Mô hình phân loại là gì?
Mô hình phân loại là một thuật toán học máy được thiết kế để phân tích dữ liệu đầu vào và tự động gán dữ liệu đó vào một hoặc nhiều danh mục được xác định trước dựa trên các mẫu được học từ dữ liệu huấn luyện trong quá khứ. Hoạt động trong lĩnh vực học có giám sát, các mô hình phân loại chuyển đổi thông tin kinh doanh thô thành các kết quả phân loại có cấu trúc như gian lận/không gian lận, được chấp thuận/bị từ chối hoặc rủi ro cao/rủi ro thấp.
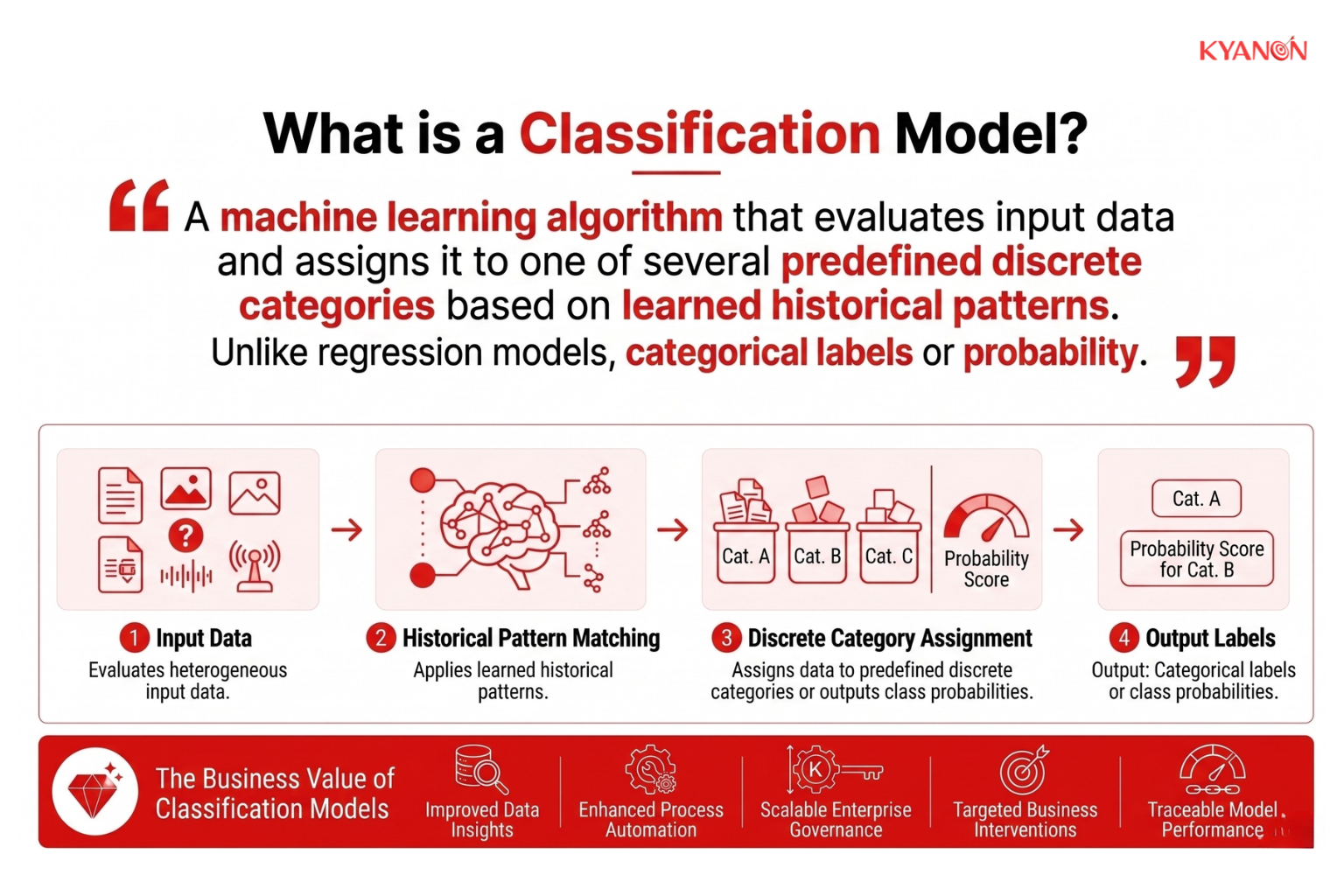
Khác với các mô hình hồi quy dự đoán các giá trị số liên tục, hệ thống phân loại tập trung vào việc ra quyết định rời rạc. Mục đích chính của chúng là tự động hóa việc phân loại, ưu tiên, định tuyến và đánh giá hoạt động trong toàn bộ quy trình làm việc của doanh nghiệp.
Các mô hình phân loại là nền tảng của tự động hóa dựa trên trí tuệ nhân tạo hiện đại vì chúng cho phép các tổ chức xử lý khối lượng lớn dữ liệu có cấu trúc và không có cấu trúc mà không cần hoàn toàn dựa vào quy trình xem xét thủ công.
