What is Uncertainty Quantification?
Uncertainty Quantification (UQ) is a mathematical framework in machine learning that measures and communicates the reliability of a model’s predictions by estimating the degree of uncertainty associated with each output. Rather than producing only a single prediction or confidence score, UQ evaluates how trustworthy a prediction is by representing uncertainty through calibrated probabilities, confidence intervals, or probability distributions.
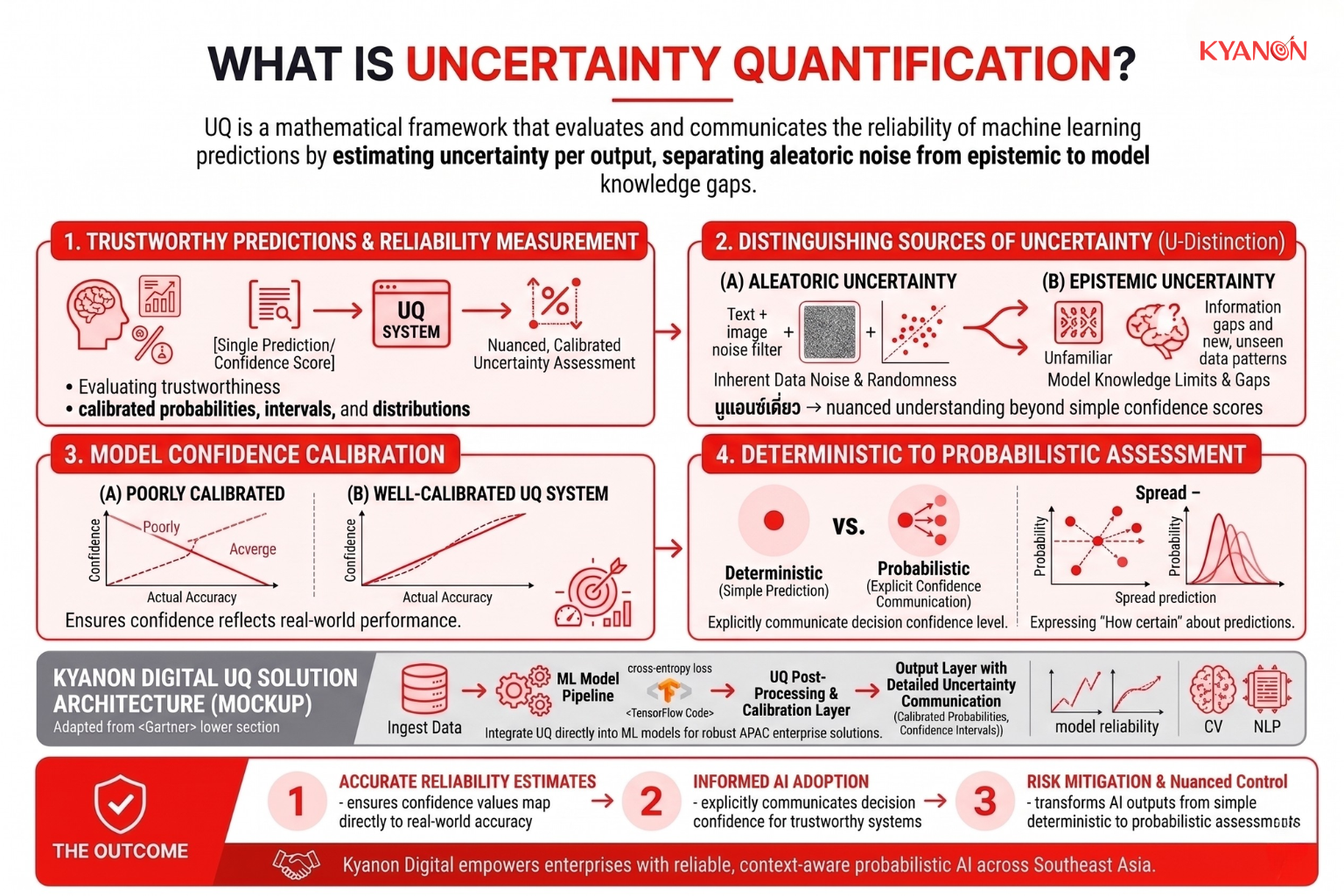
At its core, Uncertainty Quantification distinguishes between different sources of uncertainty. These typically include aleatoric uncertainty, which arises from inherent noise, randomness, or variability within the data itself, and epistemic uncertainty, which results from limitations in the model’s knowledge or exposure to unfamiliar data. By separating these uncertainty types, UQ provides a more nuanced understanding of prediction reliability than traditional confidence scores alone.
