What is Data Augmentation?
Data augmentation is a machine learning technique used to artificially expand and diversify training datasets by creating modified variations of existing data while preserving the original meaning or label. Instead of collecting entirely new data, which is often expensive, slow, and operationally complex at enterprise scale, organizations generate additional training examples through controlled transformations such as image rotation, text paraphrasing, noise injection, translation, masking, or synthetic data generation.
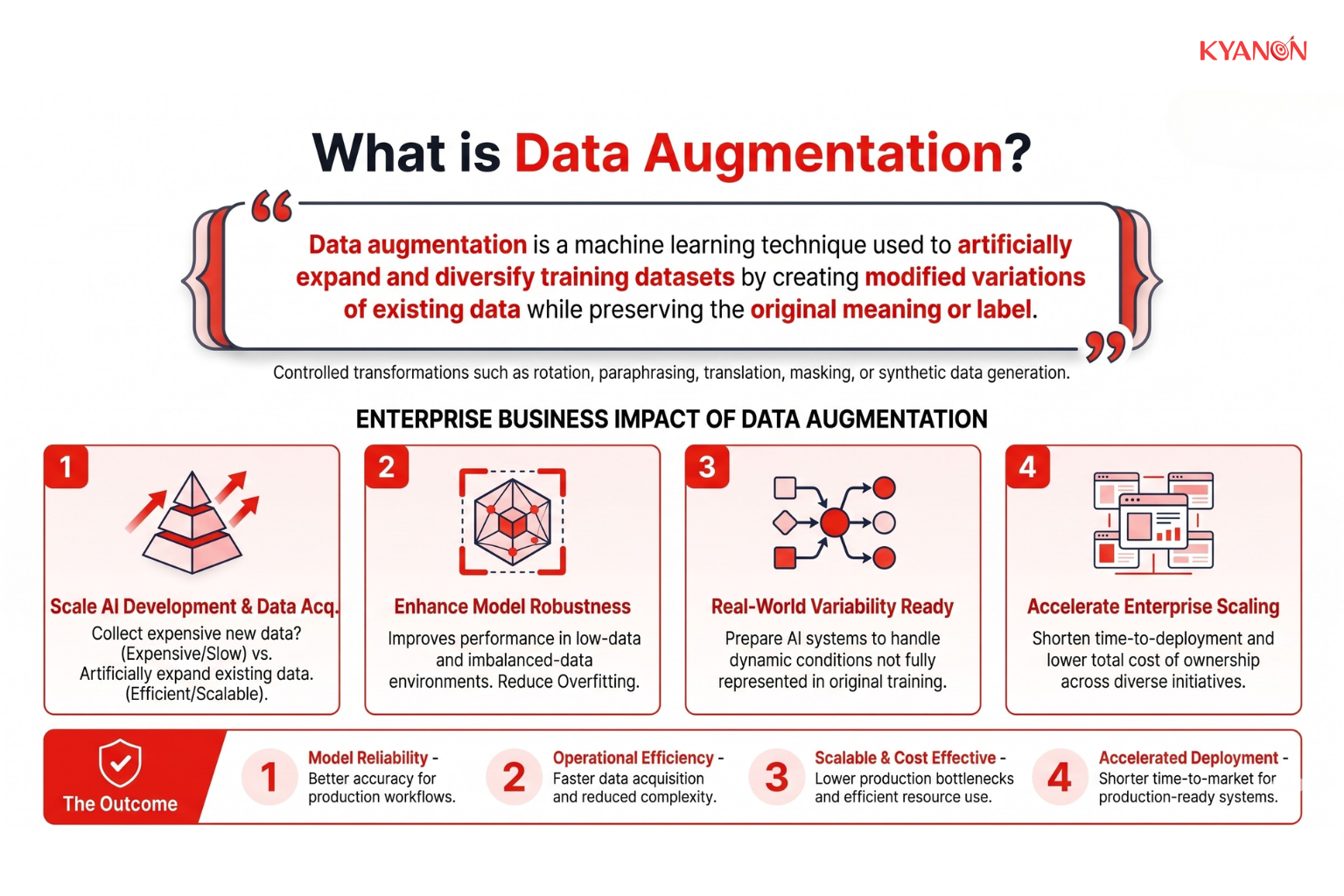
In practical enterprise AI environments, data augmentation functions as a scalability and risk-reduction mechanism. It improves model robustness, reduces overfitting, enhances generalization to real-world conditions, and helps AI systems maintain performance when encountering variations not fully represented in the original dataset.