Các ứng dụng doanh nghiệp phổ biến bao gồm:
- Phát hiện gian lận
- Chấm điểm tín dụng
- Phân tích tâm lý khách hàng
- Hỗ trợ chẩn đoán y tế
- Phân loại tài liệu
- Lọc thư rác
- Định tuyến phiếu hỗ trợ
- Phát hiện mối đe dọa an ninh mạng
Khi việc ứng dụng AI trong doanh nghiệp ngày càng mở rộng, các mô hình phân loại ngày càng đóng vai trò như các công cụ hỗ trợ ra quyết định vận hành, được tích hợp trực tiếp vào các hệ thống ERP, nền tảng CRM, cơ sở hạ tầng chuỗi cung ứng và quy trình tự động hóa thông minh.
Cách thức hoạt động của mô hình phân loại
Mô hình phân loại hoạt động bằng cách phân tích tập dữ liệu huấn luyện đã được gán nhãn để xác định các mối tương quan toán học giữa các biến đầu vào và các danh mục mục tiêu. Sau khi được triển khai, mô hình áp dụng các trọng số đã học này cho dữ liệu chưa được nhìn thấy để tính toán xác suất thuộc về lớp, trả về danh mục có độ tin cậy thống kê cao nhất.
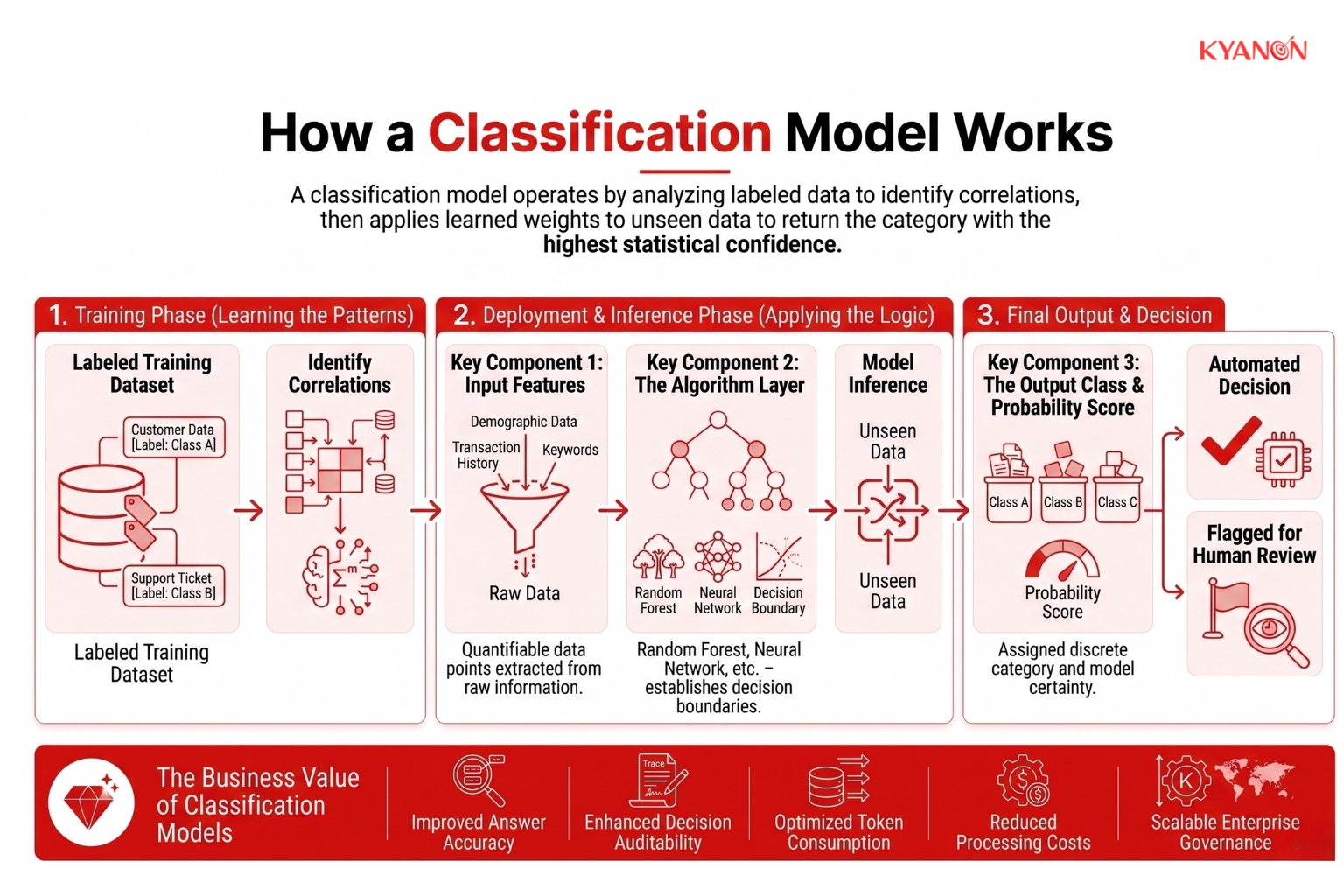
Trong môi trường sản xuất doanh nghiệp, mô hình phân loại hoạt động như một quy trình đa tầng chuyển đổi các tài sản dữ liệu doanh nghiệp có cấu trúc hoặc phi cấu trúc thành các phán đoán vận hành tự động thông qua ba giai đoạn vận hành riêng biệt:
Thành phần chính 1: Tính năng đầu vào
Trước khi quá trình dự đoán diễn ra, dữ liệu thô của doanh nghiệp phải được chuyển đổi thành các dạng biểu diễn số mà máy tính có thể đọc được, được gọi là các đặc trưng.
Quá trình này được gọi là kỹ thuật tạo đặc trưng.
