What is GPT (Generative Pre-trained Transformer)?
A Generative Pre-trained Transformer (GPT) is a specific family of large language models developed by OpenAI that utilizes attention mechanisms within a neural network architecture to predict and generate coherent text sequences based on structured prompts. It functions as a sophisticated probabilistic engine that synthesizes information by predicting the next most mathematically likely word.
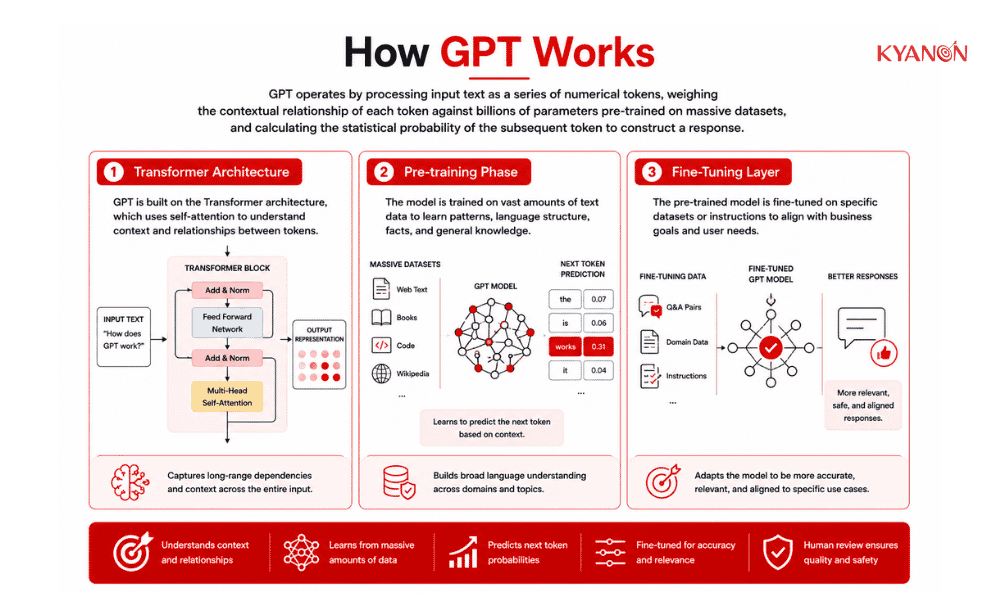
How GPT Works
GPT operates by processing input text as a series of numerical tokens, weighing the contextual relationship of each token against billions of parameters pre-trained on massive datasets, and calculating the statistical probability of the subsequent token to construct a response. This predictive mechanism occurs entirely within the model’s neural network, allowing it to synthesize responses without actively querying a live database.
Transformer Architecture
The foundational neural network design processes sequential data simultaneously rather than chronologically. It uses self-attention mechanisms to evaluate the relevance of distant words within a large context window, maintaining coherence over extended paragraphs.
Pre-training Phase
The initial unsupervised learning stage exposes the model to massive volumes of unstructured text. This phase establishes the model’s baseline syntax, grammar, and factual relationships before any specific operational tasks are introduced.
Fine-Tuning Layer
A subsequent training phase aligns the model’s generalized outputs with desired formatting or behavior. Techniques like Reinforcement Learning from Human Feedback (RLHF) adjust the model to adhere strictly to safety guardrails and instructional prompts.
GPT vs Large Language Model (LLM)
GPT is a specific transformer-based LLM family, while Large Language Model is the broader category of language models trained to process and generate human language.
|
Dimension |
GPT (Generative Pre-trained Transformer) | Large Language Model (LLM) |
| Category | A specific model family associated with the generative pre-trained transformer design |
A broader category of models trained on large-scale language data |
|
Core architecture |
Transformer-based | Often transformer-based, but not limited to one named family |
| Typical outputs | Text, code, summaries, chatbot responses, structured language outputs |
Text, classification, summarization, translation, Q&A, reasoning support |
|
Enterprise use |
Chatbots, code assistance, document intelligence, knowledge assistants | Any language-based AI system, including GPT-based and non-GPT systems |
| Model ownership | Commonly associated with OpenAI’s GPT models |
May come from OpenAI, Anthropic, Google, Meta, Mistral, or private model providers |
|
Governance focus |
Prompt control, retrieval grounding, data privacy, output evaluation | Model selection, deployment model, data governance, evaluation, monitoring |
| Best fit | Prompt-based enterprise assistants and language generation workflows |
Broad AI architecture decisions across language-heavy use cases |
When to Consider GPT (Generative Pre-trained Transformer)
GPT is relevant when an enterprise needs to scale language-heavy work such as knowledge retrieval, document processing, customer support, code assistance, or internal productivity workflows under defined governance controls.
