting token representations pass through Position-Wise Feed-Forward Networks (FFNs). These networks apply a series of linear and non-linear transformations to refine and enrich the information associated with each token.
While attention layers determine how information flows between tokens, FFNs are responsible for transforming those representations into higher-level features that support language understanding and generation. FFNs contain a significant portion of a Transformer’s parameters and serve as the primary mechanism for storing the patterns, correlations, and knowledge learned during large-scale training.
Transformer Architecture vs Recurrent Neural Network (RNN)
Both architectures are engineered to handle sequential data, but transformers prioritize parallel computation while RNNs execute strictly chronological processing.
|
Dimension |
Transformer Architecture | Recurrent Neural Network (RNN) |
| Data Processing | Parallel |
Sequential |
|
Compute Scaling |
Quadratic $O(N^2)$ | Linear $O(N)$ |
| Hardware Utilization | High (GPU optimized) |
Low (Bottlenecked) |
|
Context Retention |
Excellent over long sequences | Degrades over time (Vanishing gradient) |
| Best for | LLMs and complex generative tasks |
Small-scale time-series forecasting |
When to Consider Transformer Architecture
Consider Transformer Architecture if:
- Your engineering division is building custom generative models that require deep contextual understanding of proprietary unstructured data.
- Your current natural language processing applications suffer from high latency and context loss when handling large document inputs.
- Your product roadmap includes deploying multimodal AI systems that process text, image, and audio inputs within a unified foundation.
It may not be the right priority if:
- Your immediate business requirement relies entirely on basic numerical time-series forecasting or localized anomaly detection where traditional regression models provide sufficient accuracy at a fraction of the compute cost.
Why Transformer Architecture Matters for Enterprise AI
