What is Deep Learning?
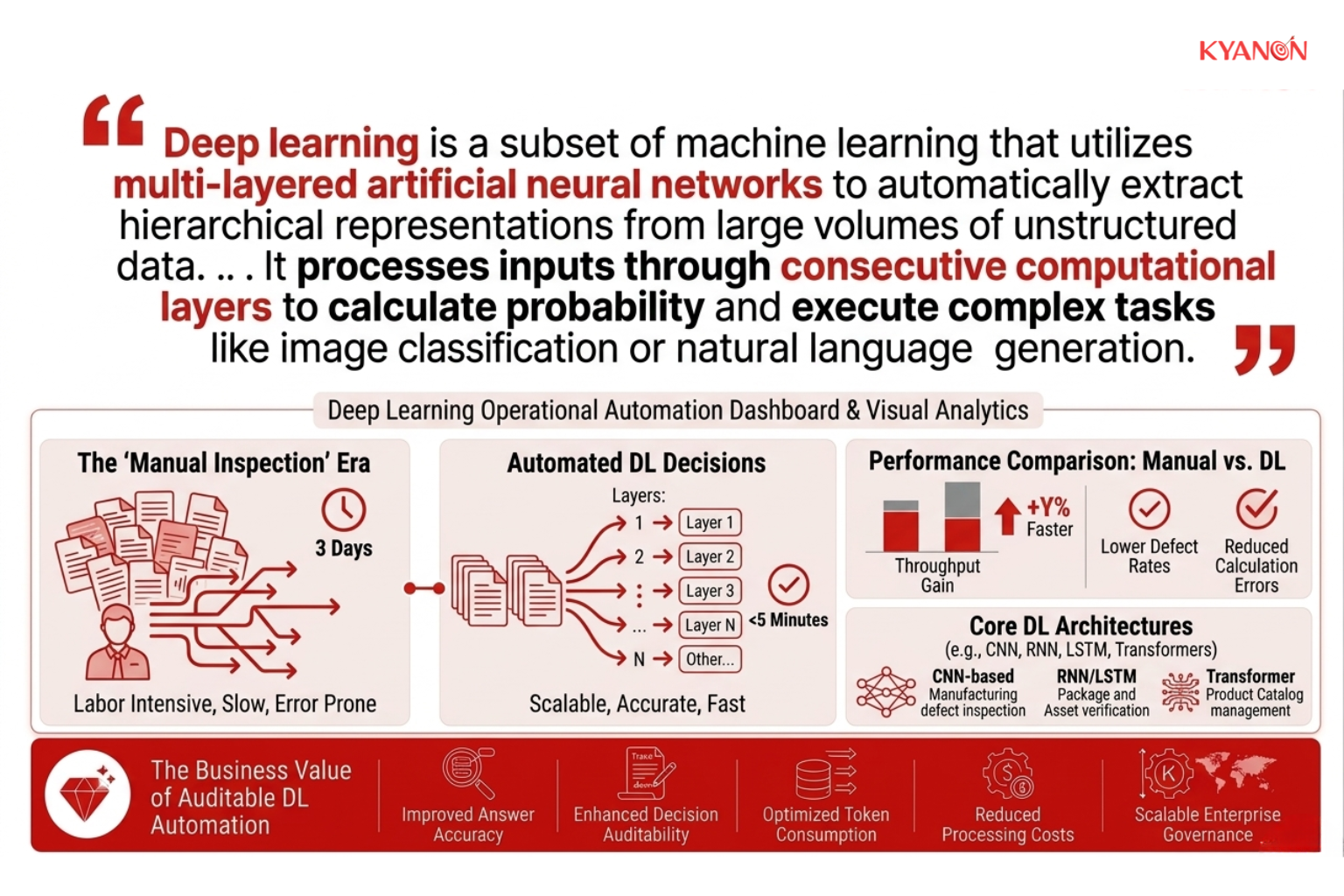
Deep learning is a subset of machine learning that utilizes multi-layered artificial neural networks to automatically extract hierarchical representations from large volumes of unstructured data. It processes inputs through consecutive computational layers to calculate probability and execute complex tasks like image classification or natural language generation.
Core Network Architectures
Different deep learning network structures are engineered to handle specific data formats.
- Convolutional Neural Networks (CNNs): Layered structures that use mathematical convolutions to extract spatial features, making them the standard for computer vision tasks.
- Recurrent Neural Networks (RNNs & LSTMs): Networks designed with internal feedback loops to process sequential data, commonly used for time-series forecasting and speech recognition.