Dữ liệu đầu vào có thể bao gồm:
- Lịch sử giao dịch của khách hàng
- Vé hỗ trợ
- Hồ sơ y tế
- Báo cáo tài chính
- Danh mục sản phẩm
- Nhật ký hoạt động CRM
- dữ liệu cảm biến IoT
Tùy thuộc vào trường hợp sử dụng, quy trình tiền xử lý có thể bao gồm:
- Chuẩn hóa dữ liệu
- Xử lý giá trị thiếu
- Vector hóa
- Thế hệ nhúng
- Mã hóa token
- Giảm chiều
Đối với các hệ thống xử lý ngôn ngữ tự nhiên (NLP), văn bản được chuyển đổi thành các vectơ số bằng các phương pháp như:
- TF-IDF
- Nhúng từ
- Các phép nhúng Transformer
- Ví dụ:
- Trí tuệ nhân tạo hỗ trợ doanh nghiệp có thể phân tích:
- Cảm xúc
- Khẩn cấp
- Danh mục sản phẩm
- Loại khiếu nại
- Khả năng leo thang
Các đặc điểm được trích xuất này trở thành nền tảng toán học cho phân loại dự đoán.
Trong môi trường doanh nghiệp hiện đại, các quy trình thu thập tính năng ngày càng được tích hợp với:
- Hồ dữ liệu
- Kiến trúc truyền phát
- Cơ sở dữ liệu vectơ
- Cửa hàng đặc trưng
- Hệ thống hướng sự kiện
Điều này cho phép các hệ thống phân loại dự đoán hoạt động liên tục trong thời gian thực.
Thành phần chính 2: Lớp thuật toán
Đây là bộ máy toán học, chẳng hạn như rừng ngẫu nhiên, cây quyết định hoặc mạng nơ-ron—thiết lập ranh giới quyết định giữa các loại khác nhau trong giai đoạn huấn luyện. Nó định nghĩa logic toán học cần thiết để phân tách và phân biệt các lớp với nhau.
Lớp thuật toán là cốt lõi toán học giúp phân tách các danh mục bằng cách xác định các mối quan hệ thống kê giữa các đặc điểm và nhãn mục tiêu.
Các thuật toán phân loại khác nhau được tối ưu hóa cho các khối lượng công việc, cấu trúc dữ liệu và các ràng buộc hoạt động khác nhau của doanh nghiệp.
Hồi quy Logistic
Mặc dù tên gọi là vậy, Hồi quy Logistic chủ yếu là một thuật toán phân loại được sử dụng cho các nhiệm vụ dự đoán nhị phân.
Nó ước tính xác suất một đầu vào thuộc về một danh mục mục tiêu bằng cách sử dụng hàm logistic.
Các ứng dụng doanh nghiệp phổ biến:
- Chấm điểm tín dụng
- Dự đoán tỷ lệ khách hàng rời bỏ
- Đánh giá rủi ro
- Điểm số dẫn đầu
Thuận lợi:
- Triển khai nhanh chóng
- Khả năng diễn giải cao
- Yêu cầu cơ sở hạ tầng nhẹ
- Hiệu suất cơ bản đáng tin cậy
Cây quyết định
Cây quyết định phân loại dữ liệu bằng cách chia nhỏ các đầu vào một cách đệ quy dựa trên các điều kiện đặc trưng.
Thuận lợi:
- Logic dễ hiểu đối với con người
- Dễ giải thích
- Khả năng giải thích cao cho các bên liên quan trong kinh doanh
Hạn chế:
- Dễ bị quá khớp
- Độ ổn định dự đoán thấp hơn so với các mô hình kết hợp
Các trường hợp sử dụng phổ biến:
- Hỗ trợ ra quyết định vận hành
- Phân khúc khách hàng
- Tự động hóa quy trình làm việc nội bộ
Rừng ngẫu nhiên
Random Forest là một thuật toán phân loại kết hợp nhiều cây quyết định thành một công cụ dự đoán tập thể.
Thay vì chỉ dựa vào một đường dẫn quyết định duy nhất, mô hình tổng hợp các dự đoán từ nhiều cây để cải thiện tính ổn định và giảm thiểu hiện tượng quá khớp.
Các ứng dụng doanh nghiệp phổ biến:
- Phát hiện gian lận
- Thẩm định bảo hiểm
- Phân tích rủi ro hoạt động
- Bảo trì dự đoán
Thuận lợi:
- Độ tin cậy dự đoán cao
- Độ bền cao
- Hiệu quả trên các tập dữ liệu doanh nghiệp nhiễu.
- Hiệu suất tổng quát tốt hơn
Naive Bayes
Naive Bayes là một thuật toán phân loại xác suất dựa trên định lý Bayes.
Nó được sử dụng rộng rãi trong:
- Lọc thư rác
- Phân tích cảm xúc
- Phân loại NLP
- Phân loại tài liệu
Thuận lợi:
- Tốc độ suy luận nhanh
- Chi phí tính toán thấp
- Hiệu suất tốt trên các tập dữ liệu nhỏ hơn
XGBoost
XGBoost (Extreme Gradient Boosting) là một trong những khung phân loại máy học được sử dụng rộng rãi nhất trong doanh nghiệp nhờ hiệu suất dự đoán cao và hiệu quả tối ưu hóa vượt trội.
Nó vượt trội ở những điểm sau:
- Phát hiện gian lận
- Chấm điểm tài chính
- Phát hiện bất thường trong chuỗi cung ứng
- Mô hình rủi ro doanh nghiệp
Thuận lợi:
- Độ chính xác dự đoán vượt trội
- Tốc độ thực thi nhanh
- Khả năng xử lý mạnh mẽ các tương tác tính năng phức tạp.