For enterprise leaders, data augmentation is not simply a technical preprocessing task. It is a strategic capability that directly impacts:
- AI model accuracy and reliability.
- Speed of AI deployment.
- Cost efficiency of data acquisition.
- Performance in low-data or imbalanced-data environments.
- Scalability of AI initiatives across business units and regions.
As organizations increasingly deploy AI into customer-facing, operational, and revenue-generating workflows, augmentation becomes critical for building production-ready systems capable of handling real-world variability rather than idealized training conditions.
How Data Augmentation Works
Data augmentation works by exposing the machine learning algorithm to diverse variations of the core dataset during the training loop. Rather than serving as a static preprocessing step, it operates dynamically as a regularization mechanism built into training to reduce model variance. By mathematically modifying the input data while maintaining its original classification, the model learns to ignore irrelevant patterns and focus on the essential features that define a specific class.
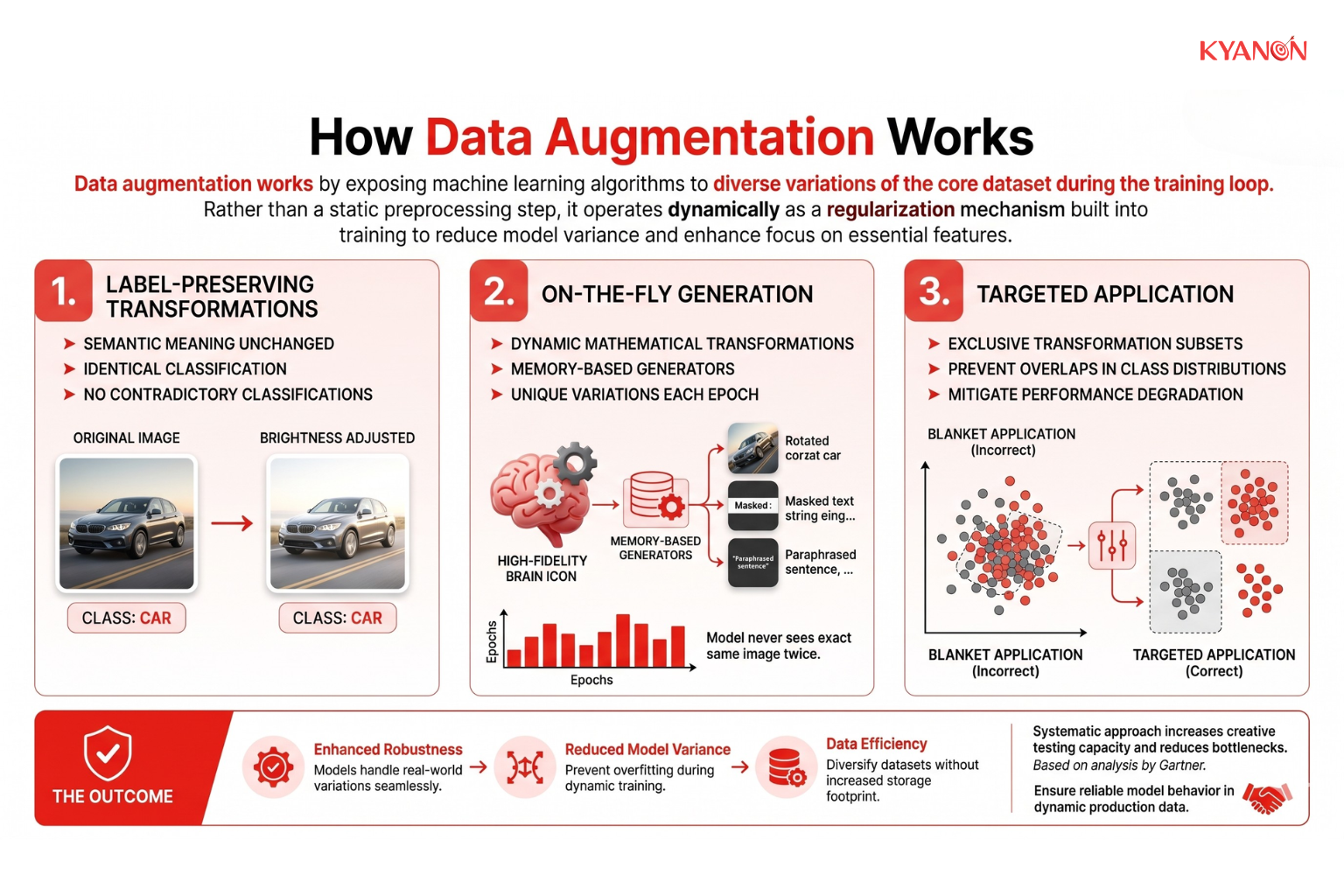
Key Component 1: Label-Preserving Transformations
Transformations alter the physical or semantic view of the data, such as adjusting brightness in an image, while keeping the underlying semantic meaning and label identical. This ensures the algorithm learns valid parameters without being fed contradictory classifications.
