What is BERT?
BERT, which stands for Bidirectional Encoder Representations from Transformers, is an open-source machine learning framework for natural language processing (NLP) developed by Google in 2018. Unlike traditional language models that read text sequentially left-to-right or right-to-left, BERT is bidirectional, meaning it analyzes the context of a word by looking at the words both before and after it simultaneously. This design allows it to accurately grasp the true meaning of ambiguous words based on their surroundings.
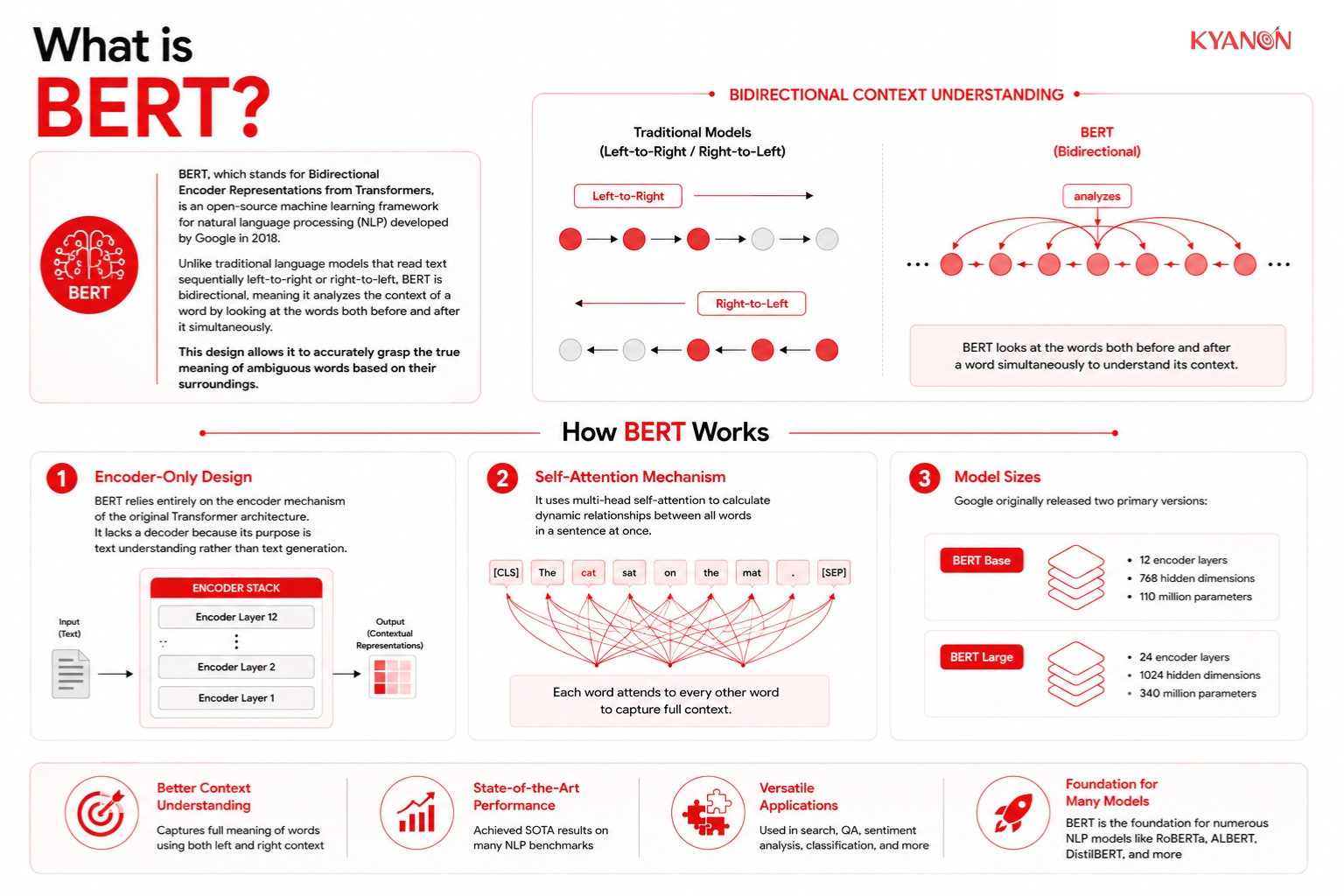
How BERT Works
- Encoder-Only Design: BERT relies entirely on the encoder mechanism of the original Transformer architecture. It lacks a decoder because its purpose is text understanding rather than text generation.