- Transformers: Modern architectures utilizing self-attention mechanisms to process entire data sequences simultaneously, serving as the core engine behind Large Language Models (LLMs).
How Deep Learning Works
Deep learning systems function by passing input data through interconnected nodes called artificial neurons, progressively transforming raw information into abstract mathematical representations to make final predictions. By processing errors iteratively, the system continuously adjusts its internal logic without requiring engineers to manually define individual features.
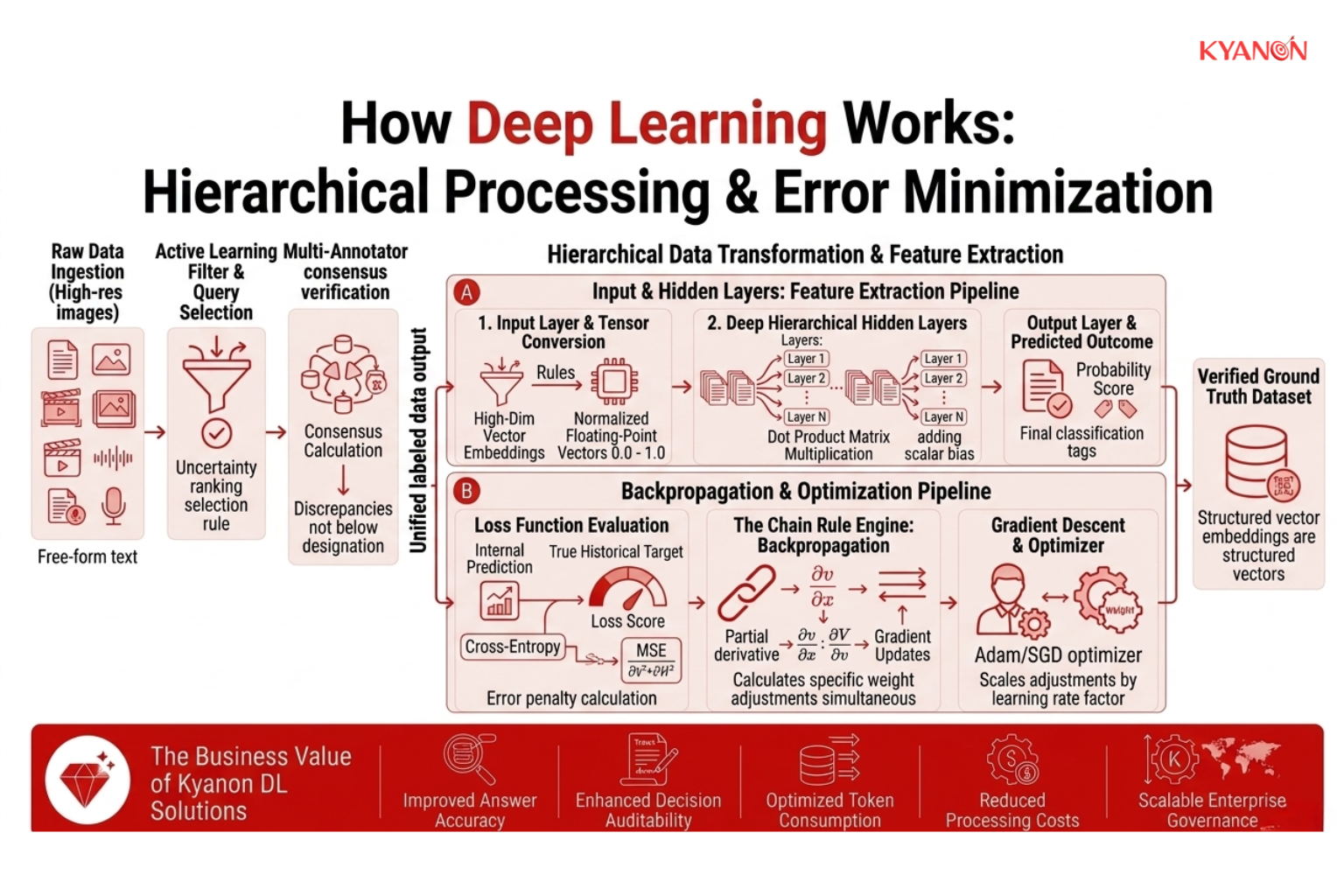
Key Component 1: Input Layer and Tensor Conversion
The initial layer ingests unstructured raw data, such as high-resolution images or free-form text, and converts it into multidimensional mathematical arrays known as tensors. This numerical standardization is strictly required for subsequent algorithmic processing steps.
- Dimensional Formatting: Data points are mapped to precise geometric ranks. For example, a color image is converted into a 3D tensor representing height, width, and color channels (RGB), while a batch of images forms a 4D tensor.
