What is Drift (Model Drift)?
Drift (model drift) is the statistical degradation of a machine learning model’s predictive accuracy over time, occurring when the statistical properties of the target variable or input data change from the baseline training environment. Model drift mathematically represents the divergence between the static probability distributions captured during a machine learning algorithm’s training phase and the dynamic data distributions encountered in live production environments.
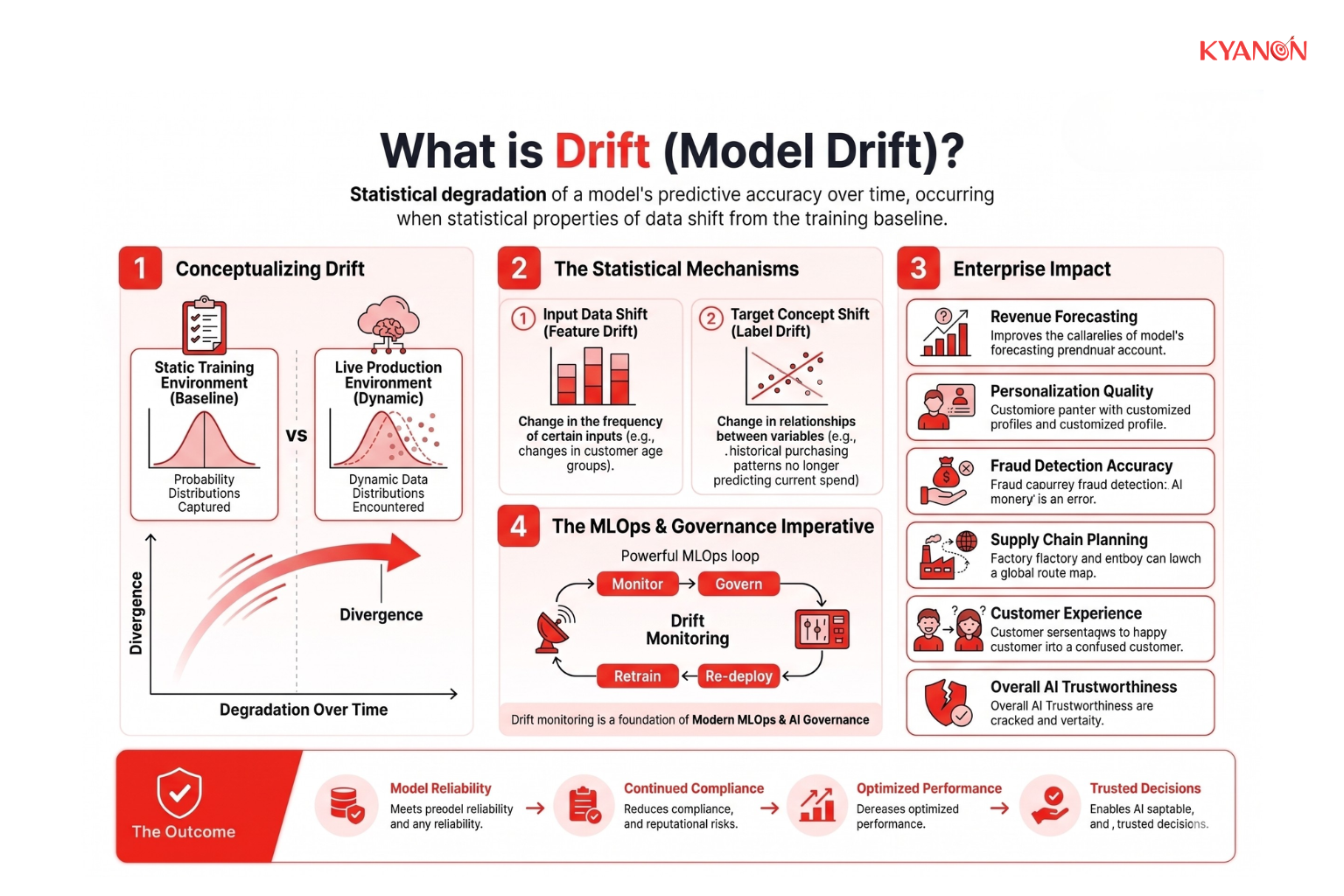
In enterprise environments, model drift is not a theoretical issue, it is an operational reliability challenge. As customer behavior, market conditions, pricing dynamics, and external variables shift, AI systems can begin producing less accurate predictions, weaker recommendations, and unreliable automated decisions.
