What is Classification?
Classification is a supervised machine learning technique where an algorithm maps input variables to discrete, predefined output categories. It functions by analyzing labeled training data to establish mathematical decision boundaries, enabling the automated sorting of new, unseen instances.
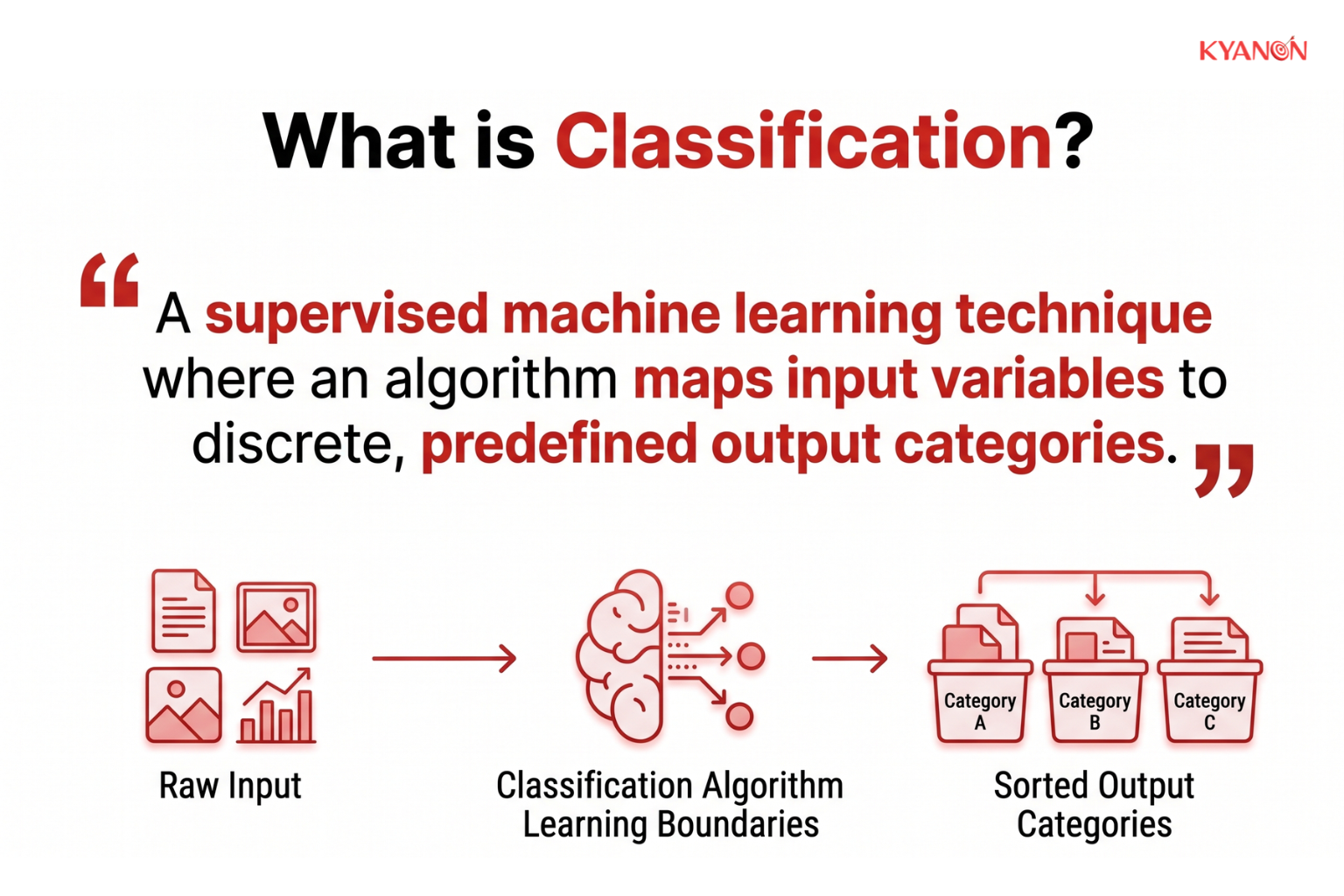
Unlike unsupervised methods that discover hidden groupings, classification models operate with known labels. The system learns from previously categorized data, then predicts the correct category for new incoming information.
In enterprise environments, classification powers many of the automated decisions organizations rely on every day:
- Detecting fraudulent financial transactions
- Categorizing customer support tickets
- Identifying high-risk loan applications
- Filtering spam emails
- Prioritizing sales leads
- Classifying insurance claims
- Sorting products into digital catalogs
At scale, classification transforms manual decision-making into a repeatable, data-driven operational capability.