- Khả năng mở rộng trên các tập dữ liệu lớn
XGBoost được sử dụng rộng rãi trong các hệ thống doanh nghiệp sản xuất, nơi cả tốc độ và độ chính xác đều ảnh hưởng trực tiếp đến kết quả hoạt động.
Mạng nơ-ron nhân tạo (ANN)
Mạng nơ-ron nhân tạo là các kiến trúc học sâu có khả năng xác định các mẫu phi tuyến tính phức tạp trong dữ liệu doanh nghiệp.
Mạng nơ-ron nhân tạo (ANN) thường được sử dụng trong:
- Phân loại hình ảnh
- Nhận dạng giọng nói
- Hệ thống NLP
- Công cụ đề xuất
- Chẩn đoán hình ảnh y tế
Các hệ thống trí tuệ nhân tạo dựa trên transformer hiện đại là những dạng kiến trúc mạng thần kinh tiên tiến.
Các hệ thống này ngày càng được tích hợp vào:
- phi công phụ AI
- Xử lý tài liệu thông minh
- Trí tuệ nhân tạo đàm thoại
- Nền tảng tìm kiếm doanh nghiệp
Thành phần chính 3: Lớp đầu ra và điểm xác suất
Sau khi được huấn luyện, mô hình phân loại sẽ đánh giá dữ liệu chưa được thấy và tạo ra điểm xác suất cho các danh mục có thể có.
Thay vì đưa ra kết luận chắc chắn tuyệt đối, mô hình này ước tính mức độ tin cậy.
Ví dụ:
- Giao dịch gian lận → 94%
- Giao dịch hợp pháp → 6%
Trong các hệ thống doanh nghiệp, dự đoán thường được chi phối bởi ngưỡng độ tin cậy.
Ví dụ về logic ngưỡng:
- Độ tin cậy trên 95% → Thực thi hoàn toàn tự động
- Nếu độ tin cậy từ 70–95% → Cần xem xét lại bởi con người.
- Độ tin cậy dưới 70% → Điều tra thủ công
Kiến trúc phân ngưỡng này rất quan trọng vì không phải tất cả các quyết định phân loại đều mang cùng một mức độ rủi ro vận hành.
Hệ thống chấm điểm độ tin cậy giúp các tổ chức:
- Giảm thiểu kết quả dương tính giả
- Cải thiện quản trị
- Ngăn ngừa lỗi tự động hóa
- Cho phép sự tham gia của con người trong quá trình giám sát.
- Cải thiện khả năng giải thích
Các quy trình phân loại dự đoán hiện đại ngày càng kết hợp nhiều yếu tố sau:
- Mô hình phân loại
- Quy tắc kinh doanh
- Hệ thống xác thực
- Rào chắn AI
- các lớp điều phối quy trình làm việc
- Cơ sở hạ tầng giám sát
Mục tiêu của doanh nghiệp không chỉ đơn thuần là độ chính xác trong dự đoán, mà còn là khả năng đưa ra quyết định vận hành đáng tin cậy trên quy mô lớn.
Các nguyên mẫu cốt lõi: Phân loại nhị phân, đa lớp và đa nhãn
Để phù hợp với các nhiệm vụ vận hành cụ thể với cấu hình tính toán chính xác, phân loại học máy được chia thành các biến thể chức năng riêng biệt:
- Phân loại nhị phân: Định dạng đơn giản nhất, được thiết kế để phân loại dữ liệu thành chính xác hai danh mục loại trừ lẫn nhau (ví dụ: Có/Không, Thư rác/Thư hợp lệ, Gian lận/Không gian lận).
- Phân loại đa lớp: Được cấu hình để phân loại dữ liệu vào một nhóm mục tiêu cụ thể trong số ba hoặc nhiều khả năng khác nhau (ví dụ: phân loại hình ảnh chó, mèo hoặc chim; hoặc chuyển yêu cầu hỗ trợ vào bộ phận Phần cứng, Phần mềm hoặc Thanh toán). Điểm dữ liệu chỉ có thể thuộc về một lớp cuối cùng duy nhất.
- Phân loại đa nhãn: Một biến thể nâng cao, trong đó một điểm dữ liệu đầu vào duy nhất có thể được gán đồng thời nhiều thẻ phân loại độc lập, chồng chéo (ví dụ: mô hình gắn thẻ tài liệu tự động gắn nhãn cho một tệp được tải lên là cả Báo cáo tài chính quý 4 và Hành động tuân thủ khẩn cấp).
Mô hình phân loại so với mô hình hồi quy
Cả hai phương pháp đều sử dụng máy học có giám sát để dự đoán kết quả kinh doanh, nhưng chúng khác nhau về cơ bản ở loại kết quả đầu ra mà chúng tạo ra.
|
Kích thước |
Mô hình phân loại | Mô hình hồi quy |
| Định dạng đầu ra | Các danh mục riêng biệt |
Giá trị số liên tục |
|
Mục tiêu chính |
Phân loại dữ liệu vào các lớp được xác định trước. | Dự báo số lượng hoặc xu hướng |
| Các chỉ số đánh giá | Độ chính xác, Độ thu hồi, Điểm F1 |
Sai số bình phương trung bình (MSE), RMSE |
|
Cơ chế quyết định |
Tạo ra ranh giới giữa các lớp học | Điều chỉnh đường thẳng toán học cho phù hợp với dữ liệu. |
| Ứng dụng kinh doanh | Phát hiện gian lận, định tuyến vé |
Dự báo doanh thu, dự đoán giá cả |
Hiểu rõ sự khác biệt này là rất quan trọng khi thiết kế hệ thống AI doanh nghiệp vì việc lựa chọn sai nhóm mô hình sẽ dẫn đến những kết quả vận hành hoàn toàn khác biệt.