Without continuous monitoring and governance, model drift can directly impact:
- Revenue forecasting
- Personalization quality
- Fraud detection accuracy
- Supply chain planning
- Customer experience
- Overall AI trustworthiness
For organizations operating production AI systems, drift monitoring is a foundational component of modern MLOps and AI governance.
The Mechanics of Model Drift
The underlying mechanism of model decay is environmental non-stationarity, meaning the real-world conditions generating the inference data continually evolve while the model’s parameters remain fixed. When engineers deploy a model, it relies on the assumption that future unseen data will statistically resemble the historical data used during its optimization phase.
In formal terms, data drift occurs when the marginal probability distribution of the input features, P(X), changes over time without altering the underlying logic. Conversely, concept drift occurs when the conditional probability, P(Y|X), changes, meaning the actual relationship between the input variables and the target output has fundamentally shifted. Without intervention, these statistical deviations cause the model’s loss function to increase, resulting in inaccurate classifications or flawed numerical predictions.
Data Drift vs. Concept Drift
While data drift signifies a shift in the independent input variables, concept drift indicates a fundamental change in the relationship between those variables and the target outcome. Understanding this distinction determines the engineering response required to stabilize the system.
|
Dimension |
Data Drift (Feature Drift) | Concept Drift |
| Core Definition | Changes in the distribution of input data features over time. |
Changes in the actual relationship between inputs and the target variable. |
|
Statistical Shift |
Change in P(X). | Change in P(Y) |
| Primary Cause | Demographic shifts, seasonality, or modifications in data collection methods. |
Shifts in consumer behavior, macroeconomic events, or new competitor actions. |
|
Operational Symptom |
The model processes unfamiliar inputs but the underlying logic remains technically valid. | The model’s underlying logic becomes invalid, leading to high error rates on familiar inputs. |
| Mitigation Strategy | Recalibration of input thresholds, feature scaling, or partial retraining. |
Complete model retraining with recent data or architectural redesign. |
|
E-commerce Example |
Users search for “laptops” 50% more often in December than in July. |
Users browse laptops but stop buying them due to a sudden economic recession. |
When to Prioritize Drift Monitoring
For enterprise organizations, model drift is not a theoretical AI problem, it is an operational and financial risk management issue. Once AI systems move into production, model performance naturally degrades over time as customer behavior, market conditions, competitive dynamics, and operational environments evolve.