Key Component 2: On-the-Fly Generation
Augmentation pipelines typically apply mathematical transformations dynamically via memory-based generators during training. Consequently, the model encounters unique variations in each epoch, meaning it never sees the exact same image twice, while the underlying storage footprint of the dataset remains completely unchanged.
Key Component 3: Targeted Application
Instead of a blanket application across all files, targeted data augmentation applies transformations exclusively to specific subsets of data. Strong augmentation applied uniformly can cause class-level performance degradation by creating artificial overlaps between different class distributions.
Data Augmentation vs Synthetic Data
Both data augmentation and synthetic data generation are designed to improve AI model performance by expanding the effective size and diversity of training datasets. However, they differ significantly in how the additional data is created, the infrastructure required, and the strategic problems they solve.
For enterprise organizations, understanding the distinction is important because the two approaches address different operational and business challenges within AI programs.
|
Dimension |
Data Augmentation | Synthetic Data |
| Origin | Modifies existing real data |
Generated entirely from scratch |
|
Use case |
Preventing overfitting on small datasets | Bridging massive data gaps or edge cases |
| Cost model | OpEx (low compute overhead) |
CapEx (high upfront generation cost) |
|
Storage footprint |
Unchanged (generated in memory) | Expanded (requires physical storage) |
| Risk of bias | Amplifies existing dataset biases |
Introduces new generative artifacts |
When to Consider Data Augmentation
Data augmentation becomes strategically important when enterprise AI initiatives are constrained not by algorithms, but by the quality, diversity, or scalability of available training data.
In production AI environments, models often perform well during controlled testing yet fail to maintain reliability under real-world variability. Data augmentation helps bridge this gap by exposing models to broader operational conditions before deployment.
Organizations should consider implementing data augmentation when the following challenges emerge.
Consider Data Augmentation if:
- Your computer vision models are performing accurately in controlled testing environments but failing to recognize objects under varying lighting or angles in production.
- You are training a deep learning model within a highly specialized domain where acquiring tens of thousands of new, labeled examples is prohibitively expensive or legally restricted.
- Your model exhibits high variance, strictly memorizing the training data but struggling to generalize decisions to new, unseen user inputs.
It may not be the right priority if:
- Your existing dataset is fundamentally flawed, unrepresentative, or lacks the baseline semantic information required to solve the target business problem.
Why Data Augmentation Matters for Enterprise AI
Relying exclusively on manually collected datasets limits an organization’s ability to scale AI initiatives efficiently, economically, and securely. As enterprises expand the use of machine learning across customer experience, commerce, operations, and decision-making systems, the demand for large, diverse, and continuously updated datasets grows significantly. In practice, however, collecting and labeling enough real-world data to support production-grade AI is often slow, expensive, and operationally difficult.
Enterprise AI systems often struggle in production due to real-world variability. Models optimized for ideal conditions, such as stable lighting in computer vision or structured queries in NLP, frequently fail when encountering inconsistent warehouse illumination or diverse regional language patterns.