Khi nào nên xem xét mô hình phân loại?
Hãy xem xét mô hình phân loại nếu:
- Đội ngũ vận hành của bạn sẽ xem xét và phân bổ thủ công hàng nghìn yêu cầu hỗ trợ khách hàng mỗi ngày vào các hàng đợi của các bộ phận khác nhau dựa trên chủ đề hoặc mức độ khẩn cấp.
- Nền tảng tài chính của bạn yêu cầu đánh giá tức thời mức độ rủi ro giao dịch để phê duyệt các giao dịch mua hoặc gắn cờ chúng để xem xét gian lận.
- Danh mục sản phẩm thương mại điện tử của bạn dựa vào việc nhập liệu thủ công để gắn thẻ sản phẩm, gây ra tắc nghẽn trong quá trình xử lý khi thêm hàng nghìn SKU mới từ nhà cung cấp.
Có thể đó không phải là ưu tiên đúng đắn nếu:
- Mục tiêu chính của bạn là dự đoán giá trị số chính xác của nhu cầu tồn kho trong quý tiếp theo hoặc dự báo các biến động giá cụ thể, điều này đòi hỏi một kiến trúc hồi quy.
Các chỉ số sản xuất: Vượt xa độ chính xác cơ bản gây hiểu nhầm
Hiệu quả của mô hình phân loại được đo lường bằng các chỉ số như độ chính xác, độ chuẩn xác, độ nhạy và điểm F1. Một cạm bẫy nghiêm trọng đối với các nhà lãnh đạo kỹ thuật là chỉ dựa vào chỉ số “Độ chính xác” cơ bản để đánh giá mức độ sẵn sàng của mô hình. Ví dụ, nếu tập dữ liệu của doanh nghiệp mất cân bằng nghiêm trọng, chẳng hạn như cơ sở dữ liệu phát hiện gian lận chứa 99% giao dịch hợp pháp và chỉ 1% giao dịch gian lận, thì một mô hình bị lỗi có thể đơn giản đoán “Hợp pháp” mỗi lần và đạt độ chính xác 99%. Các hệ thống phải được kiểm toán bằng cách sử dụng các chỉ số riêng biệt, có độ tin cậy cao:
Độ chính xác so với độ thu hồi trong các hoạt động có rủi ro cao
Độ chính xác thể hiện mức độ đúng đắn của mô hình bằng cách tính toán số lượng trường hợp được gắn nhãn là một lớp cụ thể thực sự chính xác. Chỉ số này rất cần thiết cho các hoạt động có rủi ro cao, nơi các kết quả dương tính giả có thể gây ra thiệt hại đáng kể, chẳng hạn như việc vô tình chặn giao dịch thẻ doanh nghiệp hợp lệ của khách hàng VIP.
Độ chính xác (Recall) đóng vai trò là thước đo đánh giá tính đầy đủ của mô hình bằng cách xác định tỷ lệ các trường hợp tích cực thực tế trong tập dữ liệu được xác định thành công. Duy trì độ chính xác cao là điều cần thiết trong môi trường có rủi ro cao, nơi việc không phát hiện được một nhóm mục tiêu, chẳng hạn như một vụ rửa tiền hợp pháp, sẽ dẫn đến những lỗ hổng bảo mật hoặc tuân thủ nghiêm trọng.
Điểm F1: Cân bằng các quyết định tự động
Điểm F1 là trung bình điều hòa của độ chính xác và độ thu hồi, kết hợp cả hai chỉ số thành một chỉ báo hiệu suất duy nhất, đáng tin cậy. Nó cung cấp một cái nhìn thực tế, không bị thổi phồng về hiệu quả hoạt động của một công cụ phân loại doanh nghiệp trên các tập dữ liệu hoạt động thực tế có độ lệch cao.
Triển khai chiến lược: Các trường hợp sử dụng trong doanh nghiệp và những rủi ro vận hành
Môi trường tự động hóa có ROI cao và các trường hợp sử dụng phổ biến
Việc triển khai phân loại dự đoán giúp chuyển đổi lực lượng lao động của bạn khỏi các công việc phân loại tẻ nhạt và chuyển đổi hoạt động thông qua tự động hóa tốc độ cao. Các trường hợp sử dụng phổ biến trong doanh nghiệp bao gồm:
- Phát hiện thư rác: Lọc email đến thành thư rác hoặc không phải thư rác bằng các thuật toán như Naïve Bayes.
- Mô hình dự đoán tỷ lệ khách hàng rời bỏ: Dự đoán liệu khách hàng có rời bỏ dịch vụ hoặc hủy đăng ký dựa trên mô hình sử dụng hay không.
- Chẩn đoán y khoa: Phân loại bệnh nhân vào các nhóm nguy cơ cụ thể dựa trên dữ liệu chẩn đoán và nhân khẩu học trong quá khứ.
- Phân loại hình ảnh: Xác định các đối tượng trong hình ảnh, chẳng hạn như sử dụng mô hình YOLO (You Only Look Once) để kiểm soát chất lượng tự động trên dây chuyền sản xuất.