Without continuous monitoring, even high-performing models can gradually produce less reliable predictions, creating downstream impacts across revenue, customer experience, compliance, and operational efficiency. A structured drift monitoring capability becomes especially important when AI outputs directly influence high-value business decisions or customer-facing processes.
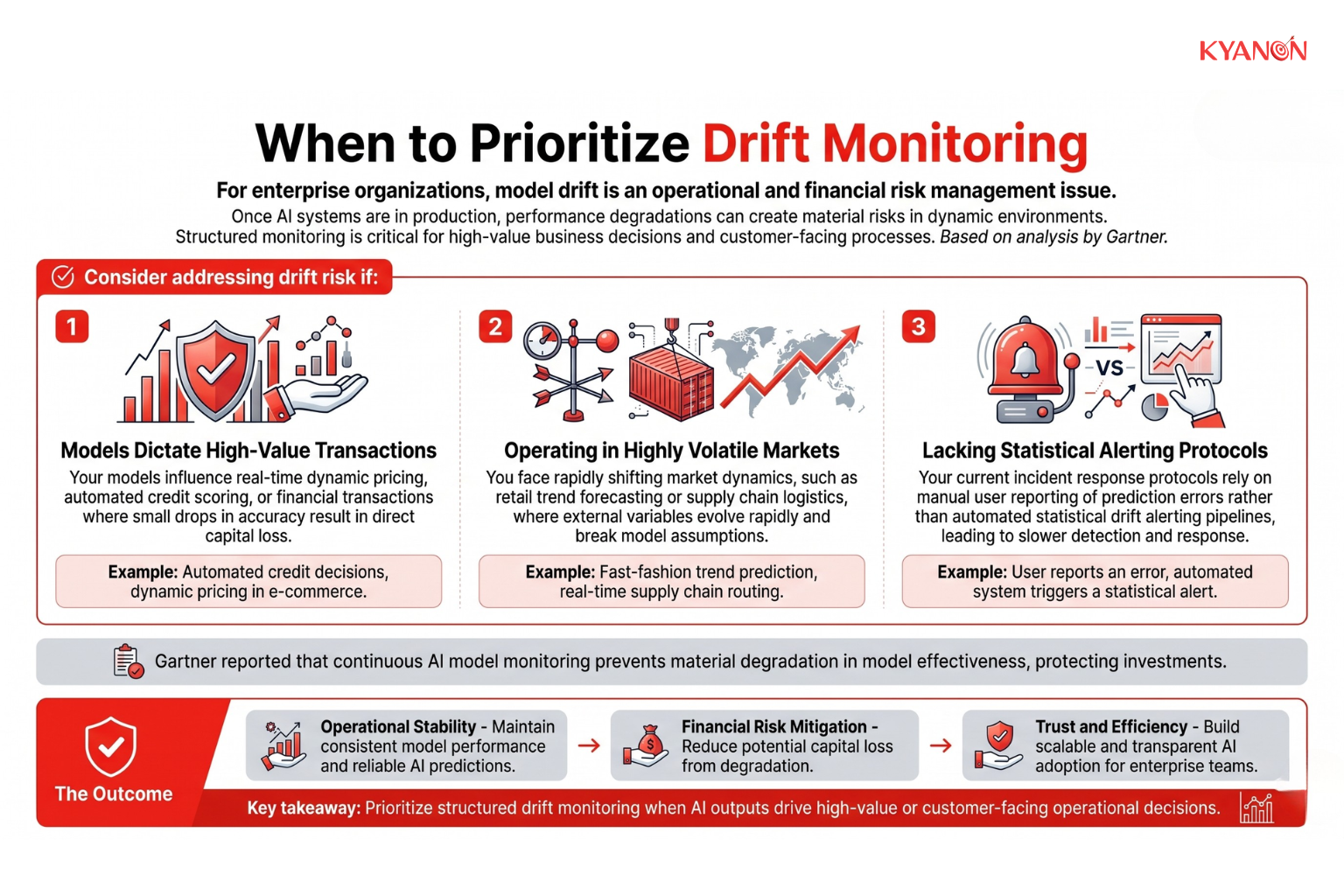
According to Gartner, organizations that lack continuous AI model monitoring frequently experience material degradation in model effectiveness after deployment, particularly in dynamic operating environments where data conditions change rapidly.
Enterprise technology leaders should prioritize drift management infrastructure under the following conditions:
- Your models dictate real-time financial transactions, dynamic pricing, or automated credit scoring where minute accuracy drops translate directly into capital loss.
- You are operating in highly volatile markets, such as retail trend forecasting or supply chain logistics, where external variables shift rapidly.
- Your current incident response protocols rely on end-users reporting prediction errors rather than automated statistical alerting pipelines.
Common Misconceptions
Addressing model degradation requires distinguishing between pipeline failures, temporary seasonal anomalies, and permanent structural shifts in consumer behavior.
Misconception 1: “Retraining immediately on new data is the standard fix for any drift.”
Reality: Simply retraining a model immediately upon detecting a statistical deviation can actively harm the system’s performance.
The Nuance: If the drift stems from a temporary outlier event or seasonal variation, retraining forces the model to overfit to transient noise. Engineering teams must classify the drift as temporary or permanent before initiating compute-heavy retraining cycles.
Misconception 2: “Data quality issues and broken pipelines are forms of model drift.”
Reality: A model failing because a database field suddenly outputs null values or switches formats is experiencing an engineering failure, not statistical drift.
The Nuance: True drift involves organic shifts in real-world behavior or market trends. Broken pipelines necessitate strict input validation and data contracts, whereas actual model drift requires re-evaluating the underlying mathematical assumptions.
Misconception 3: “A well-trained, highly accurate model will maintain its baseline performance indefinitely.”
Reality: Machine learning models begin decaying the exact moment they are deployed into production environments.
The Nuance: Because the physical world and human behavior are constantly evolving, static models cannot adapt independently. Continuous monitoring and lifecycle management are non-negotiable architectural requirements for enterprise AI.
How Kyanon Digital Mitigates Model Drift
Kyanon Digital architects automated model monitoring pipelines that detect statistical divergence in production data before it impacts business logic. We transition enterprise data science teams away from manual, periodic audits and toward systematic, continuous evaluation.