How Classification Works
A classification model operates by analyzing labeled data to identify correlations, then applying learned weights to unseen data to return the category with the highest statistical confidence.
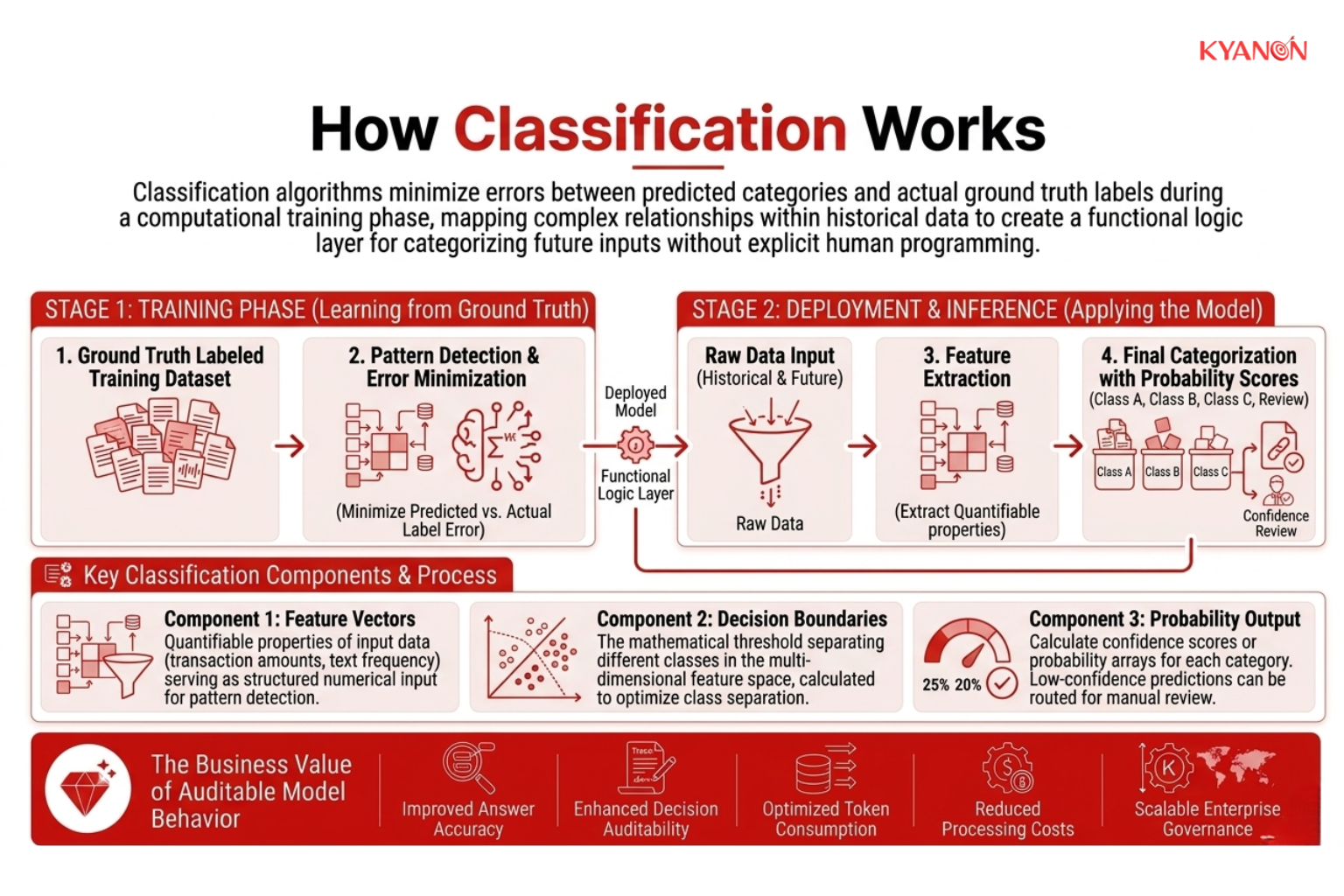
In modern enterprise operations, classification replaces rigid, manual, rule-based systems with dynamic, self-improving logical models. Instead of software engineers writing thousands of complex nested “if/then” scripts that break whenever market conditions or data formats shift, a supervised learning algorithm learns the underlying relationships directly from your historical data. This creates an automated decision intelligence layer that scales seamlessly, allowing organizations to process millions of complex data transactions, document classification requests, and customer inquiries in real time without human bottlenecks.
Key Component 1: Feature Vectors
Feature vectors are the structured numerical representations of real-world business data that machine learning models use to make predictions. Every classification system depends on converting operational information into measurable variables that algorithms can mathematically analyze.
