

When shipment delays, forecasting errors, or inventory mismatches occur, the problem is often not the AI model itself, but the poor-quality data feeding it. Despite growing investments in automation and analytics, many logistics enterprises still struggle with unreliable operational data at the source.
IBM notes that logistics is entering an AI-intensive phase, with 88% of organizations integrating AI into at least one business function by early 2026. Yet despite more than $2 trillion in AI infrastructure investment, the biggest constraint is no longer algorithm capability, but data integrity. The growing “data quality gap” continues to undermine analytics accuracy and digital transformation ROI. Kyanon Digital helps logistics and supply chain enterprises close this gap by building production-grade data foundations for scalable, reliable AI adoption.
This blog defines the role of “data at the source” as the foundation of effective supply chain performance, analyzes how data quality failures propagate across logistics systems, and outlines the strategic frameworks required to build resilient, data-centric operations, drawing on enterprise implementation approaches delivered by Kyanon Digital.
Key takeaways
- Data quality at the source is the real bottleneck: AI adoption is accelerating, but poor input data, not technology, limits performance because errors start at capture.
- Data errors drive financial and operational loss: Organizations lose 8–12% of revenue because inaccuracies propagate across planning and execution systems.
- Low data trust weakens AI impact: Teams fall back to manual decisions because unreliable data undermines analytics and automation.
- Most errors originate at the edge: Driver apps, scanners, and IoT devices introduce inconsistencies due to human input and fragmented formats.
- Fixing data at the source delivers highest ROI: Validation and automation reduce rework and costs because clean data prevents downstream issues.
- Standardization and ownership are critical enablers: Clear data standards and accountability improve consistency because they address root causes.
Further Reading
- Data Hub & BI Analytics for Vietnam’s Largest Port & Logistics Operator
- Digital Platform Transformation in the Maritime & Logistics Sector
The logistics data quality problem nobody talks about
The current discourse around logistics data analytics often prioritizes the “Big Data” volume and the complexity of predictive models. However, the most significant threat to enterprise performance remains the unglamorous issue of data quality at the source. Organizational AI adoption has moved at historic speeds, with generative AI reaching 53% population adoption in just three years, faster than the personal computer or the internet. Yet, this rapid uptake is occurring on foundations that are frequently fragmented and unreliable.
The technical debt of legacy complexity
The IBM Institute for Business Value predicts a 50% rise in IT spending (2023–2025) due to AI needs and legacy maintenance. “Shadow IT” and silos claim 25% of budgets, creating inconsistent data that obscures operational views. CIOs and CTOs must manage this complexity, as scaling AI tools with “garbage” data from fragmented systems is ineffective.
Poor data quality does not just create technical inefficiencies, it has direct financial consequences. Organizations report millions of dollars in annual losses due to inaccurate, incomplete, or inconsistent data, with impacts often surfacing downstream in the form of missed opportunities, operational inefficiencies, and flawed decision-making. IBM Institute for Business Value reports that over a quarter of organizations estimate losses exceeding $5 million annually due to poor data quality, highlighting how data issues compound silently across operations.
The trust deficit in enterprise systems
The maturity of logistics data analytics is fundamentally limited by the lack of trust in the underlying information. Research from Accenture indicates that only 15% of professionals trust their systems to produce clean, reliable data. This skepticism is justified: roughly 77% of captured logistics data is redundant, obsolete, trivial, or unclassified, leaving only 23% as “good data” available for AI-driven business processes. When 67% of companies do not trust their data enough to derive value from it, the strategic focus must shift from data collection to data curation at the point of origin.
For enterprise leaders, the implication is immediate: before scaling AI, analytics, or automation, organizations must first diagnose where trust breaks down across the data lifecycle. The table below maps the most common data quality constraints to their real operational and strategic impact, highlighting where intervention delivers the highest ROI.
