

Retailers are rapidly investing in AI-driven retail analytics to improve demand forecasting, promotion performance, customer engagement, and operational efficiency. As consumer behaviour becomes harder to predict, traditional reporting is no longer enough to support fast, data-driven retail decisions.
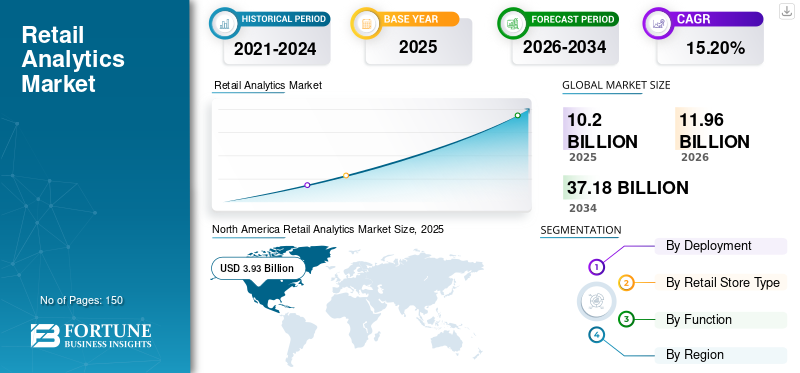
According to Fortune Business Insights, the global retail analytics market is projected to grow from USD 8.64 billion in 2023 to USD 31.08 billion by 2032, driven by rising adoption of AI and machine learning in retail operations.
However, many retail AI initiatives fail to deliver measurable ROI. The problem is usually not the AI model itself, but poor data quality, fragmented systems, inconsistent KPI definitions, and weak governance.
This article explores what AI-driven retail analytics actually means, the highest-value use cases in 2026, the data foundation required for success, and why data readiness determines whether AI analytics delivers real business impact.
Key takeaways
- AI is Execution, BI is Reporting: Traditional BI displays backward-looking charts. True AI analytics is a forward-looking, automated decision layer that triggers immediate operational actions
- Data Layer Breaks Projects: Up to 95% of retail AI initiatives fail because companies deploy advanced models on top of fragmented, unstandardized data silos
- Maturity Dictates Capability: You cannot deploy real-time optimization without mastering the basics: 24 months of clean SKU-store-day transactions and complete promotional logs
- Winners Invest in Foundations: Successful retail enterprises spend up to four times more of their budget on foundational data quality and governance than underperforming peers
- Fix Data Before Buying Tools: If you cannot resolve cross-channel customer identities or isolate historical stockouts, halt AI vendor selection and fix your data layer first
Further reading:
- AI in Ecommerce and Retail: Trends, Use Cases, and Business Impact
- AI in Retail: Revolutionizing Operations & Boosting Experience
- 7 Retail Analytics Decisions That Impact Revenue Most
- Building AI-Driven Pricing Systems for Retail
Why most retail AI projects fail before the model even runs
Most retail AI projects fail before the model even runs because companies attempt to deploy sophisticated algorithms on top of fragmented, unstructured, and ungoverned data infrastructure. According to Forbes, up to 80% to 95% of enterprise AI initiatives fail to deliver measurable ROI or reach production. The core barrier is almost never the math or the machine learning model itself; it is the fundamental lack of “AI-ready” data and clear operational strategy.