Transformer architecture fundamentally shifts how organizations operationalize unstructured enterprise data by enabling parallelized, large-scale model training and deep contextual understanding across massive datasets. This allows enterprises to move from slow, sequential document processing workflows to high-throughput AI systems capable of analyzing complex information streams in near real time.
According to the McKinsey & Company Global Institute, generative AI technologies, largely powered by transformer-based models, could generate $2.6 trillion to $4.4 trillion in annual economic value, with a significant share coming from improvements in knowledge work, document-intensive industries, and operational automation. A substantial portion of this value is concentrated in sectors such as financial services, where large-scale language models can automate high-volume, high-complexity information processing tasks.
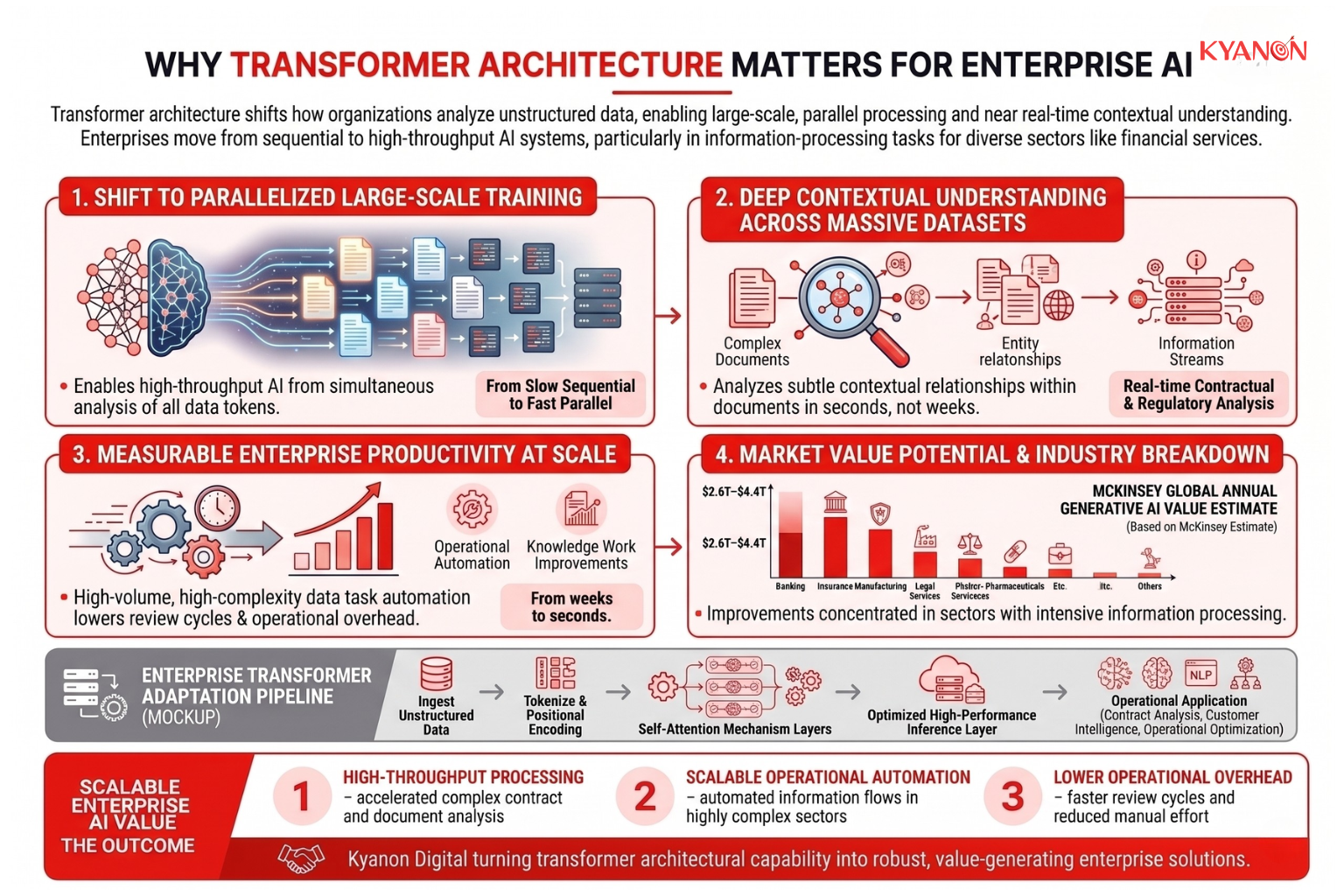
Global financial institutions are increasingly applying transformer-based systems to process thousands of complex legal contracts and regulatory documents simultaneously. These systems extract compliance risks, obligations, and anomalies in seconds rather than weeks, significantly reducing manual review cycles and operational overhead. This demonstrates how transformer architecture translates from a foundational machine learning design into measurable improvements in efficiency, scalability, and enterprise productivity at scale.
Common Misconceptions
Compute costs scale linearly with the amount of input text
Standard self-attention compute and memory operations scale quadratically with sequence length. Managing long-context applications requires specialized optimization techniques like linear attention or FlashAttention to bypass hardware bottlenecks.
Adding more attention heads guarantees better model accuracy
Research demonstrates that many attention heads learn redundant patterns during the training phase. These redundant heads can frequently be pruned during inference deployment without negatively impacting the final output quality, thereby reducing compute costs.
