What is Ensemble Learning?
Ensemble learning is a machine learning technique that combines predictions from multiple models to produce a more accurate, stable, and reliable outcome than relying on a single model. The approach is based on the principle of the “wisdom of the crowd”: each individual model has its own strengths, weaknesses, and prediction errors, but combining multiple diverse models helps offset those limitations and improve overall performance.
Rather than depending on a single algorithm, ensemble learning aggregates predictions from multiple models through mechanisms such as voting or averaging to generate a final output. By reducing the impact of individual model errors, ensemble methods often achieve higher predictive accuracy, greater robustness, and better generalization to new data.
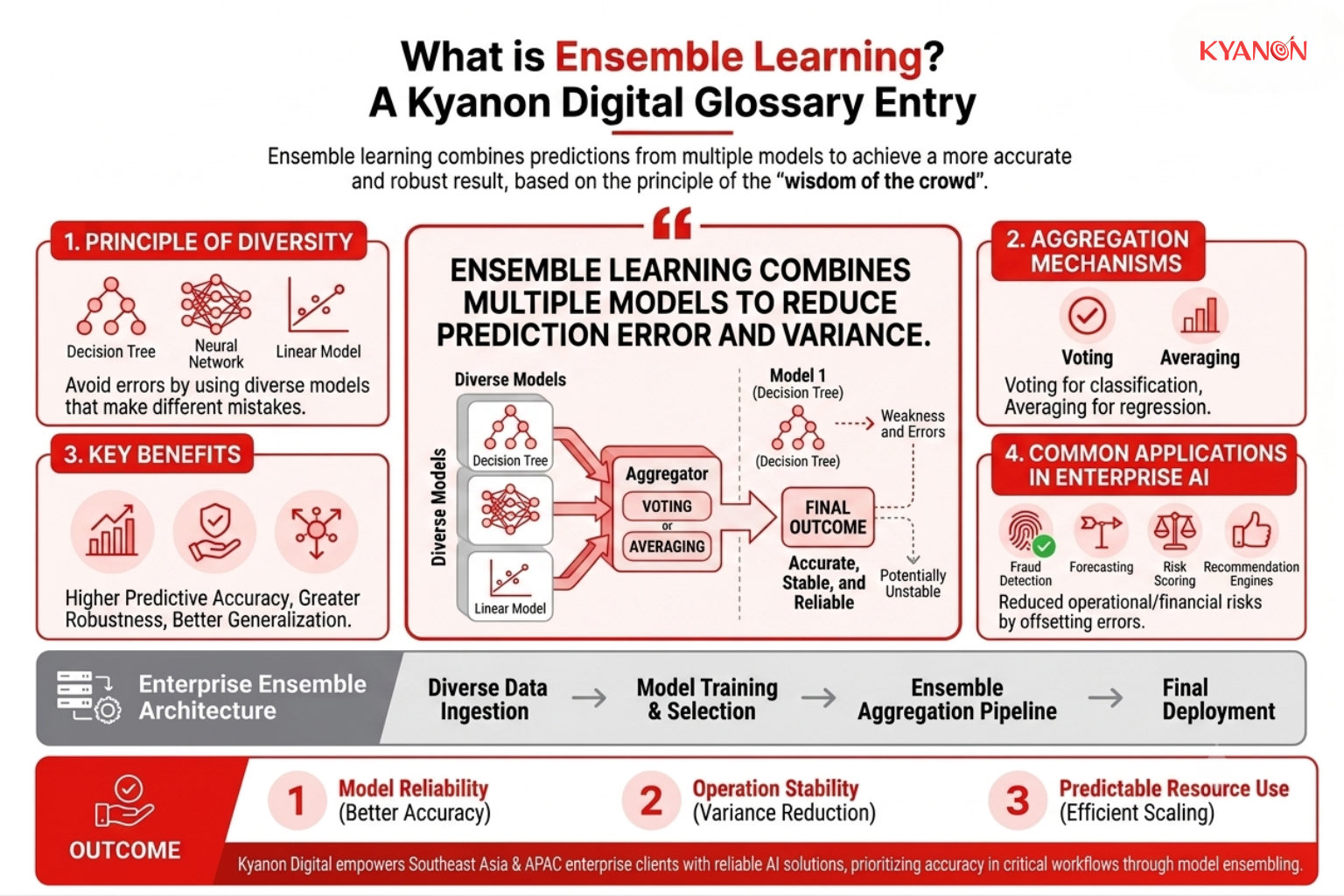
Enterprise AI systems commonly use ensemble learning in fraud detection, forecasting, risk scoring, and recommendation engines where prediction errors can carry significant operational or financial consequences.