- Feature Normalization: Pixel integers ranging from 0–255 are scaled into normalized floating-point vectors between 0.0 and 1.0. This prevents massive variable swings from destabilizing early network computations.
Key Component 2: Hidden Layers and Feature Extraction
Multiple intermediate computational layers apply mathematical weights and non-linear activation functions to detect increasingly complex patterns. For example, in visual processing, early layers detect basic edges while deeper layers map those edges into complete object recognition.
- Dot Product Matrix Multiplication: Each neuron computes the dot product of the input vector and its internal weight matrix, then adds a scalar bias value.
- Non-Linear Mapping: The output of this matrix multiplication is passed through non-linear activation functions like ReLU (Rectified Linear Unit) or GeLU. Without these functions, the entire deep network would collapse into a single, less-capable linear regression model.
- Hierarchical Abstraction: Early layers capture low-level local features (lines, gradients). Mid-layers group these into textures and shapes. Final hidden layers map these shapes into semantic semantic concepts (faces, text, objects).
Key Component 3: Backpropagation and Optimization
The algorithm calculates the error margin between its internal prediction and the true historical target outcome. It then utilizes mathematical optimization to update its internal weights across all layers simultaneously, minimizing error rates for future predictions.
- Loss Function Evaluation: The network passes its final prediction through a loss function, such as Cross-Entropy Loss for classification or Mean Squared Error (MSE) for regression, to output a precise numerical error penalty.
- The Chain Rule Engine: Backpropagation uses the calculus chain rule to calculate the partial derivative of the loss function with respect to every single internal weight in the network.
- Gradient Descent Updates: An optimizer algorithm (like Adam or SGD) utilizes these calculated gradients to shift the network’s weights in the exact mathematical direction that lowers the overall error, scaling the adjustments by a precise factor called the learning rate.
Deep Learning vs Machine Learning
Both methodologies train mathematical models to identify data patterns, but they differ fundamentally in feature engineering requirements and architectural complexity.
|
Dimension |
Deep Learning | Traditional Machine Learning |
| Feature engineering | Automated by the neural network |
Manual creation and selection required |
|
Data dependency |
Demands exceptionally large datasets | Functions efficiently on smaller datasets |
| Hardware requirements | High (requires GPUs/TPUs for training) |
Low to moderate (standard CPUs suffice) |
|
Execution transparency |
Low (complex internal matrix calculations) | High (easier to trace decision logic) |
| Best for | Unstructured data (images, video, text) |
Structured tabular data (CSV, SQL databases) |
When to Consider Deep Learning
Organizations should strategically transition to deep learning architectures when traditional statistical models hit an asymptotic performance ceiling, or when the data footprint becomes overwhelmingly unstructured.
Consider Deep Learning if:
- Your operational team needs to automate the extraction of specific entities, intents, and sentiments from thousands of unstructured customer support transcripts or emails daily.
- Your manufacturing facility requires continuous visual quality inspection where defect variations are too complex for rigid, rule-based machine vision systems to identify consistently.
- You are developing enterprise generative AI applications that inherently require processing billions of parameters to synthesize new content.
It may not be the right priority if:
- Your primary business objective is forecasting next quarter’s inventory demand based on structured, historical spreadsheets, which a simpler regression or tree-based model handles with lower compute costs and higher transparency.
- Your engineering team faces a strict “Right to Explanation” legal framework (such as certain strict GDPR or financial compliance audits), where every predictive output must be traceably proven through explicit logical steps.
Your target deployment environment is highly constrained by hardware form factors, edge computing power, or battery capacity, where heavy deep learning model weights cannot execute within millisecond latency budgets without expensive quantization.