In enterprise environments, raw data rarely arrives in a format suitable for AI systems. Customer transactions, support emails, browsing behavior, product descriptions, or financial records must first be transformed into quantifiable signals called features.
Examples of enterprise features may include:
- Transaction amount
- Purchase frequency
- Customer lifetime value
- Time of transaction
- Device type
- Geographic region
- Sentiment score from customer messages
- Product specifications
- Historical repayment behavior
Together, these variables form a feature vector, a structured data profile representing a single observation or event.
In practice, feature engineering is not simply a technical preprocessing step. It is the process of translating operational business behavior into machine-readable intelligence.
Key Component 2: Decision Boundaries
Once the system learns from historical data, the classification model establishes decision boundaries, mathematical thresholds that separate one category from another within the feature space.
These boundaries determine how the system classifies future inputs.
For example, a banking classification system may separate:
- Legitimate transactions
- Medium-risk anomalies
- High-risk fraud events
Based on combinations of:
- Spending behavior
- Transaction timing
- Geographic inconsistency
- Device usage patterns
- Customer history
The model continuously evaluates where one operational category ends and another begins.
Conceptually, decision boundaries function like invisible dividing lines inside a multidimensional environment where every feature contributes to positioning the data point.
In enterprise AI, the objective is not simply maximizing prediction accuracy. The goal is establishing operationally safe, commercially efficient, and strategically governable decision logic.
Key Component 3: Probability Output
Rather than returning a simple binary label, enterprise classifiers calculate a confidence score or probability array for each category. This quantitative output allows systems to apply custom thresholds, routing low-confidence predictions to human operators for manual review.
This probabilistic architecture is critical in enterprise operations because real-world business decisions involve uncertainty, risk, and varying tolerance thresholds.
Probability outputs allow organizations to design layered operational workflows instead of relying on rigid automation.
For example:
- Predictions above 95% confidence may trigger automatic approval or rejection
- Medium-confidence predictions may escalate to human analysts
- Low-confidence outputs may require additional data validation
- Edge cases may enter secondary review pipelines
This creates a scalable human-in-the-loop governance structure where AI augments operational capacity without removing oversight.
The business value of probability scoring extends beyond automation alone. It also supports:
- Risk prioritization
- SLA optimization
- Resource allocation
- Compliance auditing
- Exception management
- Workflow orchestration
For executive stakeholders, probability outputs are especially important because they transform AI from a black-box prediction engine into a controllable operational system with measurable confidence levels.
Ultimately, probability outputs are what allow enterprise AI systems to balance automation speed with governance control, operational safety, and customer trust.
Classification vs Clustering
Both techniques partition data, but classification relies on labeled historical data while clustering discovers hidden groupings in unlabeled datasets.
|
Dimension |
Classification | Clustering |
| Learning Paradigm | Supervised (requires labeled data) |
Unsupervised (no labels needed) |
|
Business Objective |
Predict specific known categories | Discover unknown segments |
| Upfront Data Preparation | High (requires manual tagging) |
Low (uses raw structured data) |
|
Core Algorithms |
Random Forest, XGBoost, SVM | K-Means, DBSCAN, Hierarchical |
| Enterprise Use Case | Credit risk scoring, Resume screening |
Customer segmentation, Anomaly detection |
When to Consider Classification
Consider Classification if:
- Your operations require processing thousands of repetitive decisions daily, such as sorting customer service tickets by urgency or routing them to specific departments.
- You hold extensive historical datasets with clear, verifiable outcomes to serve as the ground truth required for model training.
- Your risk management protocols demand real-time, rule-based assessments, such as approving or declining financial transactions instantly.
It may not be the right priority if:
- Your enterprise lacks accurately labeled historical data to train the algorithm, making the initial data annotation cost financially prohibitive.
Why Classification Matters for Enterprise Operations
Implementing predictive categorization replaces heuristic-based rules with data-driven logic, directly compressing the time-to-market for digital services.