How Kyanon Digital Applies Transformer Architecture
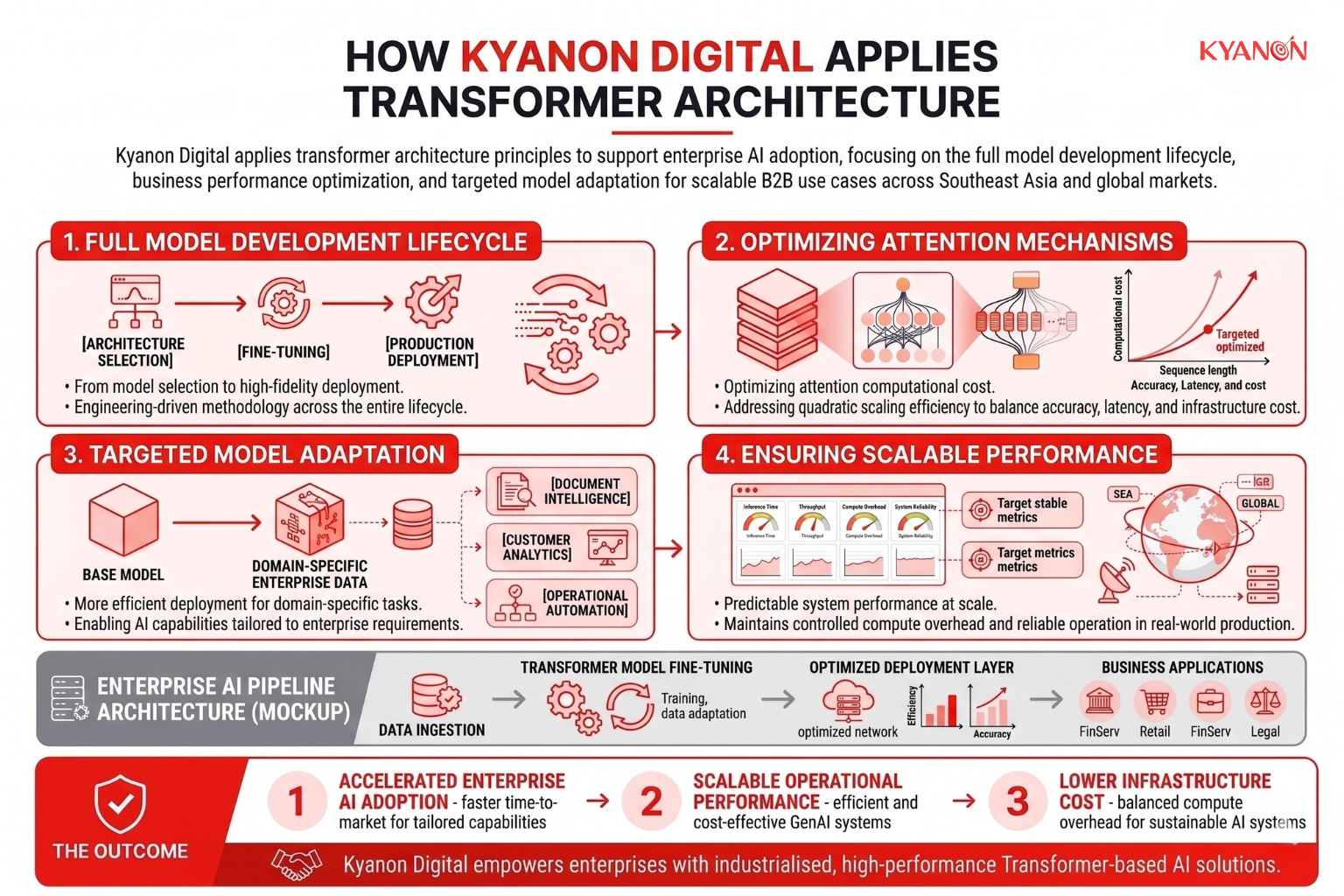
Kyanon Digital applies transformer architecture principles to support enterprise AI adoption across Southeast Asia and global markets, focusing on the full lifecycle of model development, from architecture selection to fine-tuning and production deployment for B2B use cases.
The approach emphasizes aligning transformer-based systems with business performance constraints, particularly in optimizing the computational cost of attention mechanisms, which scale quadratically with sequence length. By addressing these efficiency constraints, enterprise GenAI systems can be designed to balance accuracy, latency, and infrastructure cost, ensuring scalable performance in real-world production environments.
This engineering-driven methodology also prioritizes targeted model adaptation for domain-specific enterprise data, enabling more efficient deployment of transformer-based solutions in areas such as document intelligence, customer analytics, and operational automation. The result is faster time-to-market for AI capabilities while maintaining controlled compute overhead and predictable system performance at scale.
→ Explore our Artificial Intelligence services.







")




 Create project brief with AI
Create project brief with AI