The framework is designed to ensure that model confidence accurately reflects real-world performance. A well-calibrated UQ system produces confidence estimates that correspond closely to actual prediction accuracy, enabling machine learning models to express not only what they predict but also how certain they are about those predictions. As a result, Uncertainty Quantification transforms AI outputs from simple deterministic predictions into probabilistic assessments that explicitly communicate the level of confidence associated with each decision.
How Uncertainty Quantification Works
Uncertainty Quantification (UQ) works by augmenting a machine learning model’s prediction process with statistical mechanisms that estimate how confident the model should be in its output. Instead of generating only a single prediction, a UQ-enabled system evaluates multiple sources of uncertainty and produces both a prediction and an associated confidence measure. By quantifying uncertainty alongside accuracy, the system can identify situations where predictions may be unreliable due to unfamiliar inputs, noisy data, or model limitations.

Epistemic Uncertainty Estimation
The first layer measures epistemic uncertainty, which reflects uncertainty arising from the model’s limited knowledge or exposure to unfamiliar data. This type of uncertainty occurs when incoming inputs differ significantly from the examples encountered during training.
To estimate epistemic uncertainty, engineers often use techniques such as Deep Ensembles or Monte Carlo Dropout, which generate multiple predictions for the same input under slightly different model conditions. The system then analyzes the variation among these predictions. When outputs differ substantially, the model interprets the input as potentially unfamiliar or outside its learned domain, indicating a higher level of uncertainty. This approach helps identify situations where the model lacks sufficient knowledge to make a reliable prediction.
Aleatoric Uncertainty Measurement
The second layer measures aleatoric uncertainty, which originates from inherent noise, randomness, or ambiguity within the data itself. Unlike epistemic uncertainty, aleatoric uncertainty cannot be eliminated simply by collecting more training data because it reflects variability that is naturally present in the environment.
Examples include blurry images, sensor degradation, incomplete records, background noise in audio streams, or volatile market conditions. To capture this uncertainty, models are often trained to estimate not only a predicted value but also the expected variance associated with that prediction. This allows the system to quantify how much of the prediction risk is caused by the quality or stability of the input data rather than by gaps in model knowledge.
Output Calibration
Once uncertainty estimates have been generated, the final stage calibrates the model’s confidence scores to ensure they accurately reflect real-world reliability. Raw confidence outputs from machine learning models are often poorly calibrated, meaning a model may express extremely high confidence even when its prediction is incorrect.
Calibration techniques such as Platt Scaling and Isotonic Regression adjust these raw confidence values by comparing them against observed performance on validation data. The result is a confidence score that more closely matches actual prediction accuracy. In a well-calibrated system, predictions assigned a 90% confidence level should be correct approximately 90% of the time. By aligning confidence estimates with real-world outcomes, output calibration transforms uncertainty measurements into reliable indicators of prediction trustworthiness.
Uncertainty Quantification vs Point Estimation
Both Uncertainty Quantification (UQ) and Point Estimation generate predictions from machine learning models, but they differ significantly in how they communicate confidence and manage risk. Point Estimation focuses on producing a single answer, while Uncertainty Quantification provides both a prediction and a measure of how reliable that prediction is. This distinction is especially important in high-stakes environments where incorrect decisions can have significant operational, financial, or safety consequences.
|
Dimension |
Uncertainty Quantification | Point Estimation |
| Output format | Prediction interval or probability distribution |
Single, absolute value |
|
Risk visibility |
High (Explicitly flags out-of-distribution inputs) | Low (Blindly outputs a single answer) |
| Compute overhead | High (Requires ensembling or iterative sampling) |
Low (Requires a single forward pass) |
|
Best for |
Credit risk assessment, logistics demand forecasting, manufacturing quality control | Low-risk product recommendations |
| Handling of novel data | Signals low confidence and requests intervention |
Guesses with undocumented false confidence |
As AI becomes increasingly embedded in critical business operations, understanding not only what a model predicts but also how certain it is has become essential. For this reason, Uncertainty Quantification is increasingly viewed as a foundational capability for enterprise-grade AI systems.
When to Consider Uncertainty Quantification
Consider Uncertainty Quantification if:
- Your machine learning model dictates high-stakes financial, medical, or legal decisions where a false positive carries severe regulatory or physical consequences.
- Your production environment frequently encounters data distributions that differ significantly from the original datasets used during model training.
- Your engineering pipeline requires explicit mathematical thresholds to automatically route low-confidence predictions to a human-in-the-loop for manual review.
It may not be the right priority if:
- Your system handles low-risk, high-volume tasks, such as generic e-commerce content sorting, where the compute overhead of measuring variance outweighs the business cost of an occasional incorrect prediction.
Why Uncertainty Quantification Matters for Enterprise AI
As AI systems move from experimentation into mission-critical business operations, the ability to measure prediction accuracy alone is no longer sufficient. Enterprises must also understand when a model is uncertain, operating outside its area of expertise, or making decisions based on noisy or incomplete data. Uncertainty Quantification (UQ) addresses this challenge by providing a statistical measure of confidence alongside every prediction, enabling organizations to make more informed and risk-aware decisions.