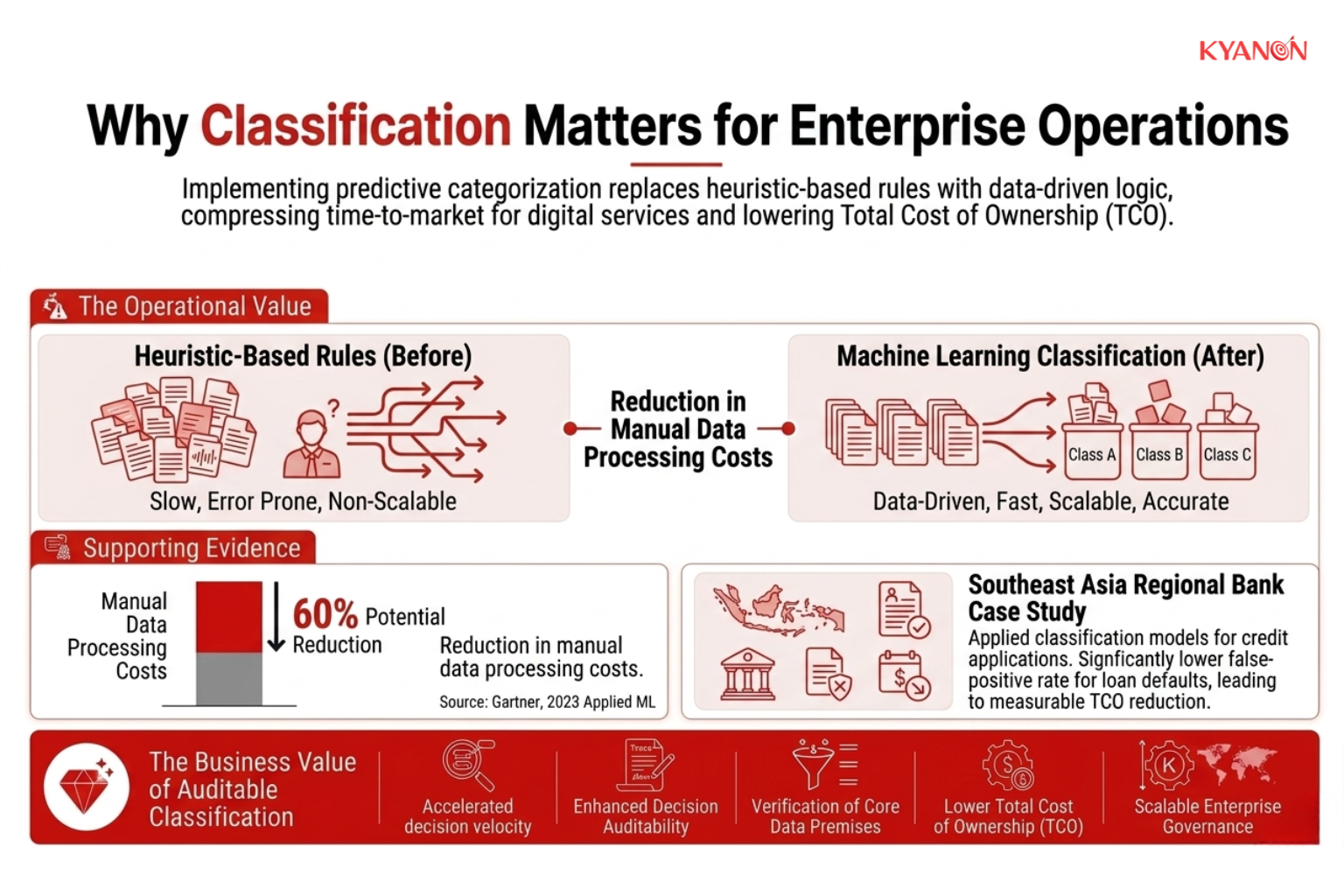
A properly designed classification model can help enterprises:
- Reduce manual processing workloads
- Accelerate operational response times
- Improve consistency across departments
- Lower decision-making costs
- Increase accuracy in repetitive tasks
- Scale operations without proportional staffing increases
For example:
- A retail enterprise may automatically classify thousands of new products into taxonomy categories each day.
- A bank may classify loan applications into approval risk tiers.
- A customer service organization may automatically route support tickets by urgency and intent.
- An HR platform may classify resumes based on skill relevance and role fit.
According to industry studies from Gartner, AI-driven automation initiatives increasingly focus on operational classification because of its measurable impact on cost reduction, workflow efficiency, and service scalability.
For executive teams, classification is not simply a technical model. It is an operational leverage mechanism.
Common Misconceptions
Misconception 1: “High accuracy equals low uncertainty; a model with 95% accuracy is highly confident.”
Reality: Accuracy metrics calculate overall correctness but obscure individual prediction confidence. An algorithm can guess correctly by a narrow margin; therefore, production systems require probability thresholds to flag low-confidence decisions for human review.
Misconception 2: “Imbalanced data needs no special care; default 0.5 thresholds work fine for 1% event rates.”
Reality: Using default 0.5 probability thresholds on highly imbalanced sets causes the model to ignore the minority class completely, leading to 0% sensitivity. Enterprise deployments require adjusted decision boundaries or specialized loss functions to ensure critical minority events, such as credit fraud, are accurately detected.