The enterprise data trust gap: Constraints, impacts, and strategic risks (2025–2026)
|
Data quality constraint |
Impact on organizations (2025-2026) |
Strategic risk |
|
Data reliability |
77% of data is “noise” (obsolete or unclassified) | AI models hallucinate and suggest impossible routes. |
| Professional trust | Only 15% trust system outputs |
Decisions default to manual guesswork, neutralizing tech ROI. |
|
Shadow IT |
25% of IT budget spent on unsanctioned tools | Inconsistent reporting across markets and channels. |
| Maintenance burden | 50% increase in IT spend for legacy maintenance |
Capital is diverted from innovation to basic upkeep. |
These constraints are not isolated technical issues, they are signals of where value is leaking. CIOs and Heads of Data should prioritize three moves: (1) quantify the cost of low-trust data in core workflows (planning, routing, billing), (2) enforce data ownership at the point of capture, and (3) standardize inputs before investing further in AI or analytics layers.

Organizations that treat data trust as a first-class operational KPI, rather than a backend IT concern, are the ones that successfully move from fragmented pilots to production-scale AI. Without this shift, even the most advanced systems will continue to operate on unreliable foundations, limiting both ROI and scalability.
Why input quality matters
Input quality is becoming one of the biggest operational risks in modern logistics. As supply chains adopt AI-driven forecasting, autonomous planning, and real-time visibility systems, poor source data no longer creates isolated reporting errors, it amplifies disruptions across the entire logistics network. Inaccurate shipment records, inconsistent inventory feeds, delayed tracking updates, and fragmented operational data can quickly cascade into forecasting failures, stock imbalances, routing inefficiencies, and customer dissatisfaction.
This challenge is becoming even more critical in the “Agentic AI” era, where AI agents increasingly make operational decisions without constant human intervention. If source data is flawed, AI systems do not simply inherit those errors, they scale them.

Why enterprises must fix data quality at the source
For logistics enterprises, fixing data at the source is significantly more cost-effective than attempting downstream cleanup later in analytics platforms or data lakes. Reliable source data directly improves forecasting accuracy, route optimization, warehouse utilization, and fulfillment efficiency. It also enables “Decision Intelligence,” where organizations can improve decision-making speed by 5 to 10 times through cleaner operational visibility and more trustworthy analytics.
More importantly, trustworthy data becomes the foundation for scalable AI adoption. AI systems do not become reliable simply by scaling models, they become reliable when the operational data feeding them is accurate, structured, and consistently validated.
The operational and financial consequences of poor data quality
Preventing “Garbage in, Garbage out” (GIGO)
The “Garbage In, Garbage Out” principle has become increasingly dangerous in AI-enabled logistics operations. Machine learning systems and autonomous agents often treat ingested data as factual truth, meaning even small inaccuracies can rapidly propagate across forecasting, routing, inventory, and fulfillment systems.
According to IBM, 43% of Chief Operations Officers now rank data quality as a top operational priority. In logistics environments, poor-quality data commonly leads to inaccurate demand forecasting, excess inventory buildup, stock shortages, routing inefficiencies, incorrect ETAs, and expensive expedited shipping costs.
Systemic distrust in operational data also limits AI adoption. Accenture reports that only 15% of professionals fully trust the data generated by their systems, causing many organizations to revert to manual estimations despite substantial investments in automation and analytics.
Operational efficiency and real-world value
Clean data at the source is the catalyst for “Decision Intelligence,” which McKinsey research suggests can improve decision speed by 5 to 10 times. In logistics, this translates to optimal inventory management, accurate route planning, and faster order fulfillment. Organizations that excel in data analytics are 23 times more likely to acquire customers and 6 times more likely to retain them.
For example, during the global volatility of recent years, companies utilizing high-quality predictive models saved between 3% and 8% in costs by rerouting inventory and acting early to minimize excess buildup.
Cost reduction and financial accuracy
Poor data quality is not just an operational issue, it is a material financial risk. Typical organizations lose between 8% and 12% of revenue due to data quality problems, while service-based businesses may incur 40% to 60% higher costs from the labor required to detect and fix errors downstream. Research from SearchLab estimates that, in the U.S. alone, poor data quality costs the economy approximately $3.1 trillion annually, underscoring the systemic scale of the issue.
The economic logic is straightforward: investing in data accuracy at the point of capture is significantly cheaper than absorbing the “rework” costs later in the pipeline. SearchLab data highlights that advanced data integration initiatives have demonstrated an average ROI of up to 295% over three years, driven by reduced manual reconciliation, fewer billing disputes, and more reliable operational workflows.