Broken data foundations
- Siloed legacy systems: Retail data is trapped across disconnected point-of-sale (POS) terminals, enterprise resource planning (ERP) databases, warehouse management software, and e-commerce platforms.
- No single source of truth: Inconsistent metric definitions (e.g., how “gross margin” or “active customer” is calculated across departments) confuse AI agents that lack human institutional intuition.
- Dirty and stale data: Outdated inventory logs, duplicate customer profiles, and missing historical records result in a “garbage in, garbage out” pipeline.Format Incompatibility: High-value retail context often stays locked in un-vectorized formats like scattered Excel sheets, localized PDFs, or vendor invoices that models cannot automatically ingest.
Strategic and organizational misalignment
- “FOMO” driving decisions: Retailers frequently launch AI initiatives because the technology is trending, rather than tying the project to a specific, measurable business problem like minimizing supply chain shrink or optimizing dynamic pricing.
- The “science experiment” trap: Projects are built in isolation by isolated technical teams without input from store operations, category managers, or compliance stakeholders.
- Unrealistic ROI horizons: Retail initiatives face immediate budget cuts because executive boards expect instant revenue bumps, failing to account for the necessary upfront runway to build proper data products.
Workflow and infrastructure gaps
- Advisory vs. Action Latency: Models are often designed to output standalone recommendations (e.g., a dashboard suggestion to reorder inventory) instead of directly integrating into automated operational workflows, creating human bottlenecks.
- Fragile ingestion pipelines: Moving real-time telemetry from thousands of retail brick-and-mortar stores requires stable data federation infrastructure that most organizations have not built.
- Passive staff sabotage: Floor managers and supply chain planners frequently reject or ignore new tools because change management is overlooked, leading employees to view the AI as an operational threat or an unnecessary burden.
What AI-driven retail analytics actually means
To understand why retail AI initiatives collapse early, enterprise leaders must first stop treating artificial intelligence as an extension of Business Intelligence (BI). They represent two entirely different technical paradigms, data architectures, and operational philosophies.
Distinguishing AI analytics from traditional BI
Traditional retail BI focuses on historical reporting:
- What sold yesterday?
- Which stores underperformed last month?
- Which campaign generated the highest revenue?
These systems rely on predefined queries against historical datasets. They are backward-looking by design.
AI-driven retail analytics works differently. Instead of static reporting, AI systems use machine learning models to identify patterns, predict future outcomes, and automate decision support using both historical and real-time signals.
This includes:
- Predicting demand before orders are placed
- Estimating promotional uplift before campaigns launch
- Detecting fraud patterns before losses escalate
- Recommending the next best customer action automatically
In other words, traditional BI explains what happened. AI analytics helps retailers decide what should happen next.

McKinsey’s retail AI research highlights that retailers are increasingly shifting toward AI-assisted merchandising, predictive assortment planning, and automated replenishment as consumer demand becomes harder to forecast through conventional methods.
The AI retail analytics use cases delivering real value in 2026
The retail applications yielding measurable bottom-line returns in 2026 bypass theoretical proofs-of-concept and embed directly into active execution pipelines.
- Demand forecasting at SKU-store-week granularity: Moving away from broad regional projections to bottom-up ML models built for individual stock-keeping units (SKUs) at specific physical storefronts on a weekly cadence. This directly minimizes lost sales from out-of-stocks while eliminating bloated safety stock overhead.
- Promotion optimisation: Simulating hundreds of cross-item promotional scenarios simultaneously. The models predict volume uplift, margin erosion, and inventory cannibalization to recommend the exact timing, discount depth, and marketing mechanics needed to maximize gross profit.
- Shelf analytics and planogram compliance: Merging real-time computer vision data feeds (from store cameras, smart carts, or associate handheld devices) with live point-of-sale (POS) transactional velocity to instantly flag misplaced items and phantom inventory.
- Customer segmentation and next-best-action automation: Aggregating omnichannel behavioral, transactional, and digital engagement signals into an algorithmic clustering engine. This automatically triggers hyper-personalized, contextual rewards and communications across digital touchpoints in real time.
- Anomaly detection: Deploying continuous, unsupervised machine learning loops across enterprise data streams to instantly isolate complex return fraud patterns, point-of-sale “sweethearting,” and unexpected supply chain bottlenecks before they scale into systemic losses.
Why these use cases require different data maturity levels
The primary reason retail AI projects fail before a model ever runs is a structural mismatch: leadership attempts to deploy a high-tier automation use case on top of a low-tier data foundation. Moving up the value chain requires distinct layers of infrastructure and matching data validation frameworks.
- Level 1: Foundational maturity (Required for Anomaly Detection): Demands centralized, cleaned, and audited historical transaction logs. If historical inventory ledgers do not balance, unsupervised anomaly models will continuously flag standard corporate data errors as fraud, paralyzing operations with alert fatigue.
- Level 2: Operational maturity (Required for demand forecasting & promotion optimisation): Requires high-frequency, granular data ingestion coupled with external variables like weather patterns, macroeconomic shifts, and competitor pricing scrapes. Attempting store-level forecasting using aggregate regional data blocks makes the model mathematically incapable of capturing localized volatility.
- Level 3: Advanced cognitive maturity (Required for shelf analytics & next-best-action): Demands low-latency, real-time streaming data pipelines and unstructured data processing architectures. Deploying a real-time next-best-action engine when online customer profile data takes 48 hours to sync with physical storefront checkouts results in highly irrelevant, friction-filled customer experiences.
The data stack that AI-driven retail analytics requires
To move from static Business Intelligence to an automated decision layer, retailers must build a modern, multi-tiered data stack. Each layer acts as a dependency for the next. Skipping foundational tiers is the root cause of early project failure.