Misconception 3: “More data always improves performance.”
Reality: Without strict quality controls, more data introduces more noise, leading the model to learn irrelevant information and overfit. Data quality, accurate labeling, and feature engineering dictate model success far more than raw dataset volume.
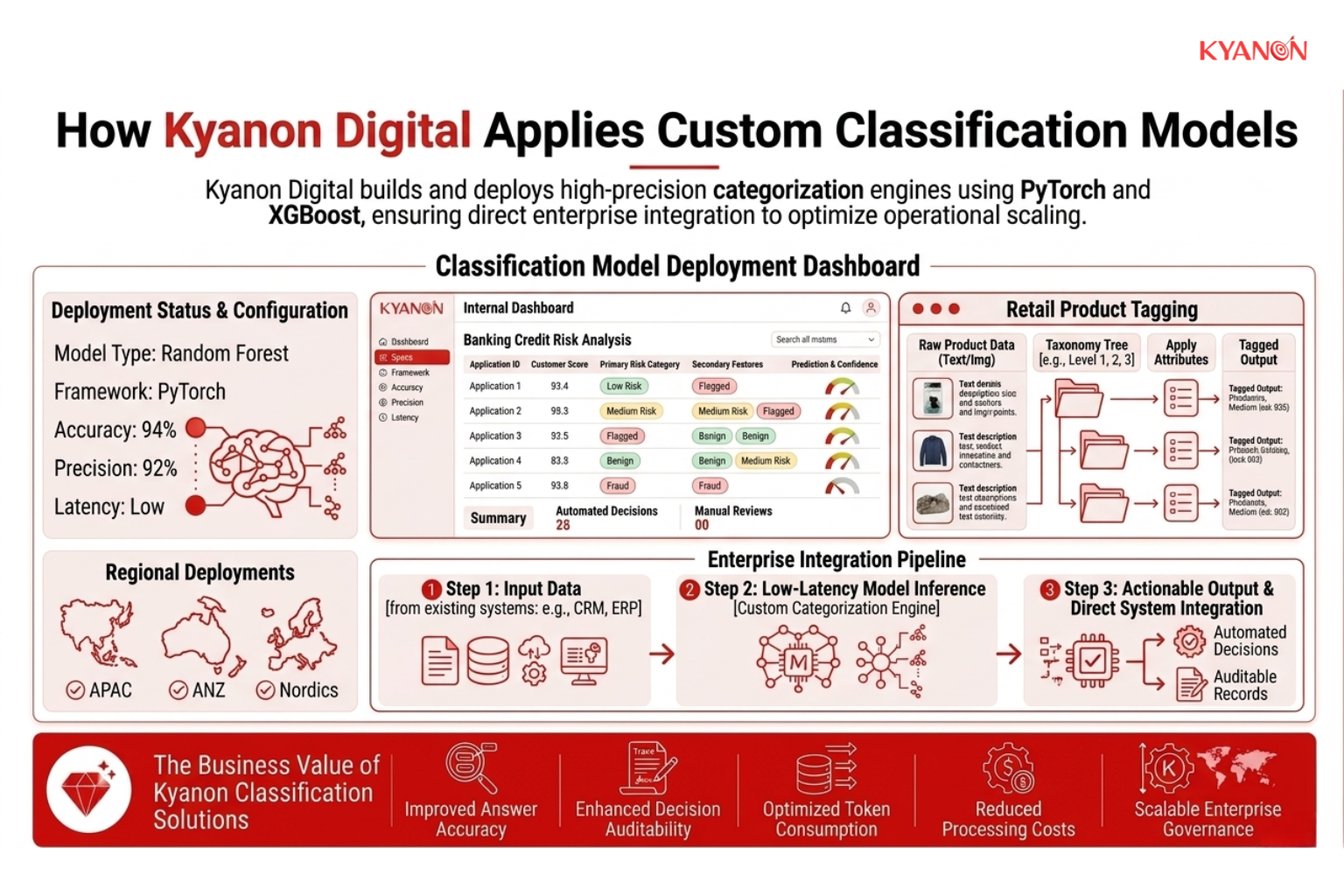
How Kyanon Digital Applies Classification
Kyanon Digital builds and deploys custom classification models using frameworks like PyTorch and XGBoost for enterprise clients across the APAC, ANZ, and Nordic regions. Our approach focuses on developing high-precision categorization engines for retail product taxonomies, banking credit risk matrices, and HR resume screening, ensuring direct integration into existing enterprise architectures to optimize operational scaling.
→ Explore our Machine Learning services.







")




 Create project brief with AI
Create project brief with AI