- Hệ thống chấm điểm tín dụng tự động: Nhanh chóng phân loại đơn xin vay vào các nhóm rủi ro riêng biệt dựa trên lịch sử tài chính được đối chiếu, giúp đẩy nhanh thời gian phê duyệt.
- Định tuyến yêu cầu tự động: Phân loại ngay lập tức các yêu cầu dịch vụ doanh nghiệp đến vào các hàng đợi kỹ thuật hoặc quản lý tài khoản cụ thể dựa trên phân tích văn bản thông qua xử lý ngôn ngữ tự nhiên (NLP).
Hạn chế trong sản xuất: Sự thay đổi dữ liệu và sự mất cân bằng lớp.
Sau khi triển khai mô hình, các nhóm doanh nghiệp cần chủ động lập kế hoạch cho hai vấn đề cốt lõi trong vòng đời hệ thống:
- Sự thay đổi của mô hình và dữ liệu: Các mối tương quan toán học được học trong giai đoạn huấn luyện chắc chắn sẽ suy giảm khi thói quen tiêu dùng thay đổi, các yếu tố kinh tế vĩ mô mới xuất hiện hoặc định dạng phần mềm của doanh nghiệp được cập nhật. Các vòng lặp huấn luyện lại tự động thường xuyên là rất cần thiết để giữ cho các ranh giới quyết định chính xác theo thời gian.
- Khắc phục sự mất cân bằng lớp: Khi huấn luyện các mô hình cho các bất thường có giá trị cao như xâm nhập an ninh mạng hoặc các bệnh lý hiếm gặp, các kỹ sư phải sử dụng các kỹ thuật cân bằng dữ liệu, chẳng hạn như SMOTE (Kỹ thuật lấy mẫu quá mức thiểu số tổng hợp) hoặc các chỉ số tổn thất có trọng số theo lớp, để ngăn mô hình bỏ qua lớp thiểu số.
Tại sao mô hình phân loại lại quan trọng đối với hoạt động doanh nghiệp?
Khi các doanh nghiệp mở rộng quy mô số, các điểm nghẽn trong hoạt động ngày càng xuất hiện từ một vấn đề lặp đi lặp lại: con người vẫn đang thực hiện việc phân loại, xem xét, ưu tiên và định tuyến thủ công khối lượng dữ liệu khổng lồ đến từ bên ngoài. Phiếu yêu cầu của khách hàng, hóa đơn, giao dịch, yêu cầu gia nhập, tài liệu tuân thủ, danh mục nhà cung cấp và email hỗ trợ thường phụ thuộc vào quá trình phân loại lặp đi lặp lại của con người trước khi các quy trình tiếp theo có thể bắt đầu.
Mô hình phân loại giải quyết sự thiếu hiệu quả trong hoạt động này bằng cách chuyển đổi quá trình phân loại thủ công chậm chạp thành quá trình ra quyết định tự động, theo thời gian thực.
Thay vì yêu cầu nhân viên kiểm tra từng bản ghi đầu vào một cách riêng lẻ, các hệ thống phân loại dựa trên học máy sẽ phân tích các mẫu trong dữ liệu kinh doanh lịch sử và tự động gán các dữ liệu đầu vào mới vào các danh mục hoạt động được xác định trước. Điều này cho phép các doanh nghiệp xử lý quy trình công việc khối lượng lớn với tốc độ, tính nhất quán và khả năng mở rộng cao hơn đáng kể.
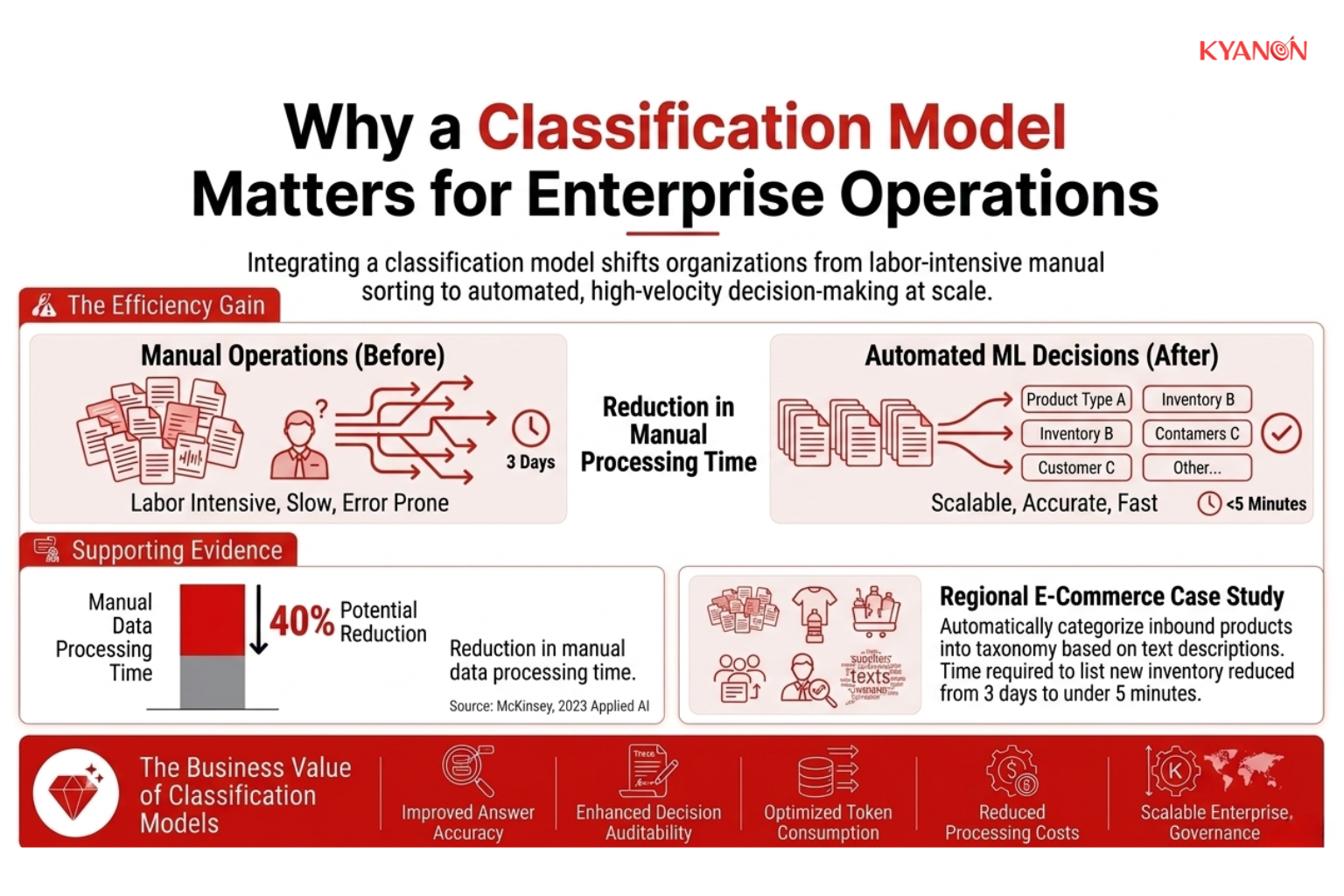