How Ensemble Learning Works
Ensemble learning improves prediction quality by aggregating outputs from multiple models that make different types of errors. Instead of depending on one algorithm’s assumptions or weaknesses, the ensemble combines diverse decision patterns to reduce variance, bias, or both.
The workflow typically begins with training multiple base learners using different subsets of data, different feature sets, or entirely different machine learning algorithms. Depending on the ensemble architecture, models may be trained in parallel, sequentially, or independently. Each model generates its own prediction, which is then passed to an aggregation layer responsible for producing a final consensus output.
By combining predictions rather than relying on a single model, ensemble systems can improve accuracy, stability, and generalization while reducing the impact of individual model errors.
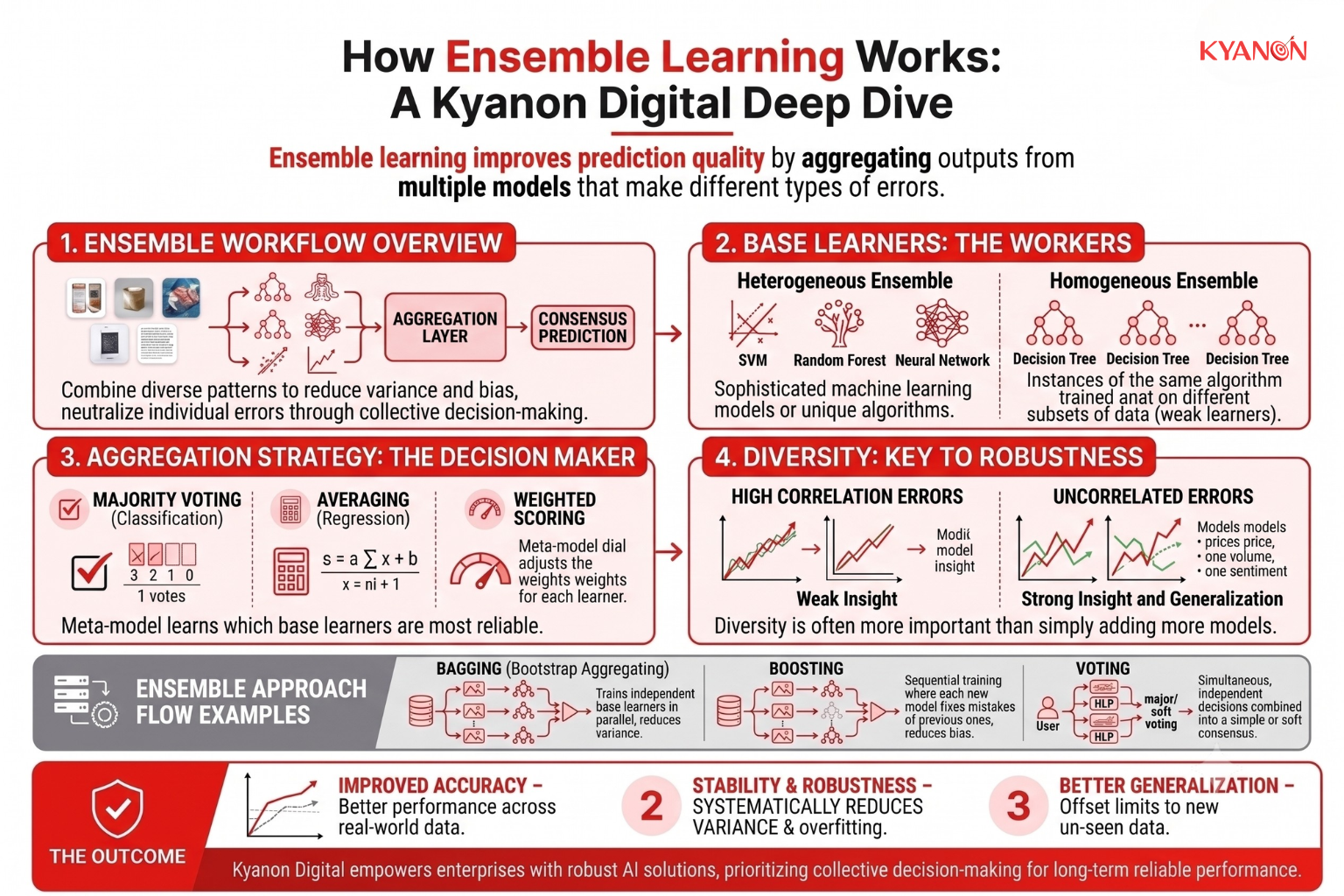
Base Learners
Base learners are the individual models inside the ensemble. These models may be weak learners, such as shallow decision trees, or more sophisticated machine learning models. An ensemble may use multiple instances of the same algorithm trained on different subsets of data (homogeneous ensemble) or combine different algorithms such as decision trees, support vector machines, and neural networks (heterogeneous ensemble).