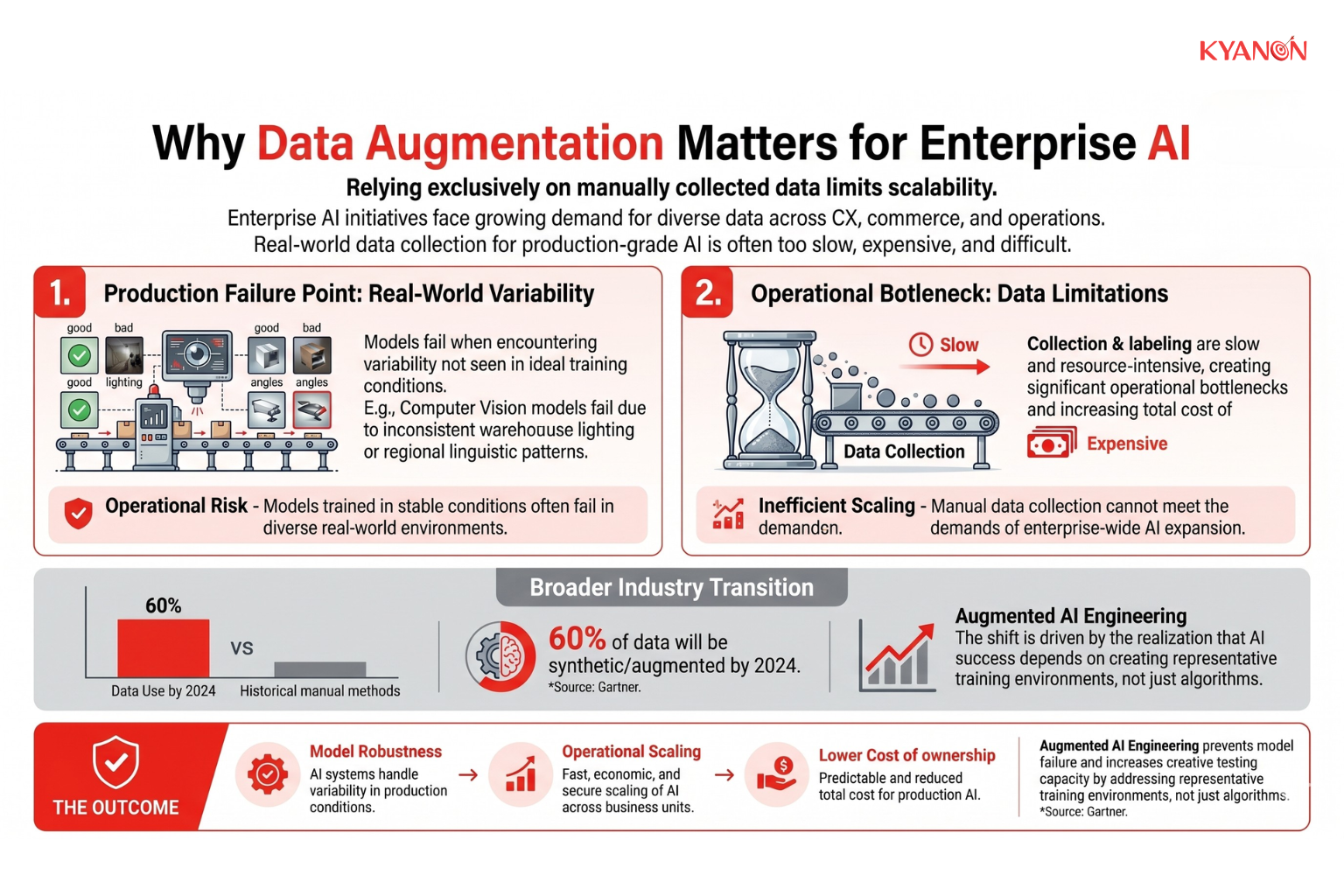
According to Gartner, by 2024, 60% of the data used for AI and analytics projects would be synthetically generated or augmented, reflecting a broader industry transition away from traditional data collection approaches toward more scalable AI engineering practices. This shift is driven by the growing recognition that enterprise AI success depends not only on algorithms, but also on the ability to create sufficiently diverse and representative training environments.
Common Misconceptions
Misconception 1: “Data augmentation increases the total amount of training data we own.”
Reality: While creating new samples on the fly, data augmentation does not increase the diversity or information content of the original real-world data. It functions strictly as a regularization technique to create variations, not as a substitute for collecting inherently representative data.
Misconception 2: “Applying more augmentation techniques will always lead to better model accuracy.”
Reality: Over-augmentation can destroy essential features of the data, causing the model to learn incorrect patterns. Inappropriate transformations introduce noise that does not exist in the real world, leading to a phenomenon known as data augmentation bias.