According to a recent McKinsey global AI survey, 51% of organizations using AI reported experiencing at least one negative consequence from AI deployment, and nearly one-third identified AI inaccuracy as a source of those issues. In fact, inaccuracy was the most frequently reported AI-related risk organizations experienced and actively worked to mitigate. This highlights a fundamental enterprise challenge: AI systems often generate predictions even when they lack sufficient confidence to do so reliably.

The importance of uncertainty management is growing as organizations scale AI across more business functions. McKinsey’s 2026 AI Trust Survey found that 74% of organizations identify AI inaccuracy as a highly relevant risk, making it one of the most significant barriers to trusted AI adoption. The same research shows that security and risk concerns remain the leading obstacle to scaling advanced AI systems, particularly autonomous and agentic applications.
These findings reveal a critical reality: enterprise AI success depends not only on generating accurate predictions but also on understanding the limits of those predictions. Traditional machine learning systems often produce confident outputs even when encountering unfamiliar situations. Without visibility into uncertainty levels, organizations risk automating decisions that should instead receive additional scrutiny or human review.
Uncertainty Quantification helps address this challenge by transforming AI from a deterministic prediction engine into a risk-aware decision-support system. Rather than treating every prediction equally, UQ enables organizations to differentiate between highly reliable outputs and predictions generated under ambiguous conditions. This distinction is particularly valuable in regulated industries where decision quality directly affects compliance, customer outcomes, and financial performance.
A practical example can be seen in financial services. A global financial institution integrated uncertainty quantification into its automated loan approval pipeline to measure the epistemic risk associated with borrower profiles that differed significantly from historical training data. When uncertainty exceeded predefined thresholds, applications were automatically routed to human underwriters instead of being processed entirely by the algorithm. This approach reduced the likelihood of incorrect automated decisions while preserving the speed advantages of AI-driven processing for routine cases.
The value of UQ extends beyond finance. In healthcare, it can identify medical images that require specialist review. In manufacturing, it can flag quality inspections affected by poor sensor conditions. In cybersecurity, it can highlight anomalous events that differ from known attack patterns. Across each scenario, uncertainty estimates provide a mechanism for balancing automation efficiency with operational safety.
As enterprises continue investing in AI at scale, trust has become a strategic requirement rather than a technical afterthought. Organizations increasingly recognize that understanding how certain a model is can be just as important as understanding what it predicts. By making uncertainty measurable and actionable, Uncertainty Quantification provides the transparency, governance, and risk controls required to deploy AI responsibly in high-stakes business environments.
Common Misconceptions
A high confidence score from a model means the prediction is highly accurate
The raw probability outputs of standard machine learning architectures, such as the final Softmax layer in a deep neural network, are rarely calibrated indicators of real-world certainty. These models are heavily prone to the overconfidence problem, frequently assigning a 99% score to completely out-of-distribution inputs. Converting raw scores into true probabilities requires a separate post-processing calibration step.
Collecting a larger dataset will eventually eliminate all model uncertainty
Data collection only resolves epistemic uncertainty, which stems from a lack of architectural knowledge regarding a specific data pattern. No volume of additional data will ever eliminate aleatoric uncertainty, which represents the inherent, unpreventable randomness and noise in the physical environment or sensor hardware.
Adding an uncertainty framework will directly increase the model’s prediction accuracy
Uncertainty quantification is strictly a diagnostic safety tool; it does not change the core predictive capacity of a flawed algorithm. Implementing these techniques adds computational overhead to explicitly state how much an engineering team should trust a given output, meaning you spend more compute resources to attain the same baseline accuracy, but with a reliable risk metric attached.
How Kyanon Digital Applies Uncertainty Quantification
Kyanon Digital applies Uncertainty Quantification (UQ) as a critical layer of governance and risk management within enterprise AI architectures, particularly for organizations operating in highly regulated and decision-sensitive industries such as financial services, healthcare, insurance, and manufacturing. Rather than evaluating AI models solely on predictive accuracy, our engineering teams assess both prediction quality and prediction confidence, ensuring that AI-driven decisions are supported by measurable reliability indicators.