Each base learner captures different patterns in the data, contributing unique perspectives to the final prediction.
Aggregation Strategy
The aggregation layer combines outputs from all base learners to produce a final prediction. Common aggregation methods include voting, averaging, weighted scoring, or meta-learning approaches that learn how to combine model outputs automatically.
In classification tasks, ensemble systems often use majority voting or probability-based voting. For regression tasks, predictions are commonly averaged. More advanced architectures use a meta-model that learns which base learners are most reliable under different conditions.
The aggregation mechanism determines how much influence each model has on the final prediction and is a key factor in overall ensemble performance.
Diversity Between Models
Ensemble learning performs best when models make uncorrelated errors. Model diversity is often more important than simply adding more models because highly similar learners contribute little additional predictive value.
Diversity can be introduced by training models on different subsets of data, exposing models to different feature groups, or combining entirely different algorithms. These differences encourage models to learn distinct patterns and make different mistakes, allowing the ensemble to neutralize individual errors through collective decision-making.
As a result, diverse ensembles generally deliver more robust and reliable predictions than collections of highly similar models.
Ensemble Learning vs Single Model Machine Learning
Both approaches generate predictions from data, but ensemble learning prioritizes predictive stability and error reduction by combining multiple models instead of relying on one.
|
Dimension |
Ensemble Learning | Single Model Machine Learning |
| Prediction accuracy | Higher in complex tasks |
Dependent on one model |
|
Error resilience |
More tolerant to noise | More sensitive to variance |
| Training complexity | Higher |
Lower |
|
Production explainability |
More difficult | Easier |
| Best for | High-risk predictions |
Simpler use cases |
|
Infrastructure requirement |
Multiple model orchestration | Single deployment pipeline |
| Failure impact | Distributed across models |
Concentrated in one model |
When to Consider Ensemble Learning
Ensemble learning is most relevant when prediction reliability has direct operational, financial, or customer experience impact.
Consider Ensemble Learning if:
- Your fraud detection system generates too many false positives or misses suspicious transactions. Ensemble models can improve detection accuracy by combining multiple risk signals and prediction patterns.
- Your demand forecasting accuracy fluctuates significantly during seasonal peaks or market volatility. Ensembles reduce forecasting variance by balancing different modeling assumptions.
- Your recommendation or pricing engine operates across multiple customer segments with inconsistent behavioral patterns. Ensemble methods can generalize more effectively across diverse datasets.
It may not be the right priority if:
- Your dataset is still limited, highly structured, or early-stage. Simpler models may provide sufficient performance with lower operational overhead and easier explainability.
Why Ensemble Learning Matters for Enterprise AI
Ensemble learning has become a cornerstone of enterprise AI because many business decisions depend on prediction accuracy. In environments where errors can affect revenue, inventory levels, fraud exposure, regulatory compliance, or customer trust, relying on a single model may introduce unnecessary risk. By combining multiple models that approach problems from different perspectives, ensemble learning helps organizations achieve more reliable, stable, and resilient predictions.