- Self-Attention Mechanism: It uses multi-head self-attention to calculate dynamic relationships between all words in a sentence at once.
Model Sizes: Google originally released two primary versions:
- BERT Base: 12 encoder layers, 768 hidden dimensions, and 110 million parameters.
- BERT Large: 24 encoder layers, 1024 hidden dimensions, and 340 million parameters.
How BERT is trained
BERT is first pre-trained on a massive unlabeled text corpus (like English Wikipedia and BooksCorpus) using two simultaneous, self-supervised tasks:
- Masked Language Modeling (MLM): The model hides (masks) 15% of the words in a sentence and attempts to guess what those words are. This forces the model to look left and right to understand the context.
- Next Sentence Prediction (NSP): The model is given pairs of sentences and must predict whether the second sentence logically follows the first one in the original text.
BERT vs GPT
Both frameworks process natural language using Transformer architecture, but BERT excels at understanding existing text, whereas GPT is optimized for generating new text.
|
Feature |
BERT | GPT (e.g., GPT-4) |
| Architecture | Transformer Encoder-only |
Transformer Decoder-only |
|
Context |
Bidirectional (looks left and right) | Autoregressive / Unidirectional (looks left to right) |
| Primary Strength | Text understanding and classification |
Text generation and conversation |
Common Applications of BERT
Because it excels at deep comprehension rather than creating text, developers use BERT by adding a single output layer to fine-tune it for specific tasks:
- Search Engine Optimization: Powers core components of Google Search to better match complex, conversational queries with relevant results.
- Sentiment Analysis: Identifying the underlying emotion or tone in customer reviews or social media posts.
- Question Answering: Extracting precise answers from a block of text, notably evaluated on the SQuAD dataset.
- Named Entity Recognition (NER): Identifying and categorizing specific entities like names, dates, organizations, and locations within raw text.
When to consider BERT
Consider BERT if:
- Your enterprise processes thousands of unstructured legal or financial documents and requires automated extraction of specific data points without hallucination risks.
- Your customer service chatbot struggles to accurately classify user intent when queries contain nuanced phrasing or industry-specific terminology.
- Your internal search engine returns keyword-matching results rather than contextually relevant documents, increasing employee information retrieval time.
It may not be the right priority if:
- Your primary requirement is drafting original content, summarizing long-form articles into new formats, or building conversational agents that require extensive open-ended dialogue generation.
Why BERT matters for enterprise operations
According to Google’s search, the initial deployment of BERT improved the understanding of search intent for 10% of all English queries in the US, demonstrating its fundamental capacity to interpret human phrasing at an enterprise scale. A regional logistics company in Southeast Asia implemented a BERT-based model to parse unstructured customs declarations, reducing manual entry errors and significantly decreasing document processing time. This demonstrates how BERT translates from an architectural principle to measurable business impact.
Common misconceptions
We can use BERT to generate text like ChatGPT
Reality: BERT is an encoder-only model built specifically to analyze and classify existing text, not to generate new text. For generative tasks like drafting emails or writing code, decoder-based models like GPT-4 are the necessary architectural choice.
We need to deploy the largest BERT model available to get the best accuracy
Reality: While BERT-Large scores higher on academic benchmarks, it requires significantly more compute resources and introduces processing latency. For most production environments, BERT-Base or computationally lighter versions like DistilBERT provide sufficient accuracy while keeping infrastructure costs manageable and total cost of ownership low.







")




 Create project brief with AI
Create project brief with AI