Consider GPT (Generative Pre-trained Transformer) if:
- Your teams need faster drafting, summarization, classification, translation, or rewriting across business documents.
- Your support, sales, or operations teams need a controlled assistant that can answer questions from approved internal knowledge sources.
- Your engineering organization wants to accelerate code explanation, test generation, technical documentation, or backlog analysis while keeping senior review in place.
- Your business needs document intelligence for contracts, policies, reports, tickets, product data, or customer communications.
It may not be the right priority if:
- Your use case requires final answers with no tolerance for uncertainty, but you do not have review, retrieval, or validation controls.
- Your data is fragmented, outdated, duplicated, or not permissioned for AI access.
- Your organization has not assigned ownership for privacy, security, prompt governance, output review, and model monitoring.
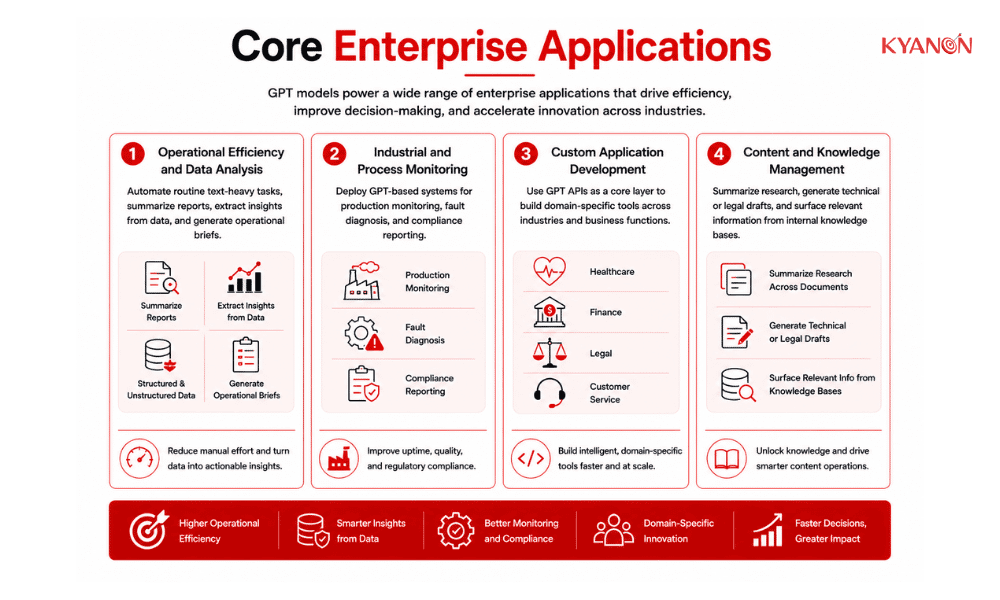
Core Enterprise Applications of GPT (Generative Pre-trained Transformer)
GPT is not a single-use tool. Enterprises are deploying it across multiple functions simultaneously, which is why the architecture and governance decisions made at the start of implementation have compounding downstream effects.
- Operational efficiency and data analysis: GPT models are used to automate routine text-heavy operations, summarizing reports, extracting insights from structured and unstructured data, and generating operational briefs. For teams dealing with high volumes of internal documentation or customer data, this directly reduces the analyst hours spent on synthesis work.
- Industrial and process monitoring: In manufacturing and industrial environments, custom GPT-based systems are being deployed for production monitoring, fault diagnosis, and compliance reporting. The model ingests operational data and generates human-readable summaries, alerts, or audit trails, reducing the time between an anomaly and a human decision.
- Custom application development: Development teams use GPT APIs as a core layer to build domain-specific tools for healthcare, finance, legal, and customer service. Rather than building language capabilities from scratch, engineering organizations integrate GPT into existing product stacks and configure it around their specific data, workflows, and compliance requirements.
- Content and knowledge management: GPT handles high-volume knowledge tasks that are impractical at manual scale: summarizing research across hundreds of documents, generating technical or legal drafts from structured inputs, and surfacing relevant information from large internal knowledge bases. The business case here is not replacing knowledge workers; it is giving them faster, better-organized access to what already exists.