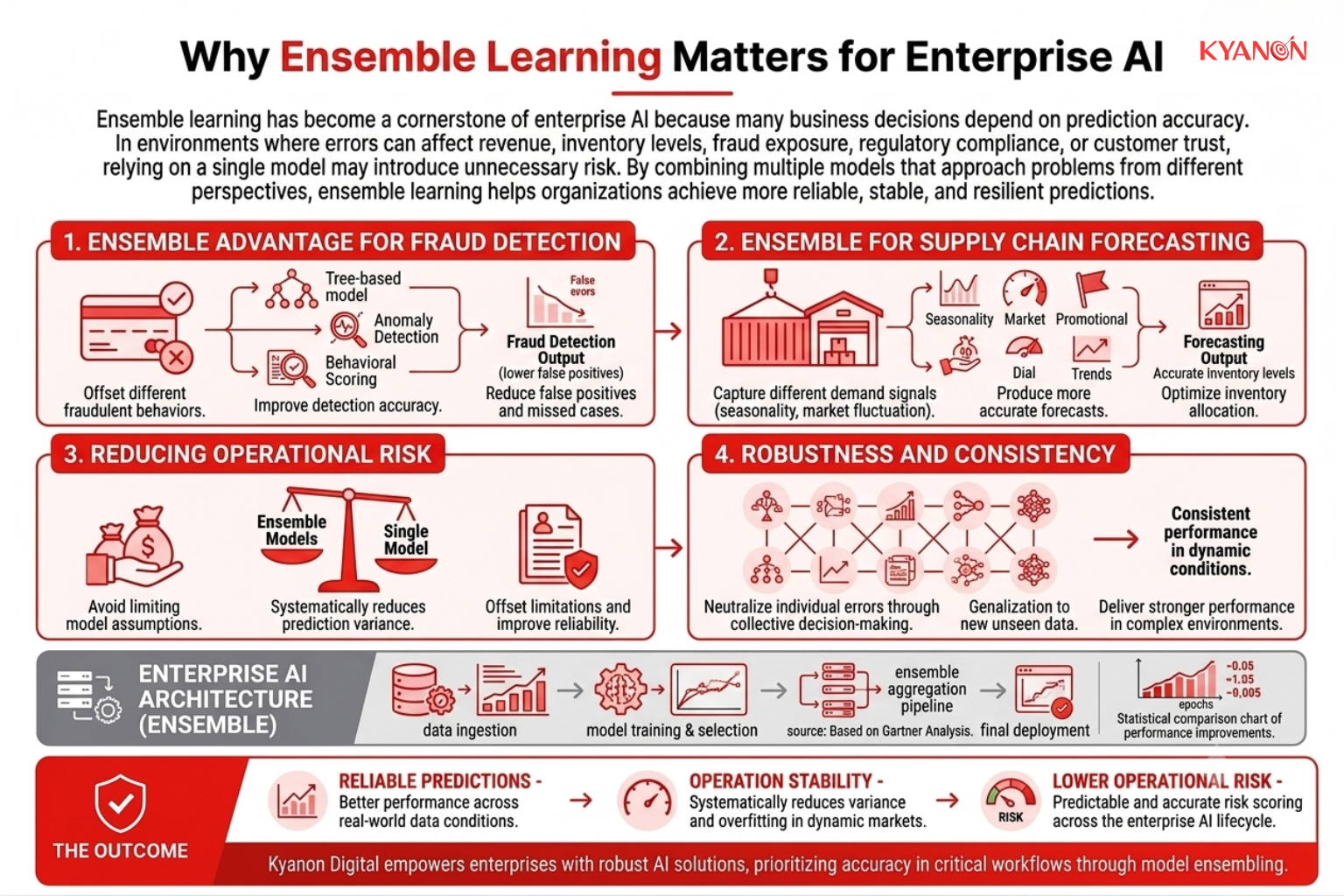
Financial institutions frequently use ensemble learning for fraud detection because no single model can consistently identify every type of fraudulent behavior. By combining tree-based models, anomaly detection systems, and behavioral scoring techniques, organizations can improve detection accuracy while reducing both false positives and missed fraud cases.
Ensemble methods are also widely applied in supply chain forecasting. Different models often excel at capturing different demand signals, such as seasonality, market fluctuations, promotional activity, or short-term purchasing trends. Combining these perspectives produces more accurate forecasts, helping organizations optimize inventory allocation, reduce stock shortages, and minimize excess inventory costs.
More broadly, ensemble learning enables enterprise AI systems to deliver stronger performance in complex, high-stakes environments where robustness and consistency are often as important as raw predictive accuracy.
Common Misconceptions
Enterprise teams often misunderstand ensemble learning because the concept is associated with “adding more models” instead of improving model diversity and decision quality.
More models automatically mean better accuracy
Accuracy gains diminish quickly when additional models produce highly correlated predictions. Model diversity matters more than model quantity in most production environments.
Ensemble models cannot overfit
Ensemble methods reduce variance, but they can still overfit if all base learners learn the same noise patterns. Boosting algorithms such as XGBoost require hyperparameter tuning and early stopping controls.
You must combine completely different algorithms
Many high-performing ensembles use the same model type trained on different data subsets. Random Forests, for example, combine multiple decision trees rather than unrelated algorithms.
Ensemble models are too slow for production systems
Training is usually the most computationally intensive phase. Many ensemble inference pipelines support real-time prediction through parallelization and optimized serving infrastructure.