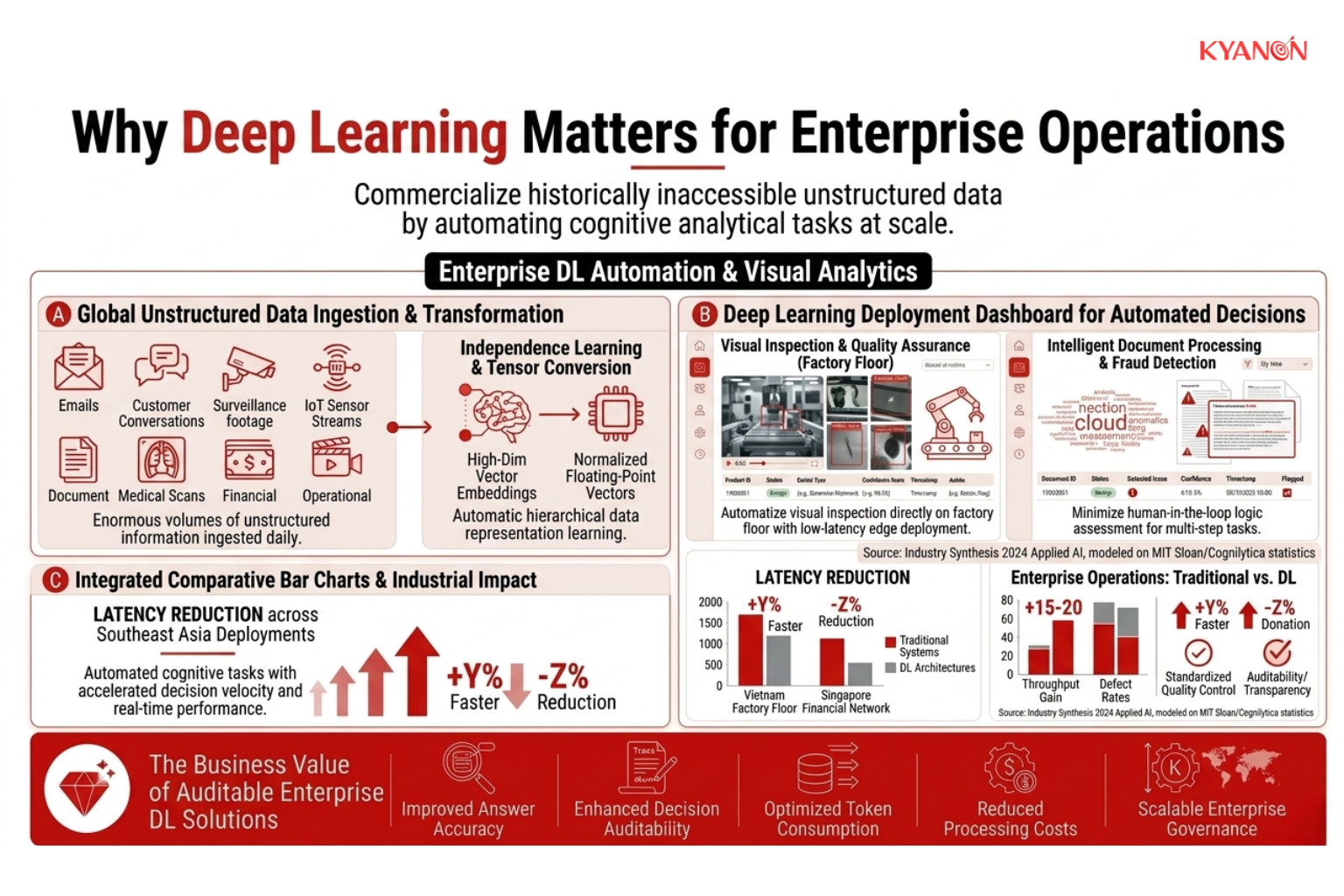
Why Deep Learning Matters for Enterprise Operations
Deep learning enables organizations to commercialize historically inaccessible unstructured data by automating cognitive analytical tasks at a scale impossible for human operators. Unlike traditional machine learning systems that rely heavily on manual feature engineering, deep learning architectures can independently learn hierarchical data representations from massive datasets, enabling more adaptive, accurate, and context-aware decision-making.
This capability is particularly important because modern enterprises generate enormous volumes of unstructured information every day, including emails, customer conversations, surveillance footage, IoT sensor streams, documents, medical scans, financial transactions, and operational video feeds. Traditional rule-based systems struggle to process these datasets efficiently due to their complexity, variability, and lack of predefined structure.
Deep learning models solve this challenge by identifying latent patterns, contextual relationships, and semantic dependencies within raw data. As a result, enterprises can automate high-volume analytical tasks that previously required substantial human intervention, such as:
- Visual inspection and quality assurance
- Fraud detection and anomaly recognition
- Predictive maintenance
- Intelligent document processing
- Customer sentiment analysis
- Real-time recommendation systems
- Supply chain forecasting
- Conversational AI and virtual assistants
Common Misconceptions
Misconception 1: “Deep learning models are exact replicas of the human brain and learn like a human child.”
Reality: While loosely inspired by neurobiology, deep learning systems are strictly mathematical constructs designed to optimize statistical loss functions. They lack biological realism, common-sense reasoning, and require specific, highly curated datasets to learn, unlike humans who learn through broad environmental context.
Misconception 2: “A deep learning model is a complete black box that engineers cannot understand or debug.”