Improved customer experience and trust
Accenture states that with 61% of consumers demanding same-day or next-day delivery, logistics data accuracy is vital for customer satisfaction. Reliable source data enhances tracking visibility and enables “Decision Intelligence,” which accelerates decision-making speed by 5 to 10 times. Conversely, poor data quality costs organizations 8% to 12% in lost revenue, while service-based firms face 40% to 60% higher downstream labor costs to rectify errors.
When systems generate incorrect ETAs or “ghost” updates, trust erodes quickly, which is significant given that only 15% of professionals trust their systems to produce reliable data. Research highlighted by Open Sky Group indicates that companies using AI to enhance visibility can cut logistics costs by 5% to 20% while improving service levels. Furthermore, advanced data integration initiatives have demonstrated an average ROI of up to 295% over three years, primarily by reducing manual reconciliation and billing disputes. Organizations that prioritize data quality at the source can reduce overall operational risks and costs by up to 60%.
Building a scalable validation and governance framework
Establishing source-level validation and governance across systems like driver apps and IoT devices is a strategic necessity in the Agentic AI era. By ensuring data integrity at the point of capture, organizations can reduce operational costs and risks by up to 60%, accelerate decision-making, and secure meaningful ROI from digital transformation. Transitioning away from fragmented source data to a robust, validated foundation is essential for building the resilient, production-grade supply chains required for scalable AI adoption.
Common data quality issues at source
To fix the source, one must first identify the mechanisms through which data becomes corrupted.
Human error in manual processes
Manual data entry remains a high-risk activity, with baseline error rates averaging 1 mistake in every 300 to 500 inputs. In contrast, automated capture methods, such as linear barcodes or 2D symbologies, dramatically reduce this risk. Data from GS1 Healthcare shows error rates can drop to as low as 1 in 350,000 and, in optimal conditions, as low as 1 in 10.5 million. These “human-centric” errors, ranging from incorrect weights and missing fields in driver apps to misentries during warehouse picking, are small at the point of entry but compound quickly across downstream operations.
Inconsistent data and system friction
Logistics operations span multiple stakeholders, manufacturers, carriers, and retailers, each often working with different data standards and formats. This fragmentation creates inconsistencies, such as mismatched product dimensions between Warehouse Management Systems (WMS) and Transportation Management Systems (TMS). Insights from Bain & Company highlight how even minor data discrepancies can have outsized operational impact.
Outdated data and temporal decay
Logistics data has a short shelf life. Using obsolete supplier information or outdated carrier transit benchmarks leads to systemic failures in demand forecasting and route optimization. Temporal data issues, such as timezone conversion errors or inconsistent delivery timestamps, are especially problematic in global operations.
Lack of ownership and governance gaps
A critical organizational gap is the lack of clear “data ownership.” When IT manages data storage while operational teams handle data entry, accountability for accuracy often falls through the cracks. Insights from Cisco highlight that only 23% of supply chain organizations have a formal AI or data strategy in place, leaving the majority without defined governance frameworks to ensure data quality and consistency.

Where logistics data is actually collected and where it breaks
Data quality begins at the edge of the network. Identifying the physical and digital touchpoints where “logistics data collection” occurs is vital for implementing validation.
Digital forms and driver applications
The mobile application used by a driver is the first point of entry for many critical data points (e.g., proof of delivery, exception codes, fuel usage). If these apps allow free-text fields instead of standardized codes, the data becomes unusable for large-scale logistics data analytics.
Warehouse scanners and automated sorting
In the warehouse, scanners capture SKUs and location data. Errors here often occur due to “context loss”, a scanner captures what an item is, but fails to reliably log where it was placed or who moved it. This leads to a mismatch between physical inventory and the “digital twin” in the system.
IoT sensors and edge devices
IoT devices, including GPS trackers and temperature sensors, generate continuous time-series data. However, these sensors are the largest source of data defects in many solutions. Data Quality Issues (DQIs) such as noise, missing values due to connectivity gaps, and “zero-value” errors often flood the system, requiring sophisticated filtering before any analysis can take place.

How poor source data propagates through the logistics stack
Logistics is a chain of dependencies. A single error at the point of “logistics data collection” creates a “Bullwhip Effect,” where distortions amplify as they move upstream.