How Kyanon Digital Applies Ensemble Learning
Kyanon Digital applies ensemble learning architectures in high-stakes enterprise prediction systems such as fraud detection, demand forecasting, recommendation engines, and operational risk scoring. Our implementation approach focuses on balancing prediction accuracy, inference performance, and deployment maintainability using technologies such as XGBoost, Random Forests, gradient boosting pipelines, and scalable MLOps infrastructure for organizations across Southeast Asia and global markets.
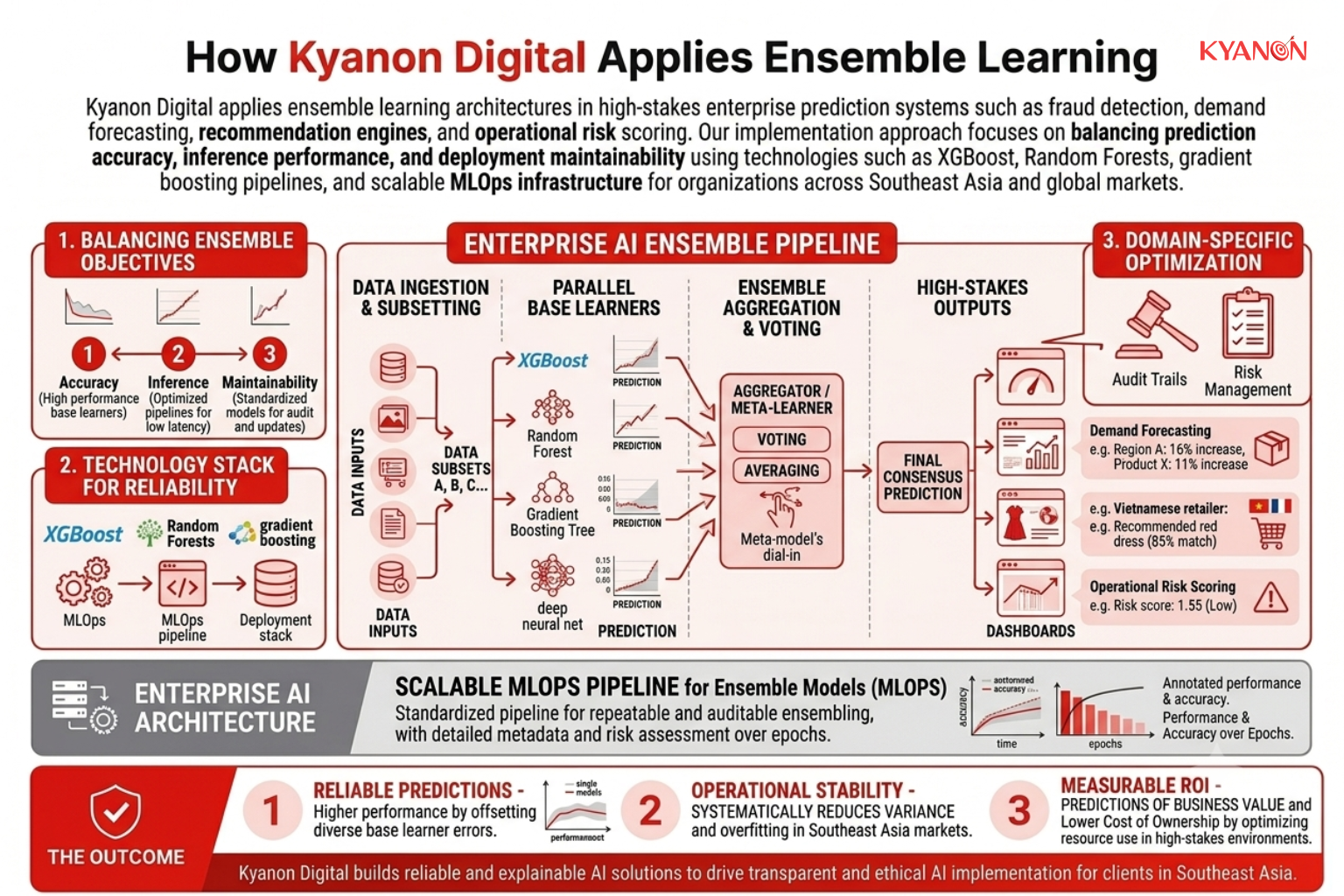
→ Explore our Machine Learning Development services.







")




 Create project brief with AI
Create project brief with AI