Nghiên cứu từ các nhà phân tích AI doanh nghiệp cho thấy rằng các tổ chức triển khai các mô hình phân loại học máy trong quy trình làm việc vận hành có thể giảm đáng kể chi phí xử lý thủ công đồng thời cải thiện hiệu quả năng suất.
Theo báo cáo năm 2024 của McKinsey về trí tuệ nhân tạo ứng dụng, các doanh nghiệp triển khai hệ thống phân loại và tự động hóa thông minh dựa trên AI đã ghi nhận sự giảm đáng kể thời gian xử lý hành chính lặp đi lặp lại, đặc biệt là trong các quy trình làm việc của bộ phận chăm sóc khách hàng, tài chính và chuỗi cung ứng.
Một nhà bán lẻ thương mại điện tử lớn trong khu vực đã triển khai mô hình phân loại dự đoán để tự động phân loại các sản phẩm đầu vào từ nhà cung cấp thành các cây phân loại sản phẩm có cấu trúc dựa trên:
- Mô tả sản phẩm
- Siêu dữ liệu
- Thuộc tính nhà cung cấp
- Sơ đồ phân loại lịch sử
Trước khi triển khai, quy trình tiếp nhận sản phẩm yêu cầu nhiều nhóm phải xem xét và phân loại thủ công các SKU đến, gây ra sự chậm trễ làm giảm khả năng cung ứng hàng tồn kho và tăng khối lượng công việc vận hành.
Sau khi triển khai hệ thống phân loại:
- Việc phân loại sản phẩm phần lớn đã được tự động hóa.
- Các yêu cầu xem xét thủ công đã giảm đáng kể.
- Thời gian tiếp nhận hàng tồn kho mới giảm từ ba ngày xuống còn dưới năm phút.
- Các điểm nghẽn trong hoạt động nội bộ đã được giảm thiểu đáng kể.
Điều này cho thấy các mô hình phân loại đã phát triển như thế nào từ những công cụ học máy đơn giản thành cơ sở hạ tầng vận hành cốt lõi, hỗ trợ tự động hóa doanh nghiệp có khả năng mở rộng.
Khi các tổ chức tiếp tục hiện đại hóa hoạt động kỹ thuật số, phân loại dự đoán ngày càng đóng vai trò là khả năng AI nền tảng, cho phép quy trình làm việc nhanh hơn, chi phí vận hành thấp hơn và hệ thống ra quyết định doanh nghiệp thông minh hơn.
Những quan niệm sai lầm thường gặp
Những quan niệm sai lầm về mô hình dự đoán thường dẫn đến việc các nhà lãnh đạo doanh nghiệp triển khai các thuật toán không hiệu quả trong điều kiện thực tế hoặc đòi hỏi bảo trì quá mức.
Quan niệm sai lầm 1: “Điểm chính xác 95% có nghĩa là mô hình đã sẵn sàng để đưa vào sản xuất.”
Thực tế: Các chỉ số độ chính xác cao có thể gây hiểu lầm về mặt toán học trên các tập dữ liệu không cân bằng, vì mô hình sẽ chỉ đơn giản là đoán lớp chiếm đa số để đạt điểm cao mà không học được bất kỳ quy luật thực tế nào. Độ chính xác (precision), độ thu hồi (recall) và điểm F1 (F1-score) là các chỉ số cần thiết để đánh giá hiệu suất hoạt động thực sự.
Quan niệm sai lầm 2: “Mô hình tự học và tự cải thiện trong quá trình hoạt động.”