Layer 1 – Governed Source Data
This layer handles raw, high-velocity data ingestion from operational edge touchpoints. It captures clean point-of-sale (POS) transactions, structured customer identities, complete promotion event logs, and consistent inventory records.
Why it matters
- Establishes foundational ground truth: It acts as the undisputed baseline for all retail enterprise operations.
- Eliminates data silos: It unifies data across physical shelves, warehouses, and digital storefronts.
- Secures clean ingestion: It prevents corrupt, duplicated, or fragmented records from entering the downstream analytics pipeline.
Business impact
- Flawless cross-channel tracking: Connects in-store checkouts with online accounts using deterministic resolution.
- Perfect inventory visibility: Tracks real-time stock movements across warehouses, transit networks, and shelves.
- Precise promotional tracking: Logs exact mechanic types and discount depths to measure true marketing ROI.
Layer 2 – Enriched and standardised data
This layer transforms raw transactional logs into high-context datasets. It blends disparate schemas, wipes out structural systemic noise, and enriches product, customer, and transaction histories.
Why it matters
- Removes operational noise: Automatically purges null fields, trailing white spaces, and duplicate payloads.
- Adds deep business context: Converts flat transaction logs into rich behavior and product profiles.
- Standardizes metadata: Creates uniform catalogs with granular category taxonomies, sizes, colors, and brands.
Business impact
- Instant customer segmentation: Generates automated Recency, Frequency, and Monetary (RFM) scores for targeted marketing.
- Optimized supplier management: Links localized supplier information directly to real-time product performance.
- High-integrity analytics: Ensures data scientists and BI tools work with pre-cleansed, reliable data.
Layer 3 – A Governed Data Platform
This layer acts as the centralized operational engine. It ensures data consistency, cross-department alignment, and end-to-end data auditability across the entire enterprise.
Why it matters
- Secures absolute consistency: Enforces a unified, immutable repository for all corporate metrics.
- Guarantees compliance: Provides end-to-end data auditability to meet strict regulatory and financial standards.
- Aligns cross-functional teams: Stops departments from arguing over mismatched numbers or conflicting reports.
Business impact
- Unified decision making: Establishes a single source of truth for key metrics like “gross margin” or “active customer.”
- Accelerated executive reporting: Reduces the time spent reconciling reports from weeks to minutes.
- Protected data assets: Lowers corporate compliance risks through strict, automated governance policies.
Layer 4 – AI and ML Infrastructure
The apex of the data stack converts stable enterprise data assets into high-frequency, predictive operational intelligence. It orchestrates automated feature engineering pipelines, structured model training schedules, and proactive real-time model monitoring loops.
Why it matters
- Automates ML readiness: Systematically transforms complex data matrices into reusable feature stores.
- Adapts to market volatility: Aligns model retraining frequencies with rapid shifts in external market conditions.
- Guarantees model health: Uses observability loops to detect concept and data drift before predictions degrade.
Business impact
- Predictive business operations: Shifts the enterprise from historical reporting to real-time, proactive forecasting.
- Adaptive customer targeting: Matches fast-evolving, real-world customer behaviors with highly accurate machine learning models.
- Minimized decision risk: Prevents costly automated operational errors by catching model inaccuracies early.
Four AI analytics use cases – What they need and what they deliver
Deploying AI in enterprise retail requires matching your business goals with your structural capabilities. Below is an operational breakdown of the four high-yield use cases delivering measurable bottom-line value in 2026.
Use case 1 – Demand forecasting
What it does
This engine predicts precise future demand at individual SKU-store-week granularity. Instead of relying solely on baseline historical sales trends, the machine learning models dynamically ingest and analyze external market signals – including hyper-local weather shifts, community events, corporate promotional calendars, and real-time competitor pricing scrapes.