The Bullwhip Effect at the TMS Level
At the Transportation Management System (TMS) or Advanced Planning System (APS) layer, the Bullwhip Effect is amplified by data inaccuracies and overcorrection logic. Planning algorithms interpret misreported or delayed data, such as miscalculated demand, as genuine shifts, causing the systems to overreact. Designed to prevent stockouts, these systems trigger disproportionately large replenishment orders and expedited shipments, which quickly distort forecasts, transportation plans, and production schedules.
Behavioral factors like “shortage gaming” intensify this effect as downstream players inflate orders out of supply fears. Cisco research shows these practices can raise bullwhip variability by 6% to 19%, triggering aggressive upstream responses that lead to overproduction and excess inventory.
Financial Level: The crisis of freight settlement
Freight settlement is where data quality issues become a cash flow problem. Fragmented information flows and data mismatches between what was ordered and what was delivered lead to constant disputes.
- Manual Reconciliation: Traditionally, teams spend hours manually reconciling data from different sources.
- Audit Disputes: Inaccurate calculations often result in delayed payments and discrepancies in billing.
- Contract Leakage: Inefficiencies in contract management and manual reviews can erode nearly 9% of annual revenue (Accenture).
Customer Level: Erosion of trust
Poor source data creates inaccurate tracking updates and shipment visibility gaps, causing customers to lose confidence in delivery status information. Missed scans and incorrect logs increase WISMO inquiries, customer service workload, and cancellation risk. Over time, unreliable tracking damages brand trust and directly impacts customer experience and operational costs.
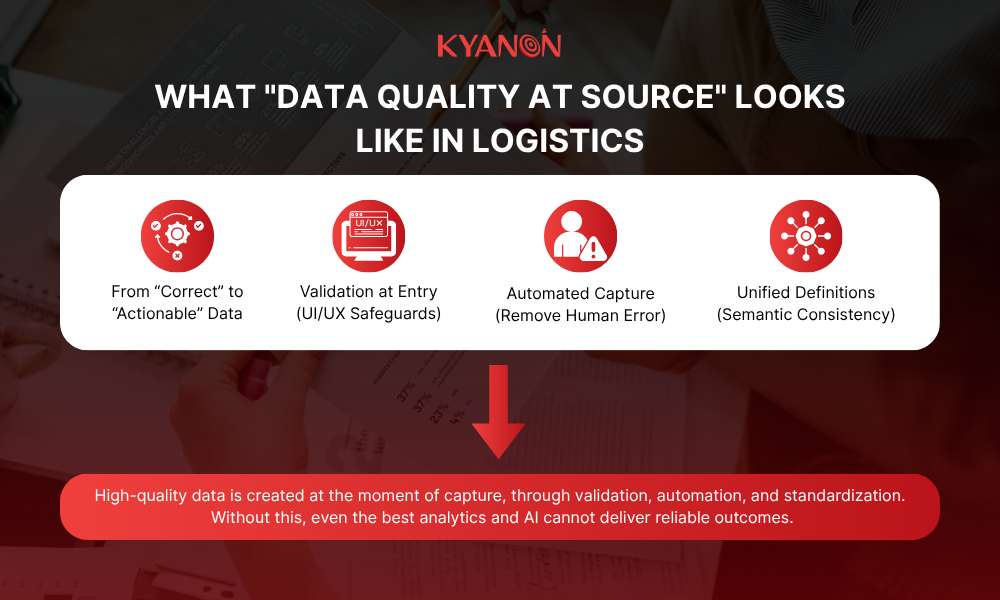
What “Data Quality at Source” looks like in logistics
To achieve high-quality analytics, organizations must redefine what “data quality” means. It is not just about being “correct”; it must be “actionable.”
Validation at entry: The UI/UX safeguard
High-quality data requires “validation at entry”, a critical system logic that proactively prevents impossible or illogical inputs before they contaminate the data pipeline. This safeguard is implemented through several technical mechanisms:
- Mandatory field enforcement: Ensuring critical data points, such as weight, dimensions, or timestamps, are never bypassed.
- Standardized selectors: Using drop-down menus for exception codes and status updates to eliminate the high error rates associated with free-text fields.