Reality: Although architecturally complex, these networks are interpretable using specialized Explainable AI (XAI) frameworks. By applying specific mathematical mapping techniques, engineers can trace exactly which input variables most heavily influenced the final algorithmic decision.
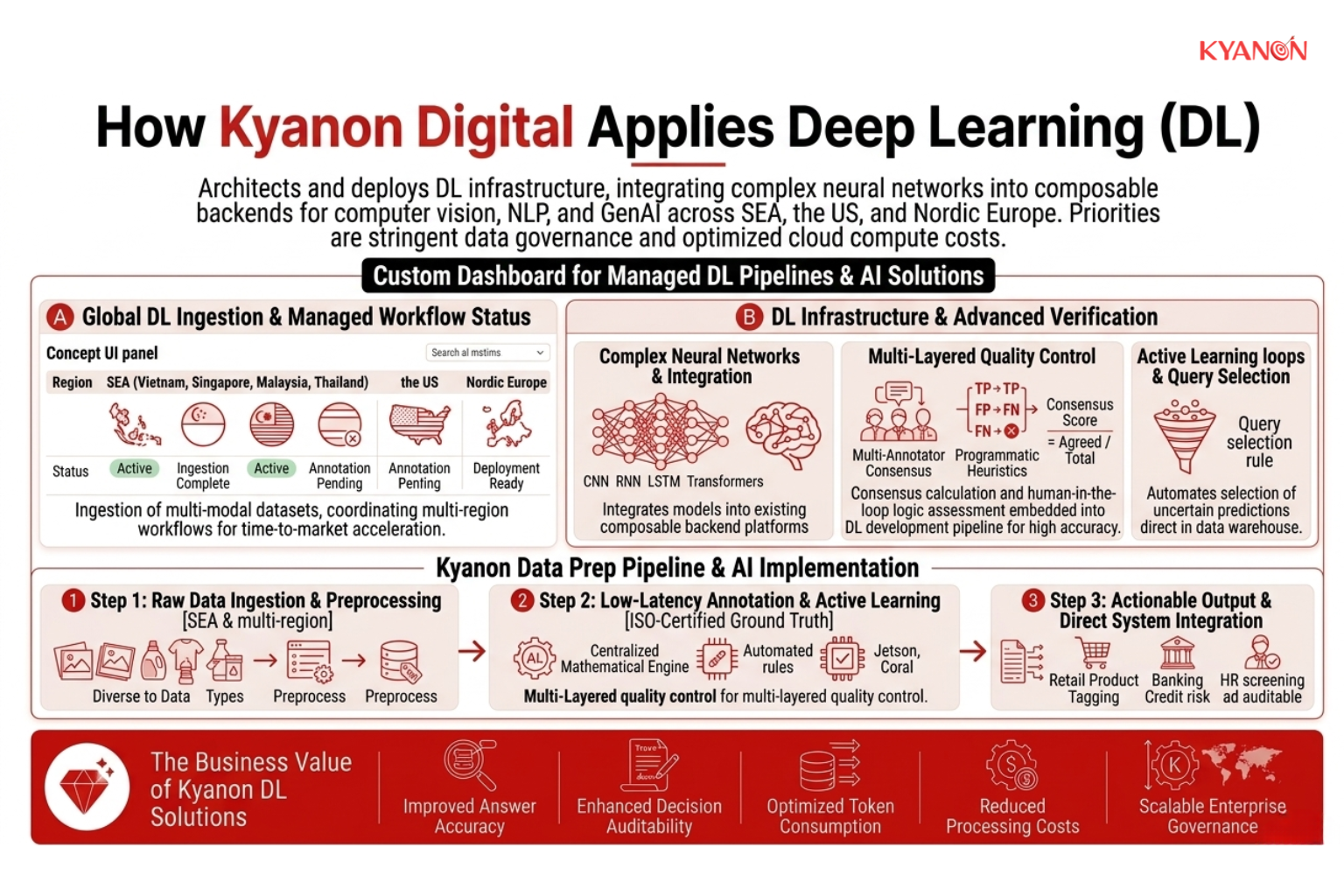
How Kyanon Digital Applies Deep Learning
Kyanon Digital architects and deploys deep learning infrastructure using production-grade frameworks for enterprise clients across Southeast Asia, the US, and Nordic Europe. Our AI engineering teams integrate these complex neural networks into existing composable backend systems to power scalable computer vision, Natural Language Processing (NLP), and GenAI engagements, prioritizing stringent data governance and optimized cloud compute costs.
→ Explore our Machine Learning Software Development services.







")




 Create project brief with AI
Create project brief with AI