Data requirements
- Historical deep-dive: Minimum of 2+ years of clean point-of-sale (POS) data captured at a perfectly consistent granular level.
- Flawless promotional tracking: A complete historical promotional log detailing exact timelines, marketing tactics, and mechanics. Missing promotion entries create unexplained demand spikes in training data, confusing the model.
- Structured inventory telemetry: Historical inventory logs that flag stockouts. If a store runs out of an item, the model must know that sales dropped due to zero availability, not zero customer interest.
- Harmonized external feeds: Third-party data streams (weather, local foot traffic) mapped to identical historical dates and localized store coordinates.
What it delivers
- Inventory cost reduction: Typically drives a 10% to 30% reduction in total inventory holding costs within mature implementations by slashing safety stock safety nets.
- Supplier leverage: Improves procurement negotiations by providing vendors with highly accurate, forward-looking purchase order commitments.
- Promotional synchronization: Boosts promotional ROI by optimizing pre-promotion inventory positioning, ensuring shelves are stocked before a marketing campaign launches.
What breaks it
- Granularity volatility: Mixing inconsistent data timelines, such as having half your retail network reporting daily transactions while the other half uploads weekly batches.
- Ghost promotions: Unrecorded price drops or localized marketing pushes that trigger massive sales spikes the model cannot mathematically explain or replicate.
- The zero-demand trait: Systematically logging out-of-stock periods as “zero customer demand” instead of isolating them as “demand not observed.” This causes the model to under-forecast future stock needs.
Use case 2 – Promotion optimisation
What it does
This use case analyzes historical promotion performance to accurately project volume and revenue uplift for planned marketing campaigns. It acts as a prescriptive engine, recommending the optimal operational timing, discount depth, and specific SKU selection to maximize margin performance.

Data requirements
- Structured promotion audits: A granular registry documenting past campaigns, including exact mechanic type (e.g., Buy-One-Get-One vs. 20% off), discount percentages, precise duration, and targeted SKU clusters.
- Clean baseline demands: Clearly isolated sales data from non-promotional periods for every SKU at every physical and digital node.
- Competitor activity maps: Historical scrapes of rival pricing, matching promotional calendars, and market share adjustments where available.
What it delivers
- Margin protection: Higher promotional ROI by identifying and eliminating campaigns that trigger extreme margin erosion or cross-item cannibalization.
- Budget optimization: Sharp reduction in marketing budget waste by identifying and halting promotions that yield low volume uplift.
- Strategic merchandising: Improved category-level planning, giving merchandising teams the data needed to design complementary product cross-sells.
What breaks it
- The 30% blind spot: Incomplete promotion records. If more than 30% of historical promotional campaigns are unrecorded, the model lacks the mathematical foundation to accurately project future performance.
- Vague promotion mechanics: Labeling historical events generically as a “discount” without defining the explicit percentage, bundle structure, or marketing channel used.
- Perpetual discounting loops: An environment where items are constantly on sale. If a product is perpetually discounted, a true non-promotional baseline cannot be established, rendering elasticity modeling impossible.
Use case 3 – Customer segmentation and next-best-action
What it does
This consumer intelligence layer clusters customer profiles based on verified behaviors (RFM scores, product preferences, and channel engagement). It calculates and executes the optimal next-best-action for every segment, picking the best product to recommend, coupon to present, and digital touchpoint to use.