- Real-time geofencing: Utilizing GPS data to automatically verify driver locations during proof-of-delivery events, ensuring spatial accuracy.
By embedding these constraints directly into the UI/UX of driver applications and digital forms, organizations can prevent illogical inputs (e.g., a 50,000lb parcel) from ever entering the cloud.
Automated capture: Removing human inconsistency
The ultimate goal of modern logistics is to remove the human element from data entry wherever possible, as manual processes are prone to a baseline error rate of 1 mistake in every 300 to 500 inputs. Transitioning to automated methods significantly enhances data fidelity:
- Digital technologies: The use of RFID, IoT, and OCR technologies eliminates the potential for typos and misentries during picking or sorting.
- Accuracy benchmarks: According to Accenture, automated quality inspection vision systems achieve 99.2% accuracy in defect detection and inventory logging, vastly outperforming the 80% average for manual processes.
Automation not only reduces rework costs but also ensures that the warehouse’s “digital twin” remains synchronized with physical reality, providing the high-fidelity data necessary for autonomous “Agentic AI” systems.
Unified definitions and semantic interoperability
Semantic consistency ensures events carry uniform meaning across systems, resolving conflicts where terms like “Arrived” have different definitions for carriers, warehouses, and customers. By adopting canonical schemas and international GS1 standards, organizations create a shared language that unifies internal data models and ensures external interoperability for more reliable tracking and analytics.
A framework for standardizing logistics data at source
Fixing the source requires a multi-pronged approach that combines standards, incentives, and automation.

Pillar 1: Standardization (GS1 global standards)
GS1 standards create a common data language across the supply chain, improving interoperability and reducing manual errors. Key standards include:
- GTIN: Identifies products across all packaging levels.
- GLN: Identifies companies, warehouses, and delivery locations.
- SSCC: Tracks logistics units such as pallets and parcels.
- Scan4Transport: Enables automated transport data capture through standardized labels.
Pillar 2: Incentivisation and behavioral change management
Improving source-level data quality requires frontline engagement and accountability. Performance-based incentive programs help increase data accuracy and operational consistency. Key approaches include:
- Points & Rewards Systems: Encourages accurate and timely data entry.
- Badges & Leaderboards: Drives engagement through recognition and gamification.
- Operational Scorecards: Tracks data quality performance across teams.
- Recognition-Based Tracking: Reinforces consistent data accuracy behaviors.
Pillar 3: Automation and edge validation
Edge computing enables logistics data to be processed and validated directly at the source, improving speed and reliability. Key benefits include:
- Real-Time Decisioning: Edge AI enables faster routing and operational optimization.
- Anomaly Detection: Detects data errors and sensor failures instantly.
- Offline Resilience: Maintains data collection in low-connectivity environments.
For enterprise leaders, the priority is sequencing. The challenge is not knowing what to implement, but deciding where intervention will unlock the most value fastest. Without this focus, investments in analytics and AI risk sitting on unstable data foundations. The framework below connects each strategic lever to its tangible business impact.
Framework for data quality at source: Strategies, benefits, and ROI impact
|
Strategy |
Operational benefit | ROI benchmark |
| GS1 standardization | Interoperability across 150 countries |
20x fewer pallet errors |
|
Edge AI validation |
Sub-100ms processing latency | 40% reduction in supply chain waste |
| Automated inspection | 99.2% defect detection accuracy |
28% reduction in returns |
|
Gamified entry |
100% accuracy in controlled studies |
40-60% faster operator learning |
The implication is clear: fix the highest-impact failure points first. Standardizing identifiers eliminates cross-system inconsistency, while edge validation prevents bad data from entering the pipeline altogether. Automation should target high-error processes early, with gamification reinforcing accuracy once systems are in place.
At a structural level, edge validation is a prerequisite for autonomy. Without real-time, on-device filtering, organizations inherit latency, higher cloud costs, and unreliable outputs. For Heads of Technology, edge capabilities are not an optimization layer, they are the baseline required to scale Decision Intelligence in real-world operations.
Why do enterprise leaders work with Kyanon Digital for logistics data modernization?