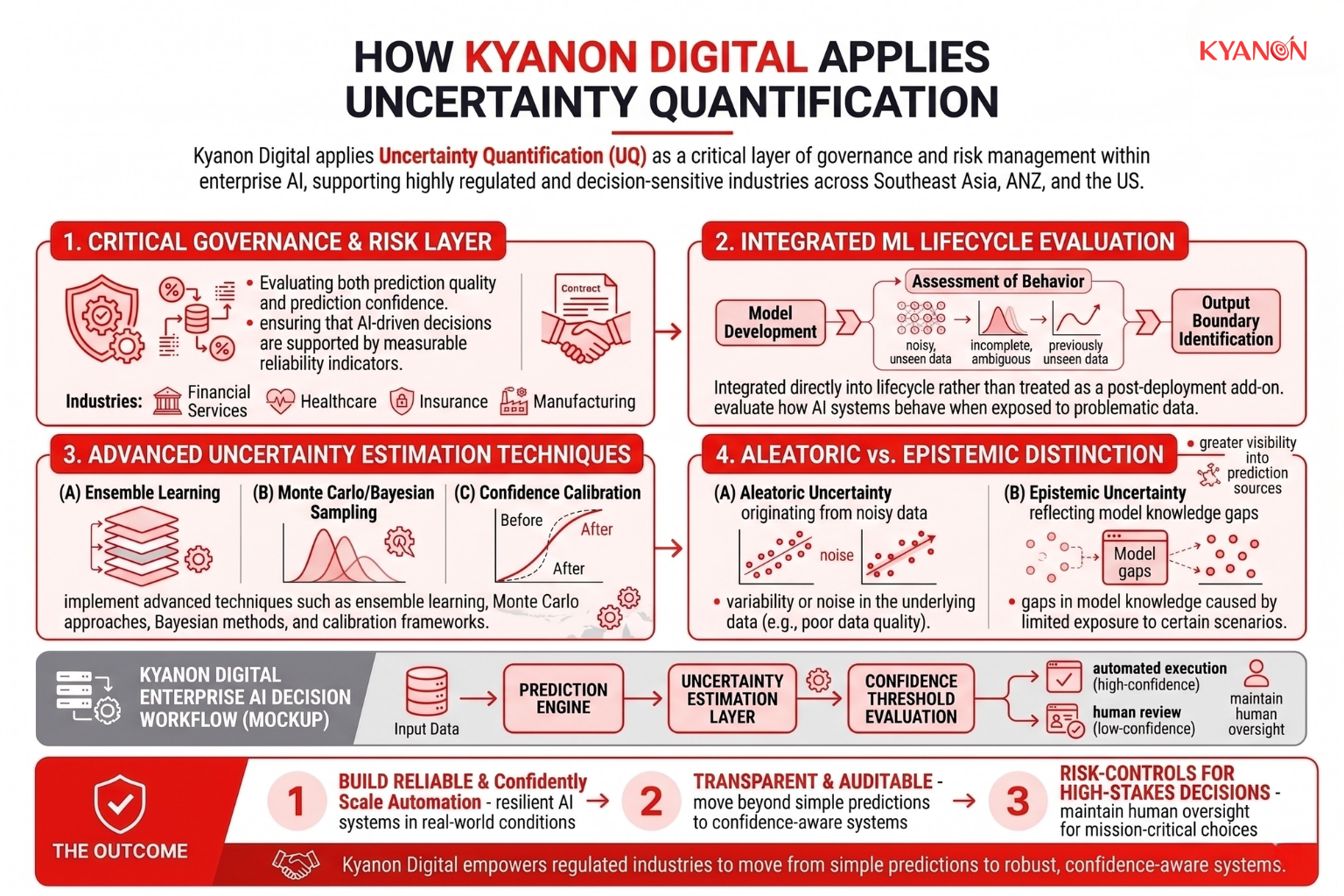
At Kyanon Digital, uncertainty estimation is integrated directly into the machine learning lifecycle rather than being treated as a post-deployment add-on. During model development, our teams evaluate how AI systems behave when exposed to noisy, incomplete, ambiguous, or previously unseen data. This allows organizations to understand not only when a model performs well, but also where its knowledge boundaries begin to emerge.
To achieve this, we implement advanced uncertainty estimation techniques such as ensemble learning, Monte Carlo sampling approaches, Bayesian-inspired methods, and confidence calibration frameworks. These mechanisms help quantify both aleatoric uncertainty, which originates from variability or noise in the underlying data, and epistemic uncertainty, which reflects gaps in model knowledge caused by limited exposure to certain scenarios. By separating these uncertainty sources, enterprise teams gain greater visibility into whether a prediction is affected by poor data quality or by a genuine lack of model understanding.
Across Southeast Asia, ANZ, and the United States, Kyanon Digital helps enterprises move beyond simple prediction-based AI toward confidence-aware decision intelligence. By integrating uncertainty quantification into model development, deployment, and monitoring processes, we enable organizations to build AI systems that are not only accurate, but also transparent, auditable, and resilient in real-world operating conditions. The result is enterprise AI that can scale automation confidently while maintaining the human oversight and risk controls required for high-stakes business decisions.
→ Explore our Machine Learning Development services.







")




 Create project brief with AI
Create project brief with AI