Data requirements
- Unified customer identity: A centralized Customer Data Platform (CDP) providing a single, deterministic identity across all online and offline sales points.
- Exhaustive purchase ledgers: Complete, unbroken transactional histories linked to each unique customer ID.
- Omnichannel interaction logs: Real-time collection of digital and physical touchpoints, including email clicks, mobile app sessions, web browsing, and in-store loyalty scans.
What it delivers
- Surging conversions: Significantly higher conversion rates on direct, personalized marketing communications by eliminating generic spam.
- Proactive retention: Sharp reduction in customer churn by identifying at-risk consumer behaviors early and triggering automated retention offers.
- AOV growth: Increased Average Order Value (AOV) by serving highly relevant cross-sell and up-sell recommendations when the customer is most likely to buy.
What breaks it
- Identity duplication: Fragmented customer profiles. If a customer has separate accounts for the mobile app, website, and in-store loyalty card, the model splits their history, leading to highly inaccurate behavioral predictions.
- Siloed interaction data: Omitting channel-specific telemetry. If email click data is missing, the model will waste budget sending promotional emails to a customer who only interacts via SMS or push notifications.
Use case 4 – Anomaly detection and operational intelligence
What it does
Operating as an automated security and compliance layer, this engine monitors high-velocity operational data streams to flag unusual patterns across sales velocity, return rates, inventory adjustments, and checkout behaviors. It strips away data noise to surface clean, actionable alerts directly to store managers and operations executives.

Data requirements
- Structured stream consistency: Unbroken operational data feeds capturing sales, returns, line items, and physical warehouse inventory adjustments.
- Localized context baselines: Clear historical baselines calculated for each unique store-SKU combination to dynamically map what constitutes a “normal” operational rhythm.
- Low-latency pipelines: Near-real-time data ingestion infrastructure capable of processing storefront feeds without data lag.
What it delivers
- Rapid leakage mitigation: Faster identification of point-of-sale fraud, return policy abuse, operational bottlenecks, and employee “sweethearting.”
- Early warning infrastructure: Real-time alerts highlighting immediate stockout risks or supply chain disruptions before they negatively impact customer experience.
- Reduced administrative burdens: Eliminates the need for store managers to manually review daily exception reports, freeing them up to focus on floor operations.
What breaks it
- Inconsistent KPI definitions: Fragmented operational logic across different stores. If Store A logs internal item movements differently than Store B, the unsupervised model will flag these reporting differences as fraud, creating immense alert fatigue.
- The batch data bottleneck: Relying on daily batch processing files instead of low-latency, real-time data streaming pipelines. Finding out a critical return fraud trend occurred 24 hours after the thief left the store completely destroys the business value of the model.
Why bad data makes every retail AI analytics project fail
The harsh reality of enterprise retail optimization is that the algorithm is almost never the reason an artificial intelligence project collapses. When an executive initiative fails to deliver ROI, leadership frequently blames the software vendor, the data science team, or the maturity of the machine learning model itself. This is a costly diagnostic error.
Market research validates that this is an infrastructure crisis, not a mathematical one:
- An investigation published via ResearchGate highlights that up to 80% of enterprise AI initiatives fail, experiencing an epidemic of “pilot paralysis” where prototypes cannot scale.
- A Gartner Data & Analytics Press Release reports a stark reality: 60% of enterprise AI projects are abandoned entirely due to a lack of AI-ready data.
- Furthermore, Gartner Research on AI Investments reveals that organizations achieving successful AI outcomes invest up to four times more of their revenue into foundational data quality and governance compared to underperforming peers.
The AI tool is not a magic cure; it is a highly sensitive diagnostic instrument. It does not create operational dysfunction – it merely shines a bright, expensive light on the structural breaks, silos, and data corruption that already existed within your corporate data layers. If your underlying data is broken, your AI outputs will simply automate and accelerate bad decisions at scale.
As the foundational rule of algorithmic merchandising dictates: “You cannot forecast what you haven’t measured correctly.”
Three root causes of AI analytics failure in retail
While operational teams often blame code limitations, systemic retail AI failures can consistently be traced back to three distinct structural blind spots within the enterprise data pipeline.