Kyanon Digital helps logistics and supply chain enterprises improve operational visibility by strengthening data quality at the source across warehouse operations, transportation workflows, inventory systems, and partner ecosystems. Rather than treating reporting issues at the dashboard layer, Kyanon Digital focuses on building reliable data capture, validation, and orchestration frameworks that enable accurate downstream analytics, automation, and AI adoption.
With over 500 technology experts across Vietnam, Singapore, Thailand, Australia, and Malaysia, Kyanon Digital delivers enterprise-grade data engineering, AI, and digital transformation services for organizations operating in complex multi-system environments.
Kyanon Digital’s Relevant Tech Stack Capabilities for Logistics Data at Source
|
Area |
Tech Stack | Business Value |
| Data Capture | Python + FastAPI |
Real-time logistics data validation |
|
Data Processing |
Pandas | Clean and standardized operational data |
| AI Validation | TensorFlow / Scikit-learn |
Detects errors and anomalies automatically |
|
Data Platform |
PostgreSQL | Scalable logistics data management |
| Workflow Automation | Apache Airflow |
Automated ETL and system integration |
|
Cloud Infrastructure |
AWS / Azure | Secure and scalable logistics platforms |
| Frontline Apps | React / React Native |
Better warehouse and driver input experience |
|
End-to-End Solution |
Combined Stack |
Connects data capture, AI, automation, and analytics. |
Kyanon Digital supports logistics enterprises through:
- Data quality assessment across operational workflows, warehouse systems, ERP platforms, and third-party logistics environments.
- Data architecture modernization to unify fragmented operational data across supply chain systems.
- Real-time validation and monitoring frameworks that reduce manual errors at the point of data entry.
- AI-ready data foundations supporting forecasting, operational intelligence, and workflow automation initiatives.
- Enterprise governance frameworks ensure consistency, traceability, and scalable data operations across business units.
The following case study illustrates how stronger data quality foundations translate into measurable logistics performance improvements.
Case study: How Kyanon Digital delivered a Data Hub & BI Analytics platform for Vietnam’s largest port & logistics operator
A primary example of how fixing data at the source can transform an enterprise is seen in the work of Kyanon Digital for Vietnam’s largest port and logistics operator.

The challenge: fragmented data and manual reporting
The client, a prominent maritime and logistics corporation, faced massive “cross-market complexity.” Data was scattered across multiple legacy systems, making it impossible to have a central source of truth. Manual reporting was error-prone and slowed down strategic decisions at the C-suite level.
The solution: a centralized AI-powered data hub
Kyanon Digital implemented a comprehensive data transformation project:
- Scalable data hub: Real-time integration of port and logistics data from across the nationwide operation.
- Centralized data catalog: Standardized every data point to ensure governance and consistency.
- AI-powered BI dashboards: Provided real-time visualization of KPIs, allowing for “prescriptive decision-making”.
The impact: Measurable ROI and growth
The results of the project demonstrate the “measured time-to-value” that pragmatist leaders demand:
- Real-time visibility: Provided instant insight into operational and financial performance across all locations.
- Operational efficiency: Dramatically reduced the time required for reporting and eliminated technical bottlenecks.
- Scalability: The infrastructure was built to handle increasing data volumes and user demands as the business grows.
Read More: Data Hub & BI Analytics for Vietnam’s Largest Port & Logistics Operator
Conclusion: Choosing the right partner for the next decade
As logistics moves toward 2030, data quality at the source will become a key competitive advantage. With AI-driven operations and autonomous disruption response accelerating, poor data is no longer just an operational issue, it is a business risk.
For CEOs, CTOs, and Heads of Data, the priority is clear: build reliable data foundations before scaling AI and automation. That means investing in data integration, standardization, and automated validation systems that improve operational accuracy and resilience.
Kyanon Digital has supported enterprises across retail, logistics, and financial services in designing and deploying production-grade data and automation systems, from integration architecture to governance and real-world rollout. If you are evaluating how to operationalize high-quality data at scale, start with a data readiness assessment: identify where errors originate, quantify their cost, and map a phased path to clean, reliable data before committing to full-scale transformation. Contact Kyanon Digital.















")




 Create project brief with AI
Create project brief with AI