What is supervised learning?
Supervised learning is a highly accurate machine learning technique that trains AI models using labeled datasets, which provide input data paired with the correct “ground truth” answers. By continuously adjusting its parameters based on these examples, the algorithm learns to identify underlying patterns and relationships. This training process ultimately creates a model capable of accurately predicting outcomes for new, real-world data, enabling organizations to solve complex, large-scale problems such as classifying spam or forecasting stock prices. (IBM)
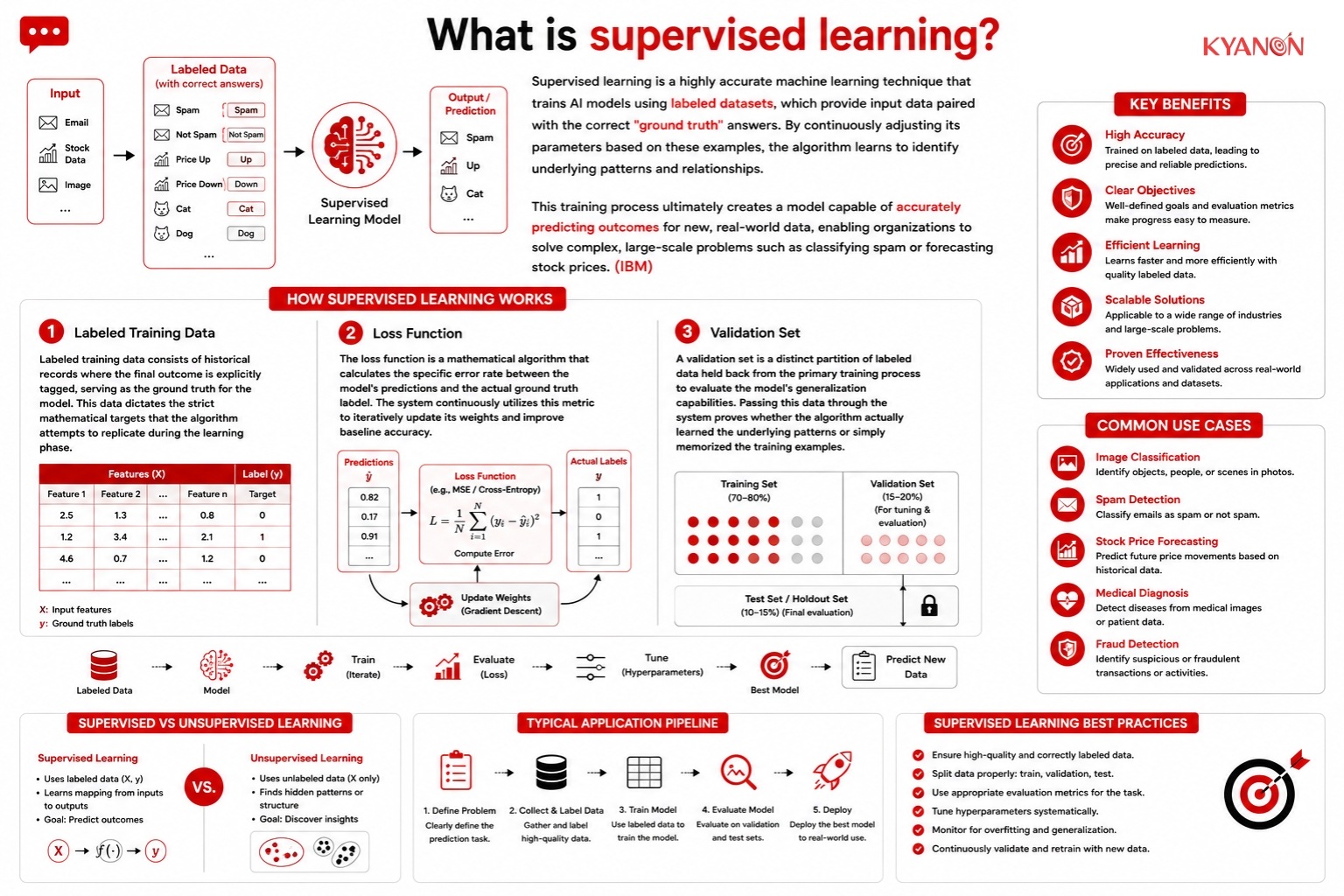
How supervised learning works
The training process involves feeding an algorithm iterative examples where the correct answer is already documented, allowing the mathematical model to adjust its internal parameters until it minimizes output errors.