Bad data at the source (The operational edge)
The pipeline is corrupted at the exact moment of creation. If front-end systems generate inaccurate telemetry, downstream models are mathematically dead on arrival.
- Corrupted POS inputs: Cashiers using generic override barcodes or scanning a single flavor variant to clear a long checkout queue permanently destroys SKU-level inventory accuracy.
- Fragmented application ingestion: Mobile applications dropping session logs or failing to serialize digital clickstream tokens when a customer steps into a physical storefront, creating massive data gaps.
- Real-world impact: According to research published by Concord USA on Retail AI Pitfalls, 33% of retailers struggle with base data quality, leading directly to flawed automated inventory allocations and broken, nonsensical automated customer recommendations.
Missing enrichment and standardisation (The context void)
Raw transactional logs lack the rich contextual scaffolding and metadata intelligence that machine learning models require to identify behavioral patterns and cross-elasticity signals.
- Inconsistent product taxonomies: Merchandising systems assigning varying attribute tags to identical products across different regions (e.g., classifying an item as “Beverage” in one database and “Grocery – Liquid” in another), making automated category-level optimization impossible.
- Identity duplication: Failing to resolve online customer profiles with offline brick-and-mortar loyalty scans, which forces behavioral modeling engines to analyze fragmented, half-blind consumer histories.
No data governance (The structural anarchy)
Without strict enterprise oversight and explicit data stewardship roles, an organization cannot maintain data integrity. Data quality naturally degrades into isolated, departmental silos.
- Absence of a single source of truth: Finance, Supply Chain, and Marketing all using slightly different SQL calculations to define standard KPIs like “Gross Margin” or “Active User,” causing automated decision systems to run into logical conflicts.
- No ownership models or quality SLAs: Operating without automated data-quality alerts or strict Service Level Agreements (SLAs) regarding data ingestion completeness, latency, and schema drift. This results in models training on stale or partially missing data pools without anyone realizing it.
- Real-world impact: Analysis shared by NTT Data shows that between 70% and 85% of GenAI deployment efforts fail to meet their desired ROI, primarily due to governance gaps rather than technical limitations. Conversely, organizations with mature governance focus on fewer, highly-governed pipelines and achieve more than twice the ROI of ungoverned enterprises.
Where to start: A retail AI analytics readiness assessment
Before your organization signs an enterprise contract with an AI vendor or tasks your data science team with building a custom machine learning model, you must evaluate your structural baseline.The industry benchmark from Gartner for technology deployment is definitive: organizations that achieve successful, high-yield AI outcomes invest up to four times more of their revenue into foundational data quality and governance compared to underperforming peers. If you attempt to bypass this foundation, your project will likely join the 60% of enterprise AI initiatives that are abandoned entirely due to lack of AI-ready data, stated by Gartner.
Three questions to assess strategic AI readiness
To determine if your business is prepared to deploy true predictive or prescriptive AI analytics, run your data infrastructure through these three diagnostic filters:
- Can you produce a consistent demand history at SKU-store-day granularity for the last 24 months?
- Why it matters: Advanced algorithms like granular demand forecasting require deep, unbroken historical baselines to understand hyper-local volatility, holiday patterns, and seasonality.
- The failure point: If your physical stores overwrite transactional logs, report data in broad weekly aggregates, or bundle different product flavors under a single generic barcode, the model cannot isolate true consumer velocity.
- Do you have a complete, structured promotional event log for that same period?
- Why it matters: Machine learning models learn by correlating causes with effects. To understand why a specific item experienced an intense sales surge last spring, the model must know an active marketing campaign caused it.
- The failure point: If 30% or more of your historical promotions went unrecorded, or if price drops were applied manually on store floors without logging the exact mechanic type and discount depth, the model will mistake these events for random demand spikes, permanently corrupting your forward-looking forecasts.
- Do you have a single governed customer identity across all channels?
- Why it matters: Running next-best-action triggers or algorithmic segmentation requires an unbroken view of the consumer journey.
- The failure point: If a single customer is logged as three separate entities because your web e-commerce database, mobile app telemetry, and in-store loyalty card registry operate in disconnected silos, your personalization engine will generate conflicting, irrelevant recommendations that actively damage brand trust.
Three questions to assess strategic AI readiness
The executive framework: Fix the data layer first
If the honest answer to any of the three questions above is “No,” you must halt your AI tool selection process immediately. Choosing an advanced analytics vendor or selecting an LLM orchestration layer at this stage is a waste of corporate capital. Your starting point is not the model; it is your data architecture.
- Phase 1: Standardize the edge: Clean your source telemetry. Force unified item identifier compliance at your point-of-sale systems and establish deterministic identity resolution pipelines across your digital properties.
- Phase 2: Govern the middle: Build a single source of truth. Lock down identical KPI definitions across finance, marketing, and supply chain teams, and set up automated alerts to flag schema drift or data gaps before they reach analytical storage layers.
- Phase 3: Deploy the automation layer: Only after your data pipelines consistently hit your quality metrics should you deploy machine learning models. At this stage, your clean data will allow the AI engine to transition seamlessly from a pilot into a high-ROI, automated execution asset.