Why GPT (Generative Pre-trained Transformer) Matters for Enterprise Automation
GPT matters for enterprise automation because it turns natural language into a working interface for repetitive, rules-guided, and knowledge-heavy tasks.
Stanford HAI’s 2025 AI Index reported that global private investment in generative AI reached $33.9 billion in 2024, an 18.7% increase from 2023. This investment signal matters because GPT-based systems sit at the center of many enterprise GenAI initiatives, including chatbots, code generation, document intelligence, and knowledge assistants.
Morgan Stanley embedded GPT-4 into internal advisor workflows and reported over 98% adoption of the Morgan Stanley Assistant among advisor teams. The case shows that GPT creates enterprise value only when paired with evaluation, knowledge retrieval, security controls, and workflow adoption.
The following benefits reflect where GPT creates measurable operational value, not theoretical capability, when deployed with proper data access, retrieval grounding, and governance controls in place.
- Scalability: Unlike earlier NLP architectures, transformer-based models process data in parallel rather than sequentially. This means enterprises can apply GPT to large volumes of documents, tickets, queries, or code simultaneously without proportional increases in processing time or human effort.
- Productivity: Automating routine text-based tasks, drafting, summarizing, classifying, translating, and formatting frees skilled employees to focus on judgment-heavy work. The productivity gain compounds when GPT is embedded into daily workflows rather than used as a standalone prompt interface.
- Context awareness across complex inputs: Modern GPT models maintain coherence across long, complex prompts, distinguishing between technical and non-technical uses of the same terminology, tracking multiple threads within a document, or maintaining persona and format consistency across extended outputs. For enterprise use cases involving contracts, technical specifications, or multi-department knowledge bases, this context retention is operationally significant.
Common Misconceptions about GPT (Generative Pre-trained Transformer)
The most important enterprise misconception about GPT is that fluent language output equals business-grade accuracy, reasoning, or security.
“GPT thinks like a human expert.
Reality: GPT does not think, understand, or possess business judgment. It predicts likely language sequences, so expert review remains necessary for strategic, legal, financial, medical, or customer-sensitive outputs.
“GPT is an accurate source of truth.”
Reality: GPT is not a database, encyclopedia, or search engine by default. It can generate hallucinations, fabricated references, and convincing but incorrect answers if outputs are not grounded in approved sources.
“GPT learns instantly from every conversation.”
Reality: Chat interaction is not the same as model training. GPT can use information inside the active context, but enterprise learning requires separate processes such as fine-tuning, retrieval updates, feedback loops, or model evaluation.
“GPT always knows the live internet.”
Reality: A GPT model by itself is not a live knowledge base. Real-time answers require connected retrieval, search, browsing, or enterprise data integrations.
“GPT is neutral because it is AI.”
Reality: GPT can reflect patterns, gaps, and biases from training data, prompts, and retrieved sources. Enterprises should test outputs across customer segments, markets, languages, and policy-sensitive scenarios before deployment.
“GPT conversations are automatically safe for confidential data.”
Reality: Privacy depends on the product, deployment model, settings, and contractual controls. OpenAI states that API data is not used to train or improve OpenAI models unless the customer opts in, and enterprise privacy controls include encryption and security commitments.
How Kyanon Digital Applies GPT (Generative Pre-trained Transformer)
Kyanon Digital applies GPT as part of enterprise GenAI systems that combine model selection, RAG architecture, secure data ingestion, prompt design, API integration, evaluation, and monitoring for clients across Vietnam, Singapore, Malaysia, Thailand, ANZ, the US, and Nordic Europe. The implementation focus is practical: connect GPT-style models to trusted enterprise data, deploy them into controlled environments, and measure outcomes such as time-to-market, conversion support, operational productivity, and TCO.
For retail customer support, Kyanon Digital can build a GPT-powered assistant grounded in approved enterprise content through a custom RAG pipeline. The system connects sources such as product catalogs, FAQs, policies, and service knowledge bases, then deploys in the client’s cloud, domain, or private SaaS environment. This helps reduce repetitive support workload, improve answer consistency, and support faster resolution of routine customer queries before human escalation.
→ Explore our Generative AI consulting and implementation services.







")




 Create project brief with AI
Create project brief with AI