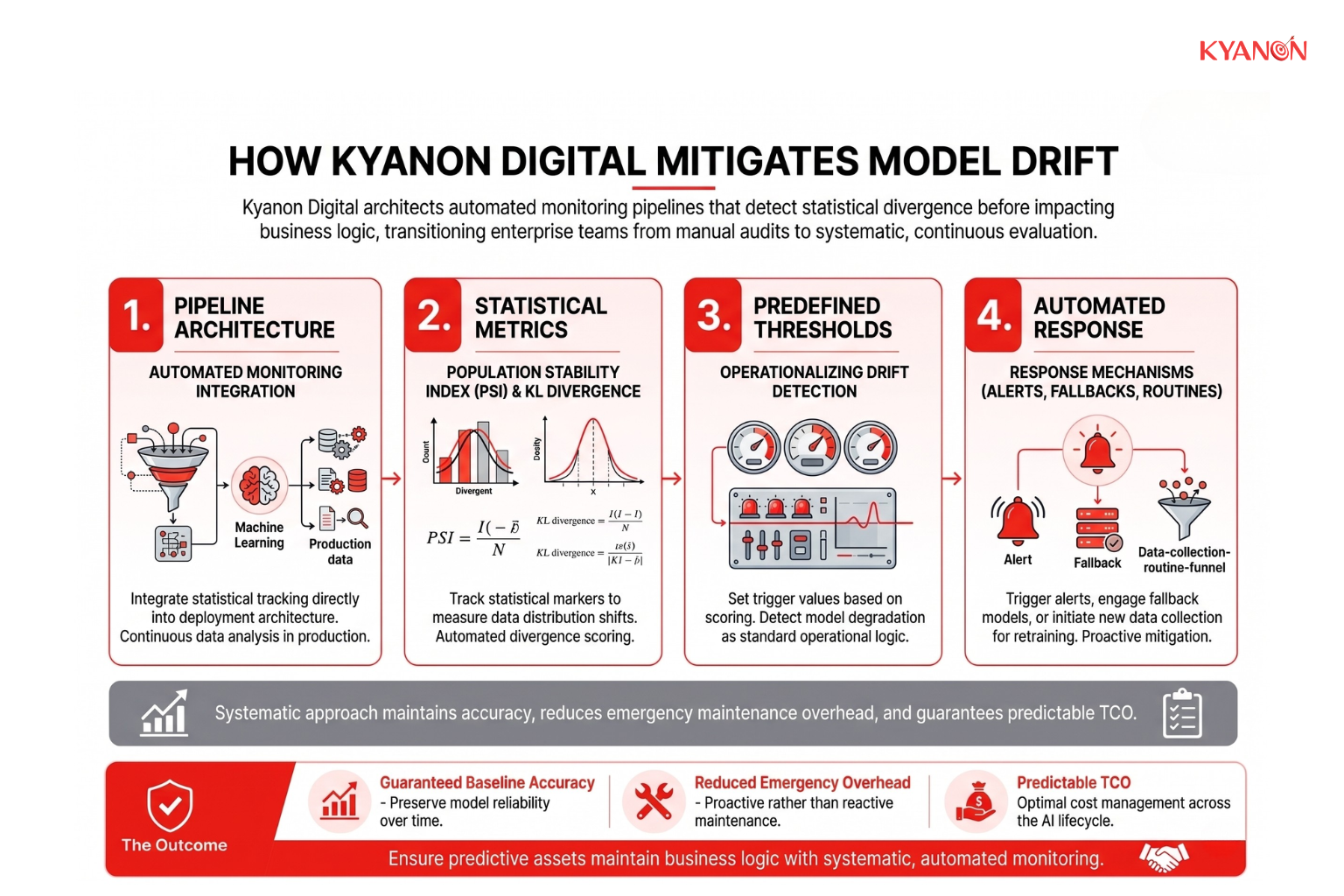
Our engineering teams integrate statistical tracking metrics, such as Population Stability Index (PSI) and Kullback-Leibler (KL) divergence, directly into your existing deployment architecture. Rather than treating model degradation as an unforeseen emergency, we operationalize it by establishing predefined thresholds that automatically trigger alerts, fallback mechanisms, or data collection routines when drift is detected. This systematic approach ensures predictive assets maintain their baseline accuracy, reduces emergency maintenance overhead, and guarantees a predictable total cost of ownership across the AI lifecycle.
→ Explore our Machine Learning Development services.







")




 Create project brief with AI
Create project brief with AI