How Kyanon Digital builds AI analytics capability for retail
Enterprise retail leaders across Singapore, Malaysia, and the ANZ region do not need more software licenses; they need an integrated, scalable analytics pipeline that converts high-velocity operational signals into immediate bottom-line profit. As a leading digital & technology company, Kyanon Digital designs, builds, and optimizes end-to-end AI analytics stacks tailored specifically for complex enterprise retail environments.
Kyanon Digital maps your technical journey across every layer of the modern data stack, ensuring your engineering architecture can support advanced automation without structural failure.
- Data foundation assessment & cleansing: We audit and clean fragmented legacy point-of-sale (POS) silos, eradicate duplicate customer files, and resolve omnichannel consumer identities into unified databases.
- Enterprise governance & lineage: We build a single source of truth across your business units, locking down identical SQL logic for your core KPIs and establishing automated alerting networks to eliminate schema drift.
- ML model deployment & feature stores: Our data teams construct robust feature engineering pipelines that feed production-ready machine learning models, enabling bottom-up SKU-store-week forecasting and real-time next-best-action triggers.
- Continuous model observability: We implement advanced model monitoring frameworks that continuously flag concept drift and data latency issues, backed by point-in-time recovery protocols to preserve training weight integrity.
Case study: AI-Driven BI & Data Warehouse For A Leading Retail Corporation

Introduction
A leading retail and trading corporation in Vietnam, operating more than 193 stores nationwide, partnered with Kyanon Digital to modernize its reporting and analytics ecosystem. The company needed to replace fragmented, manual reporting processes with a centralized, AI-driven business intelligence and data warehouse solution that could support real-time decision-making at scale.
Challenges
The organization faced several operational and data management issues as the business expanded:
- Manual reporting workflows were time-consuming, error-prone, and inefficient.
- Data was fragmented across multiple systems with no centralized repository.
- Leadership lacked real-time visibility into store operations and performance.
- Report approval processes were slow and difficult to track.
- Existing systems could not support scalable analytics or enterprise-wide reporting.
Solutions
- Built a centralized AI-driven BI and Data Warehouse platform.
- Automated reporting and approval workflows.
- Integrated Power BI dashboards for real-time analytics and operational visibility.
Impact
The transformation delivered measurable operational and strategic improvements across the retail organization:
- Reduced reporting errors and eliminated manual bottlenecks.
- Accelerated report submission and approval cycles.
- Centralized and standardized enterprise data for greater accuracy and consistency.
- Improved real-time visibility into store operations and performance metrics.
- Enabled faster, more confident, data-driven decision-making for leadership.
- Created a scalable data foundation to support future analytics and AI initiatives.
Explore the full story here: AI-Driven BI & Data Warehouse For A Leading Retail Corporation
Take the first step to scalable retail AI
Do not risk your technology capital on sophisticated algorithms until you have verified your data infrastructure is prepared to support them.
Contact Kyanon Digital today to request a comprehensive Retail AI Analytics Readiness Assessment. Our enterprise data architects will audit your existing POS pipelines, identity resolution frameworks, and historical event logs to deliver a clear, risk-mitigated roadmap directly aligned with your 2026 revenue targets.















")




 Create project brief with AI
Create project brief with AI