Labeled Training Data
Labeled training data consists of historical records where the final outcome is explicitly tagged, serving as the ground truth for the model. This data dictates the strict mathematical targets that the algorithm attempts to replicate during the learning phase.
Loss Function
The loss function is a mathematical algorithm that calculates the specific error rate between the model’s predictions and the actual ground truth labels. The system continuously utilizes this metric to iteratively update its weights and improve baseline accuracy.
Validation Set
A validation set is a distinct partition of labeled data held back from the primary training process to evaluate the model’s generalization capabilities. Passing this data through the system proves whether the algorithm actually learned the underlying patterns or simply memorized the training examples.
Real world supervised learning examples
Supervised learning models can be used for a number of different business use cases that hep address a wide range of problems. Common supervised learning examples include the following:
- Risk assessment: Supervised machine learning models can help banks and other financial services companies determine whether customers are likely to default loans, helping to minimize risk in their portfolios.
- Image classification: Supervised machine learning algorithms are often trained to classify objects in images and videos. For example, an algorithm might be used to recognize a person in an image and automatically tag them on a social media platform.
- Fraud detection: Supervised learning underpin many fraud detection systems, enabling enterprises to recognize fraudulent activity. These models are trained on datasets that contain both fraudulent and non-fraudulent activity so they can be used to flag suspicious activity in real time.
- Recommendation systems: Supervised learning algorithms are used by online platforms and streaming services to power recommendations based on previous customer behavior or shopping history. The models extract important information about a user’s behavior and suggest similar products and content.
Supervised Learning vs Unsupervised Learning
Both paradigms extract analytical patterns from datasets, but they differ entirely in their reliance on pre-defined human labels and their end goals.
|
Dimension |
Supervised Learning | Unsupervised Learning |
| Data Requirement | Requires explicitly labeled data |
Uses raw, unlabeled data |
|
Core Objective |
Predicts specific known outcomes | Discovers hidden structures or clusters |
| Human Engineering Effort | High (requires manual data labeling) |
Low (no labeling required) |
|
Common Algorithms |
Regression, Classification | K-Means Clustering, Principal Component Analysis |
| Primary Enterprise Use Case | Fraud detection, demand forecasting |
Customer segmentation, anomaly detection |
When to consider supervised learning
Consider supervised learning if:
- Your engineering division possesses thousands of historical transaction records explicitly tagged as either legitimate or fraudulent by human auditors.
- Your e-commerce operations require forecasting exact inventory volume demands for the next fiscal quarter based on labeled seasonal sales data.
- You aim to deploy a proactive churn prediction model using a dataset where past customer cancellations and their preceding behaviors are documented.
It may not be the right priority if:
- Your organization maintains massive data lakes but lacks the dedicated engineering resources or operational budget to manually clean and label that data with explicit target variables.
Why supervised learning matters for enterprise operations
Supervised learning is the foundational engine of modern enterprise automation because it converts historical corporate records into software that automatically makes high-stakes operational decisions at scale.While generative AI handles creative or conversational tasks, supervised learning runs the invisible back-office machinery of global industry. It allows enterprises to eliminate manual data-entry bottlenecks, drastically reduce human processing errors, and accurately forecast physical resource needs.
Common misconceptions
We achieved 99% accuracy on our training data, so the model is ready for production deployment
Reality: High training accuracy is frequently a severe red flag for data overfitting. It indicates the algorithm has simply memorized the training set, including its random noise and outliers, causing it to fail dramatically when analyzing new, unseen production data.
Training the actual algorithm is the most difficult and time-consuming part of the project
Reality: Building the machine learning algorithm typically consumes less than 10% of the total project timeline. The vast majority of engineering effort is allocated to data collection, feature engineering, and the incredibly tedious process of manual data labeling.
Once the model is deployed and accurate, the engineering work is finished
Reality: Models degrade consistently over time due to data drift. As real-world environments evolve, such as shifting consumer purchasing habits or new macroeconomic trends, the initial training data becomes obsolete, requiring continuous monitoring and retraining to maintain baseline accuracy.
How Kyanon Digital applies supervised learning
Kyanon Digital implements supervised learning as the foundational layer for predictive AI solutions, including fraud detection, churn prediction, and demand forecasting for enterprise clients across the US, ANZ, and Southeast Asia. Our data engineering teams execute rigorous data labeling, feature engineering, and cross-validation pipelines to prevent model overfitting. This approach ensures algorithms maintain high predictive accuracy in production environments, driving faster time-to-market and optimizing the Total Cost of Ownership (TCO) for enterprise analytics infrastructure.
Explore our Machine Learning services.







")




 Create project brief with AI
Create project brief with AI