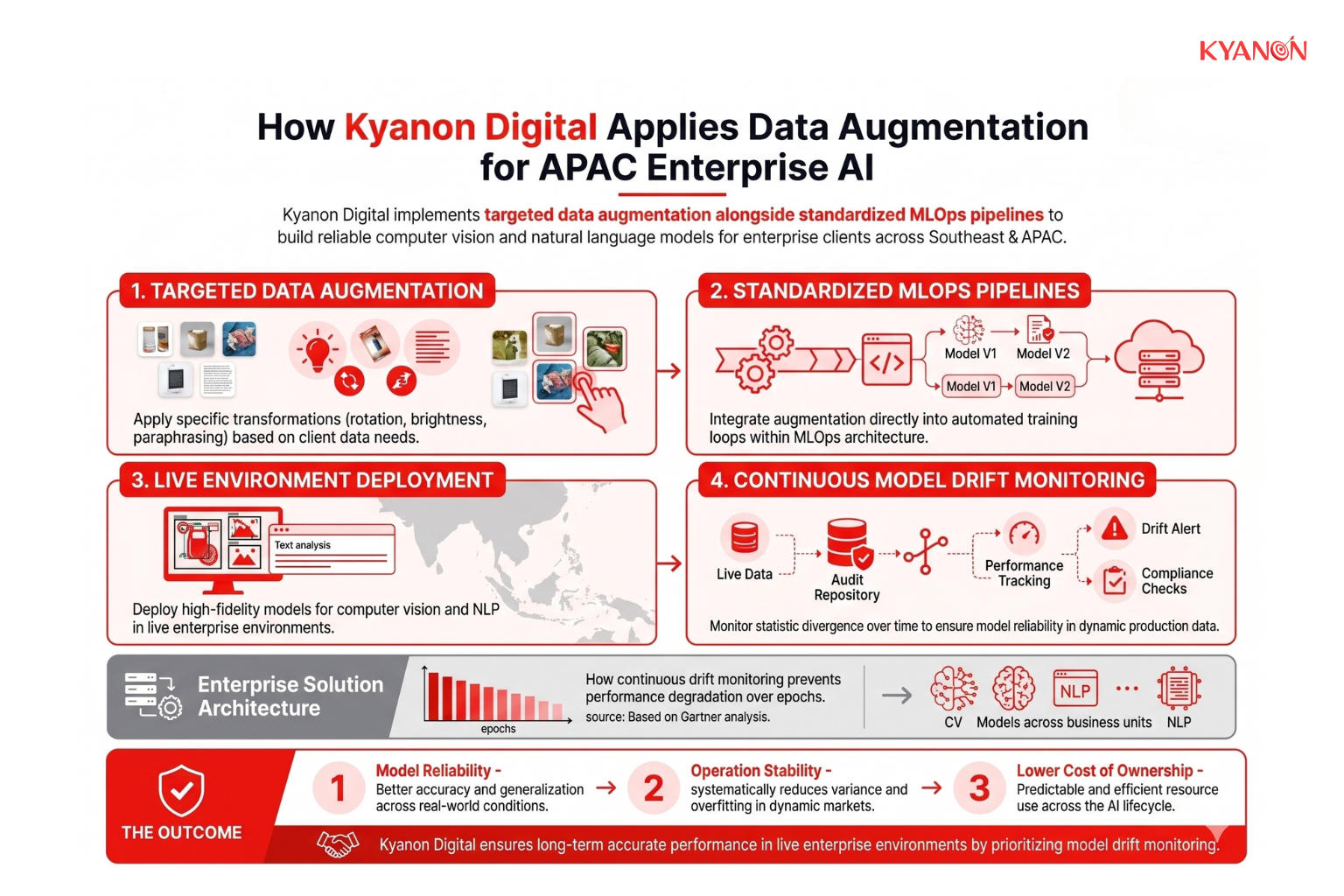
How Kyanon Digital Applies Data Augmentation
Kyanon Digital implements targeted data augmentation alongside standardized MLOps pipelines to build reliable computer vision and natural language models for enterprise clients across Southeast Asia and APAC. Recognizing that augmented models can still face distribution shifts in live environments, Kyanon Digital includes model drift monitoring as a standard component of enterprise AI solutions to ensure models remain accurate in production over time.
→ Explore our AI Development services.







")




 Create project brief with AI
Create project brief with AI