Thực tế: Phần lớn các mô hình phân loại doanh nghiệp vẫn hoàn toàn không thay đổi sau khi triển khai. Chúng cần các chu kỳ huấn luyện lại có chủ đích, có cấu trúc bằng cách sử dụng các tập dữ liệu được cập nhật để duy trì hiệu suất và ngăn ngừa sự thay đổi mô hình.
Quan niệm sai lầm 3: “Mô hình tuân theo các quy tắc rõ ràng được lập trình bởi các kỹ sư của chúng tôi.”
Thực tế: Mô hình phân loại tạo ra các dự đoán xác suất dựa trên trọng số toán học được suy ra từ dữ liệu lịch sử, chứ không phải các quy tắc được lập trình chính xác. Điều này có nghĩa là các dự đoán vốn dĩ mang một mức độ không chắc chắn nhất định chứ không phải là độ chính xác tuyệt đối.
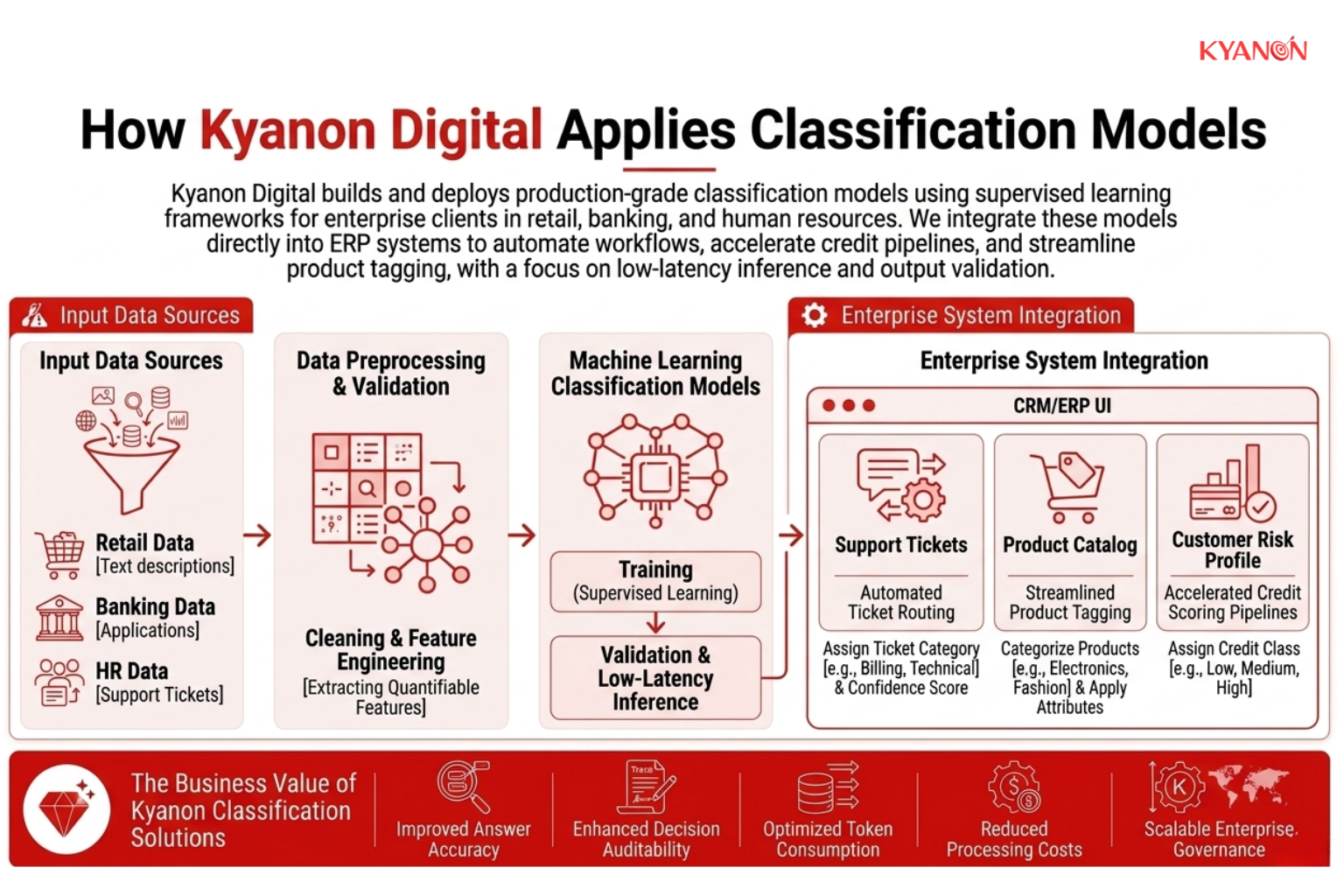
Cách Kyanon Digital áp dụng các mô hình phân loại
Kyanon Digital xây dựng và triển khai các mô hình phân loại cấp độ sản xuất sử dụng khung học có giám sát cho các khách hàng doanh nghiệp trong lĩnh vực bán lẻ, ngân hàng và nhân sự. Các nhóm kỹ thuật của chúng tôi tích hợp trực tiếp các mô hình này vào các hệ thống hoạch định nguồn lực doanh nghiệp (ERP) hiện có để tự động hóa việc định tuyến yêu cầu, tăng tốc quy trình chấm điểm tín dụng và hợp lý hóa việc gắn thẻ sản phẩm, với trọng tâm nghiêm ngặt vào suy luận độ trễ thấp và xác thực đầu ra.
→ Khám phá các dịch vụ Học máy của chúng tôi .







")




 Create project brief with AI
Create project brief with AI